让你系统认识flume及安装和使用flume1.5传输数据到hadoop2.2
本文链接:
http://www.aboutyun.com/thread-7949-1-1.html
问题导读:
1.什么是flume?
2.如何安装flume?
3.flume的配置文件与其它软件有什么不同?

一、认识flume
1.flume是什么?
这里简单介绍一下,它是Cloudera的一个产品
2.flume是干什么的?
收集日志的
3.flume如何搜集日志?
我们把flume比作情报人员
(1)搜集信息
(2)获取记忆信息
(3)传递报告间谍信息
flume是怎么完成上面三件事情的,三个组件:
source: 搜集信息
channel:传递信息
sink:存储信息
上面有点简练,详细可以参考Flume内置channel,source,sink三组件介绍
上面我们认识了,flume。
下面我们来安装flume1.5
二、安装flume1.5
1.下载安装包
(1)官网下载
apache-flume-1.5.0-bin.tar.gz
apache-flume-1.5.0-src.tar.gz
(2)百度网盘下载
链接: http://pan.baidu.com/s/1dDip8RZ 密码: 268r
我们走到这一步,我们会想到一个问题,我的电脑是32位的,不知道能否安装?如果我的电脑是64位的,能否安装。之前我们装的hadoop就分为32位和64位,想到这个问题是正常的,但是这里不用担心,因为我们下载的是二进制包,也就是说你32位和64位都可以安装。
2.分别解压:
下载之后,我们看到下面两个包:
(1)上传Linux
上面两个包,可以下载window,然后通过WinSCP,如果不会 新手指导:使用 WinSCP(下载) 上文件到 Linux图文教程
(2)解压包
解压apache-flume-1.5.0-bin.tar.gz,解压到usr文件夹下面
- sudo tar zxvf apache-flume-1.5.0-bin.tar.gz

解压apache-flume-1.5.0-src.tar.gz,解压到usr文件夹下面
- sudo tar zxvf apache-flume-1.5.0-src.tar.gz

(3) src里面文件内容,覆盖解压后bin文件里面的内容
- sudo cp -ri apache-flume-1.5.0-src/* apache-flume-1.5.0-bin

