协同滤波 Collaborative filtering 《推荐系统实践》 第二章
利用用户行为数据
简介:
用户在网站上最简单存在形式就是日志。
原始日志(raw log)------>会话日志(session log)-->展示日志或点击日志
用户行一般分为两种:
1显性反馈:包括用户明确表示对物品喜好的行为(数据量小)
2隐形反馈:网页浏览等(数据量大)


用户行为的统一标准如下:

协同滤波与实验设计:
本文参考《推荐系统实践》这本书,但细节和书中略有不同,因为个人把书中代码组合到一起有些小问题,所以自己小修改了一番,可以运行,与大家分享。
实验数据集:
采用GroupLens提供的MovieLens数据集。下载地址http://www.grouplens.org/node/73。为了提供实验速度,本文采用较小数据集,即m1-100k那个数据集中的u.data文件,其他文件没有用,如果有兴趣,读者可以自己参考readme.
实验数据说明
U.data数据包含4列,分别是 UserID::MovieID::Rating::Time ,本实验关心的是topN推荐,所以只关心用户是否看了某个电影,而不关心用户对电影的评分和看电影的时间。所以取数据前两列。
离线设计如下,将用户行为数据集随机分成M份,取M-1份为训练集,1份为测试集。本文M=8.代码
def SplitData(data,M=8,k=3,seed=1):
test = {}
train = {}
random.seed(seed) for user, item in data:
if random.randint(0,M) ==k:
if user not in test:
test[user]=set()
test[user].add(item)
else:
if user not in train:
train[user]=set()
train[user].add(item)
return train,test
评测指标:
对用户u推荐N个物品(R(u)), 令用户u在测试集喜欢的物品集合为T(u),然后定义
召回率: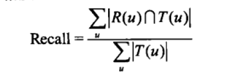
两种召回率代码如下:
def Recall(train,test,N):
hit=0
alls=0
W=UserSimilarity2(train) for user in train.keys():
try:#有可能test有没user看过的item
te_user_item = test[user] recomRank = Recommend(user,train,W,N) for recom_item,w in recomRank:
if recom_item in te_user_item:
hit+=1
alls+=len(te_user_item)
except:
pass; return hit*1.0/alls #ItemFC_recall
def ItemRecall(train,test,N):
hit=0
alls=0
W=ItemSimilarity(train) for user in train.keys():
try:#有可能test有没user看过的item
te_user_item = test[user]
recomRank = ItemRecommendation(user,train,W,N)
#pdb.set_trace()
for recom_item,w in recomRank:
if recom_item in te_user_item:
hit+=1
alls+=len(te_user_item)
except:
pass; return hit*1.0/alls
准确率:
def Precision(train,test,N):
hit=0
alls=0
W=UserSimilarity2(train)
for user in train.keys():
try:#有个能test有没user看过的item
te_user_item = test[user]
recomRank = Recommend(user,train,W,N)
#pdb.set_trace()
for recom_item,w in recomRank:
if recom_item in te_user_item:
hit+=1
alls+=N
except:
pass return hit*1.0/alls def ItemPrecision(train,test,N):
hit=0
alls=0
W=ItemSimilarity(train) for user in train.keys():
try:#有可能test有没user看过的item
te_user_item = test[user]
recomRank = ItemRecommendation(user,train,W,N)
#pdb.set_trace()
for recom_item,w in recomRank:
if recom_item in te_user_item:
hit+=1
alls+=N
except:
pass; return hit*1.0/alls
覆盖率:反应了推荐算法发觉长尾的能力,覆盖率越高,说明推荐算法越能够推荐长尾中的物品给用户。一个简单的定义如下:所有推荐的物品的并集/测试集的所有物品

两种覆盖率代码如下:
def Coverage(train,N):
recommend_items = set()
all_items = set()
W=UserSimilarity2(train)
for user in train.keys():
for item in train[user]:
all_items.add(item) rank =Recommend(user,train,W,N) for item in rank[0]:
recommend_items.add(item) return len(recommend_items)/(len(all_items)*1.0) def ItemCoverage(train,N):
recommend_items = set()