(4)重命名
- mv apache-flume-1.5.0-bin/ flume

3.配置环境变量:
配置环境变量生效
- source /etc/environment
3.建立配置文件
这里面的配置文件还是比较特别的,不同于以往我们安装的软件,我们这里可以自己建立配置文件。
首先我们建立一个 example文件
- vi example
,然后把下面内容,粘帖到里面就可以了,注意不要有乱码,有乱码的话,可以直接创建一个文件,然后上传。方法也有很多,能解决就好。
对于下面红字部分,记得创建文件夹,并且注意他们的权限一致,这个比较简单的,就不在书写了。对于下面的配置项,可以参考flume参考文档,这里面的参数很详细。
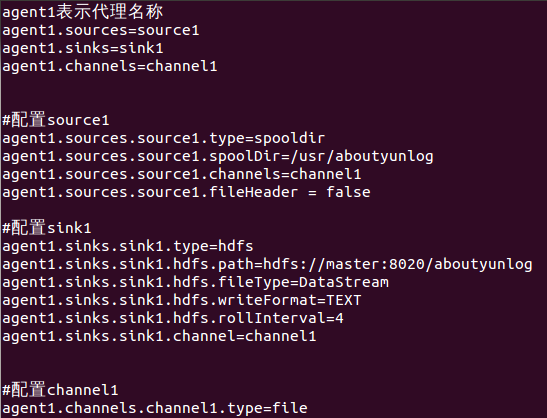
agent1表示代理名称
agent1.sources=source1
agent1.sinks=sink1
agent1.channels=channel1#配置source1
agent1.sources.source1.type=spooldir
agent1.sources.source1.spoolDir=/usr/aboutyunlog
agent1.sources.source1.channels=channel1
agent1.sources.source1.fileHeader = false#配置sink1
agent1.sinks.sink1.type=hdfs
agent1.sinks.sink1.hdfs.path=hdfs://master:8020/aboutyunlog
agent1.sinks.sink1.hdfs.fileType=DataStream
agent1.sinks.sink1.hdfs.writeFormat=TEXT
agent1.sinks.sink1.hdfs.rollInterval=4
agent1.sinks.sink1.channel=channel1#配置channel1
agent1.channels.channel1.type=file
agent1.channels.channel1.checkpointDir=/usr/aboutyun_tmp123
agent1.channels.channel1.dataDirs=/usr/aboutyun_tmp
4.启动flume
flume-ng agent -n agent1 -c conf -f usr/flume/conf/example -Dflume.root.logger=DEBUG,console
上面注意红字部分,是我们自己建立的文件,而对于绿色部分,则是输出调试信息,也可以在配置文件中配置。
5.我们启动flume之后
会看到下面信息,并且信息不停的重复。这个其实是在空文件的时候,监控的信息输出。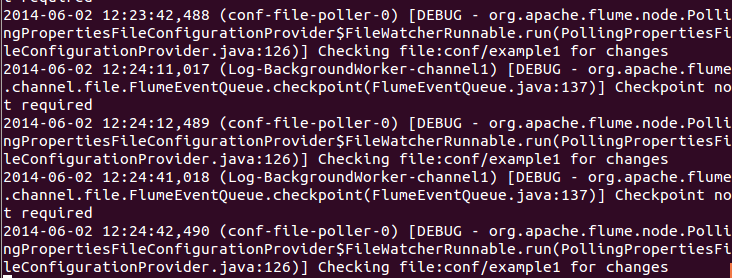
一旦有文件输入,我们会看到下面信息。
注意:这个不要关闭,我们另外开启一个shell,在监控文件夹中放入要上传的文件
比如我们在监控文件夹下,创建一个test1文件,内容如下
这时候flume监控shell,会有相应的如下下面变化
2014-06-02 12:01:04,066 (pool-6-thread-1) [INFO - org.apache.flume.client.avro.ReliableSpoolingFileEventReader.rollCurrentFile(ReliableSpoolingFileEventReader.java:332)] Preparing to move file /usr/aboutyunlog/test1 to /usr/aboutyunlog/test1.COMPLETED
2014-06-02 12:01:04,070 (pool-6-thread-1) [ERROR - org.apache.flume.source.SpoolDirectorySource$SpoolDirectoryRunnable.run(SpoolDirectorySource.java:256)] FATAL: Spool Directory source source1: { spoolDir: /usr/aboutyunlog }: Uncaught exception in SpoolDirectorySource thread. Restart or reconfigure Flume to continue processing.
java.lang.IllegalStateException: File name has been re-used with different files. Spooling assumptions violated for /usr/aboutyunlog/test1.COMPLETED
at org.apache.flume.client.avro.ReliableSpoolingFileEventReader.rollCurrentFile(ReliableSpoolingFileEventReader.java:362)
at org.apache.flume.client.avro.ReliableSpoolingFileEventReader.retireCurrentFile(ReliableSpoolingFileEventReader.java:314)
at org.apache.flume.client.avro.ReliableSpoolingFileEventReader.readEvents(ReliableSpoolingFileEventReader.java:243)
at org.apache.flume.source.SpoolDirectorySource$SpoolDirectoryRunnable.run(SpoolDirectorySource.java:227)
at java.util.concurrent.Executors$RunnableAdapter.call(Executors.java:471)
at java.util.concurrent.FutureTask.runAndReset(FutureTask.java:304)
at java.util.concurrent.ScheduledThreadPoolExecutor$ScheduledFutureTask.access$301(ScheduledThreadPoolExecutor.java:178)
at java.util.concurrent.ScheduledThreadPoolExecutor$ScheduledFutureTask.run(ScheduledThreadPoolExecutor.java:293)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1145)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:615)
at java.lang.Thread.run(Thread.java:744)
2014-06-02 12:01:07,749 (SinkRunner-PollingRunner-DefaultSinkProcessor) [INFO - org.apache.flume.sink.hdfs.HDFSDataStream.configure(HDFSDataStream.java:58)] Serializer = TEXT, UseRawLocalFileSystem = false