all_items = set()
W=ItemSimilarity(train) for user in train.keys():
for item in train[user]:
all_items.add(item) rank =ItemRecommendation(user,train,W,N) for item in rank[0]:
recommend_items.add(item) return len(recommend_items)/(len(all_items)*1.0)
基于用户的协同滤波User_CF(Collaborative filtering):
算法思路:
1)找到和目标永和兴趣相似的用户集合
2)找到这个集合中的用户喜欢的,且目标用户没有听说过的物品推荐给用户
相似度计算其中N(u)表示用户看过的电影集合。

如下公式度量了UserCF算法中用户u对物品i的感兴趣程度:

基于物品的协同滤波Item_CF
思路步骤:
1)计算物品之间的相似度
2)根据物品的像吸毒和用户的历史行为给用户生成推荐列表
N(i)若代表喜欢物品i的用户数目,则物品i和j相似度可以用下面的公式表示:
USER_CF,ITEM_CF计算物品i,j相似度的代码如下:
def UserSimilarity2(train,flag=1):
#第二中计算W的函数
item_users = dict() #bulid an new empty dicitionary
for u ,item in train.items():
for i in item:
if i not in item_users:
item_users[i] = set() #生成一个集合
item_users[i].add(u) C = dict()
N = dict()#N[u]表示拥护u的项目(看电影)个数 for item ,users in item_users.items(): for u in users:
if u not in N:
N[u]=1#如果用户u不在字典N里面,先创建
else:
N[u]+=1
for v in users :
if u!=v:
if flag==0:#正常情况
if (u,v) not in C:
C[(u,v)]=1
else:
C[(u,v)]+=1
elif flag==1:
if (u,v) not in C:
C[(u,v)]=1/log(1+len(users))
else:
C[(u,v)]+=1/log(1+len(users)) W = dict() for uv in C.keys():
#pdb.set_trace()
u=uv[0]
v=uv[1]
if u not in W:
W[u]=set()
#添加与用户u相关的用户v,第二个意思是他们的权重Wuv
W[u].add((v,C[uv]/sqrt(N[u] * N[v]))) return W def ItemSimilarity(train):
C = dict() #记录 N(i)并N(j)
N = dict() #记录 N(i) i表示喜欢物品i的用户数 for u , items in train.items():
for i in items:
if i not in N:
N[i]=1
else:
N[i]+=1 for j in items:
if i != j:
if (i,j) not in C: C[(i,j)]=1
else:
C[(i,j)]+=1 #calculate finial similarity:
W= dict() for ij ,val in C.items(): i=ij[0]#物品i
j=ij[1]#物品j if i not in W:
W[i]=set()
W[i].add((j,val/sqrt(N[i]*N[j]))) return W
计算用户u对物品j的兴趣公式如下:

userCF ,Item CF 推荐topN代码如下:
def Recommend(user,train,W,N,K=20):
rank = dict()
interacted_items = train[user]
for v,wuv in sorted(W[user], key=lambda x:x[1],reverse=True)[0:K]:
for i in train[v]:#v看过的电影
if i not in interacted_items:#如果电影i不在user已看过的电影里
if i not in rank:
rank[i]=wuv * 1
else:
rank[i]+=wuv * 1
rank=sorted(rank.items(), key = lambda x:x[1],reverse=True)
# rank=[(key,val) for key,val in rank.items()]#字典转换为list
rank=rank[:N]
return rank
def ItemRecommendation(user,train,W,N,K=10):
rank = dict()
user_items =train[user]
for i in user_items:
for j , wij in sorted(W[i], key = lambda x:x[1],reverse =True)[0:K]:
if j not in user_items:
if j not in rank:
rank[j] = wij*1
else:
rank[j]+=wij*1
rank=sorted(rank.items(), key = lambda x:x[1],reverse=True)
rank=rank[:N]
return rank
参数M=8,N=10,k=10时候,输出结果如下:
可以通过调节参数获得其他结果
全部代码如下
ItemCoverage: 0.601796407186
ItemRecall: 0.172728085068
ItemPrecision: 0.208972972973
Recall 0.165132695916
Precision 0.199783783784
Coverage 0.698203592814
# -*- coding: utf-8 -*-
''' Created on 2014��4��16�� @author: Administrator
'''
import random
import pdb
from math import *
import traceback def SplitData(data,M=8,k=3,seed=1):
test = {}
train = {}
random.seed(seed) for user, item in data:
if random.randint(0,M) ==k:
if user not in test:
test[user]=set()
test[user].add(item)
else:
if user not in train:
train[user]=set()
train[user].add(item)
return train,test #USER_FC_recall def Recall(train,test,N):
hit=0
alls=0
W=UserSimilarity2(train) for user in train.keys():
try:#有可能test有没user看过的item
te_user_item = test[user] recomRank = Recommend(user,train,W,N) for recom_item,w in recomRank:
if recom_item in te_user_item:
hit+=1
alls+=len(te_user_item)
except:
pass; return hit*1.0/alls #ItemFC_recall
def ItemRecall(train,test,N):
hit=0
alls=0
W=ItemSimilarity(train) for user in train.keys():
try:#有可能test有没user看过的item
te_user_item = test[user]
recomRank = ItemRecommendation(user,train,W,N)
#pdb.set_trace()
for recom_item,w in recomRank:
if recom_item in te_user_item:
hit+=1
alls+=len(te_user_item)
except:
pass; return hit*1.0/alls # pdb.set_trace() def Precision(train,test,N):
hit=0
alls=0
W=UserSimilarity2(train)
for user in train.keys():
try:#有个能test有没user看过的item
te_user_item = test[user]
recomRank = Recommend(user,train,W,N)
#pdb.set_trace()
for recom_item,w in recomRank:
if recom_item in te_user_item:
hit+=1
alls+=N
except:
pass return hit*1.0/alls def ItemPrecision(train,test,N):
hit=0
alls=0
W=ItemSimilarity(train) for user in train.keys():
try:#有可能test有没user看过的item
te_user_item = test[user]
recomRank = ItemRecommendation(user,train,W,N)
#pdb.set_trace()
for recom_item,w in recomRank:
if recom_item in te_user_item:
hit+=1
alls+=N
except:
pass; return hit*1.0/alls #计算覆盖率
#USER_CF
def Coverage(train,N):
recommend_items = set()
all_items = set()
W=UserSimilarity2(train)
for user in train.keys():
for item in train[user]:
all_items.add(item) rank =Recommend(user,train,W,N) for item in rank[0]:
recommend_items.add(item) return len(recommend_items)/(len(all_items)*1.0) def ItemCoverage(train,N):
recommend_items = set()
all_items = set()
W=ItemSimilarity(train) for user in train.keys():
for item in train[user]:
all_items.add(item) rank =ItemRecommendation(user,train,W,N) for item in rank[0]:
recommend_items.add(item) return len(recommend_items)/(len(all_items)*1.0) def UserSimilarity2(train,flag=1):
#第二中计算W的函数
item_users = dict() #bulid an new empty dicitionary
for u ,item in train.items():
for i in item:
if i not in item_users:
item_users[i] = set() #生成一个集合
item_users[i].add(u) C = dict()
N = dict()#N[u]表示拥护u的项目(看电影)个数 for item ,users in item_users.items(): for u in users:
if u not in N:
N[u]=1#如果用户u不在字典N里面,先创建
else:
N[u]+=1
for v in users :
if u!=v:
if flag==0:#正常情况
if (u,v) not in C:
C[(u,v)]=1
else:
C[(u,v)]+=1
elif flag==1:
if (u,v) not in C:
C[(u,v)]=1/log(1+len(users))
else:
C[(u,v)]+=1/log(1+len(users)) W = dict() for uv in C.keys():
#pdb.set_trace()
u=uv[0]
v=uv[1]
if u not in W:
W[u]=set()
#添加与用户u相关的用户v,第二个意思是他们的权重Wuv
W[u].add((v,C[uv]/sqrt(N[u] * N[v]))) return W def ItemSimilarity(train):
C = dict() #记录 N(i)并N(j)
N = dict() #记录 N(i) i表示喜欢物品i的用户数 for u , items in train.items():
for i in items:
if i not in N:
N[i]=1
else:
N[i]+=1 for j in items:
if i != j:
if (i,j) not in C: C[(i,j)]=1
else:
C[(i,j)]+=1 #calculate finial similarity:
W= dict() for ij ,val in C.items(): i=ij[0]#物品i
j=ij[1]#物品j if i not in W:
W[i]=set()
W[i].add((j,val/sqrt(N[i]*N[j]))) return W #给出要推荐的物品item,(并且存储于rank中)
#rank是一个字典,rank[item]=推荐力度
#返回前N个推荐
def Recommend(user,train,W,N,K=10): rank = dict()
interacted_items = train[user] for v,wuv in sorted(W[user], key=lambda x:x[1],reverse=True)[0:K]: for i in train[v]:#v看过的电影
if i not in interacted_items:#如果电影i不在user已看过的电影里
if i not in rank:
rank[i]=wuv * 1
else:
rank[i]+=wuv * 1 rank=sorted(rank.items(), key = lambda x:x[1],reverse=True) # rank=[(key,val) for key,val in rank.items()]#字典转换为list
rank=rank[:N]
return rank def ItemRecommendation(user,train,W,N,K=10):
rank = dict() user_items =train[user]
for i in user_items:
for j , wij in sorted(W[i], key = lambda x:x[1],reverse =True)[0:K]:
if j not in user_items:
if j not in rank:
rank[j] = wij*1
else:
rank[j]+=wij*1 rank=sorted(rank.items(), key = lambda x:x[1],reverse=True) rank=rank[:N]
return rank f = open('u.data') data=[]#存储数据
for line in f: data.append(line.split('\t')[:2]) train,test=SplitData(data) print 'ItemCoverage: %s' % ItemCoverage(train,10)
print 'ItemRecall: %s' % ItemRecall(train,test,10)
print 'ItemPrecision: %s' % ItemPrecision(train,test,10) print 'Recall %s' % Recall(train,test,10)
print 'Precision %s' %Precision(train,test,10)
print 'Coverage %s' % Coverage(train,10)
总结:
本人愚笨,不太清楚怎么把《推荐系统实践》里面的代码整合在一起,自己改了改,希望可以跟他家分享做个参考吧。PS:数据量还不是很小,运行需要一段时间。
参考书目:推荐系统实践
转载请标注:http://www.cnblogs.com/Dzhouqi/p/3668919.html
协同滤波 Collaborative filtering 《推荐系统实践》 第二章的更多相关文章
- 协同过滤 Collaborative Filtering
协同过滤 collaborative filtering 人以类聚,物以群分 相似度 1. Jaccard 相似度 定义为两个集合的交并比: Jaccard 距离,定义为 1 - J(A, B),衡量 ...
- python从入门到实践 第二章
python变量赋值: python的变量赋值 可以是单引号 也可以是双引号python 变量赋值的时候不能加()的 比如 name = "My Name is GF"变量赋值的时 ...
- 25.推荐---协同过滤(Collaborative Filtering)
协同过滤需要注意的三点: gray sheep(有人喜欢追求特别,协同过滤一般只能从共同的人或物间找相似) shilling attack(水军刷好评导致数据错误,无法带来精确的推荐) cold st ...
- #Python编程从入门到实践#第二章笔记
1.变量 (1)变量名只能包含字母.数字和下划线,不能包含空格 (2)不要将python关键字与函数名作为变量名 (3)简短有描述性,避免使用小写字母l和大写字母O (4)python 始终 ...
- Music Recommendation System with User-based and Item-based Collaborative Filtering Technique(使用基于用户及基于物品的协同过滤技术的音乐推荐系统)【更新】
摘要: 大数据催生了互联网,电子商务,也导致了信息过载.信息过载的问题可以由推荐系统来解决.推荐系统可以提供选择新产品(电影,音乐等)的建议.这篇论文介绍了一个音乐推荐系统,它会根据用户的历史行为和口 ...
- 【RS】Sparse Probabilistic Matrix Factorization by Laplace Distribution for Collaborative Filtering - 基于拉普拉斯分布的稀疏概率矩阵分解协同过滤
[论文标题]Sparse Probabilistic Matrix Factorization by Laplace Distribution for Collaborative Filtering ...
- 从item-base到svd再到rbm,多种Collaborative Filtering(协同过滤算法)从原理到实现
http://blog.csdn.net/dark_scope/article/details/17228643 〇.说明 本文的所有代码均可在 DML 找到,欢迎点星星. 一.引入 推荐系统(主要是 ...
- 基于物品的协同过滤推荐算法——读“Item-Based Collaborative Filtering Recommendation Algorithms” .
ligh@local-host$ ssh-copy-id -i ~/.ssh/id_rsa.pub root@192.168.0.3 基于物品的协同过滤推荐算法--读"Item-Based ...
- 【RS】Factorization Meets the Neighborhood: a Multifaceted Collaborative Filtering Model - 当因式分解遇上邻域:多层面协同过滤模型
[论文标题]Factorization Meets the Neighborhood: a Multifaceted Collaborative Filtering Model (35th-ICM ...
随机推荐
- static方法不能直接访问类内的非static变量和不能调用this,super语句分析
大家都知道在static方法中,不能访问类内非static成员变量和方法.可是原因是什么呢? 这首先要从static方法的特性说起.static方法,即类的静态成员经常被称为"成员变量&qu ...
- 【Go】 http webserver
示例1: package main import ( "fmt" "net/http" "encoding/json" ) var i in ...
- mysql语句大全
转自:http://www.cnblogs.com/yunf/archive/2011/04/12/2013448.html 1.说明:创建数据库 CREATE DATABASE database ...
- JAVA类与对象(二)----类定义基础
类是组成java程序的基本要素,是java中的一种重要的复合数据类型.它封装了一类对象的状态和方法,是这一类对象的原型.一个类的实现包括两个部分:类声明和类体,基本格式: class <clas ...
- .NET核心代码保护策略-隐藏核心程序集
经过之前那个道德指责风波过后也有一段时间没写博客了,当然不是我心怀内疚才这么久不写,纯粹是程序员的通病..怎一个懒字了得,本来想写一些长篇大论反讽一下那些道德高人的.想想还是算了,那样估计会引来新一波 ...
- Recommender Systems移动互联网个性化游戏推荐
对于在线商店,主要关心两方面:1. 提升转化率(将不消费的用户转变为消费用户):2. 提升消费额(已经花钱的人,花更多的强). 对比了6种方法:1. 协同过滤:2. slope one:3. 基于内容 ...
- oracle——表修改语句集合
alter table table_name modify column_name default 0;
- 项目中libevent几个问题
几个问题: .libevent到底用的是select还是iocp,然后是如何突破64限制的 typedef struct fd_set { u_int fd_count; /* how many ar ...
- call,apply,bind方法的总结
why?call,apply,bind干什么的?为什么要学这个? 一般用来指定this的环境,在没有学之前,通常会有这些问题. var a = { user:"追梦子", fn:f ...
- **使用 Git Hook 实现网站的自动部署
http://www.tuicool.com/articles/3QRB7jU 自动化能解放人类的双手,而且更重要的是,因为按照规定的流程来走,也减少了很多误操作的产生.不知道大家平时都是怎么样更新自 ...