2014-06-02 12:01:07,803 (SinkRunner-PollingRunner-DefaultSinkProcessor) [INFO - org.apache.flume.sink.hdfs.BucketWriter.open(BucketWriter.java:261)] Creating hdfs://master:8020/aboutyunlog/FlumeData.1401681667750.tmp
2014-06-02 12:01:07,871 (hdfs-sink1-call-runner-2) [DEBUG - org.apache.flume.sink.hdfs.AbstractHDFSWriter.reflectGetNumCurrentReplicas(AbstractHDFSWriter.java:195)] Using getNumCurrentReplicas--HDFS-826
2014-06-02 12:01:07,871 (hdfs-sink1-call-runner-2) [DEBUG - org.apache.flume.sink.hdfs.AbstractHDFSWriter.reflectGetDefaultReplication(AbstractHDFSWriter.java:223)] Using FileSystem.getDefaultReplication(Path) from HADOOP-8014
2014-06-02 12:01:10,945 (Log-BackgroundWorker-channel1) [INFO - org.apache.flume.channel.file.EventQueueBackingStoreFile.beginCheckpoint(EventQueueBackingStoreFile.java:214)] Start checkpoint for /usr/aboutyun_tmp123/checkpoint, elements to sync = 3
2014-06-02 12:01:10,949 (Log-BackgroundWorker-channel1) [INFO - org.apache.flume.channel.file.EventQueueBackingStoreFile.checkpoint(EventQueueBackingStoreFile.java:239)] Updating checkpoint metadata: logWriteOrderID: 1401681430998, queueSize: 0, queueHead: 11
2014-06-02 12:01:10,952 (Log-BackgroundWorker-channel1) [INFO - org.apache.flume.channel.file.Log.writeCheckpoint(Log.java:1005)] Updated checkpoint for file: /usr/aboutyun_tmp/log-8 position: 2482 logWriteOrderID: 1401681430998
2014-06-02 12:01:10,953 (Log-BackgroundWorker-channel1) [DEBUG - org.apache.flume.channel.file.Log.removeOldLogs(Log.java:1067)] Files currently in use: [8]
2014-06-02 12:01:11,872 (hdfs-sink1-roll-timer-0) [DEBUG - org.apache.flume.sink.hdfs.BucketWriter$2.call(BucketWriter.java:303)] Rolling file (hdfs://master:8020/aboutyunlog/FlumeData.1401681667750.tmp): Roll scheduled after 4 sec elapsed.
2014-06-02 12:01:11,873 (hdfs-sink1-roll-timer-0) [INFO - org.apache.flume.sink.hdfs.BucketWriter.close(BucketWriter.java:409)] Closing hdfs://master:8020/aboutyunlog/FlumeData.1401681667750.tmp
2014-06-02 12:01:11,873 (hdfs-sink1-call-runner-7) [INFO - org.apache.flume.sink.hdfs.BucketWriter$3.call(BucketWriter.java:339)] Close tries incremented
2014-06-02 12:01:11,895 (hdfs-sink1-call-runner-8) [INFO - org.apache.flume.sink.hdfs.BucketWriter$8.call(BucketWriter.java:669)] Renaming hdfs://master:8020/aboutyunlog/FlumeData.1401681667750.tmp to hdfs://master:8020/aboutyunlog/FlumeData.1401681667750
2014-06-02 12:01:11,897 (hdfs-sink1-roll-timer-0) [INFO - org.apache.flume.sink.hdfs.HDFSEventSink$1.run(HDFSEventSink.java:402)] Writer callback called.
2014-06-02 12:01:12,423 (conf-file-poller-0) [DEBUG - org.apache.flume.node.PollingPropertiesFileConfigurationProvider$FileWatcherRunnable.run(PollingPropertiesFileConfigurationProvider.java:126)] Checking file:conf/example for changes
2014-06-02 12:01:40,953 (Log-BackgroundWorker-channel1) [DEBUG - org.apache.flume.channel.file.FlumeEventQueue.checkpoint(FlumeEventQueue.java:137)] Checkpoint not required
上传成功之后,我们去hdfs上,查看上传文件:
这样我们做到了flume上传到hadoop2.2。
完毕
让你系统认识flume及安装和使用flume1.5传输数据到hadoop2.2的更多相关文章
- 日志采集框架Flume以及Flume的安装部署(一个分布式、可靠、和高可用的海量日志采集、聚合和传输的系统)
Flume支持众多的source和sink类型,详细手册可参考官方文档,更多source和sink组件 http://flume.apache.org/FlumeUserGuide.html Flum ...
- Flume的安装与配置
Flume的安装与配置 一. 资源下载 资源地址:http://flume.apache.org/download.html 程序地址:http://apache.fayea.com/fl ...
- Windows下Flume的安装
flume(日志收集系统) Flume是Cloudera提供的一个高可用的,高可靠的,分布式的海量日志采集.聚合和传输的系统,Flume支持在日志系统中定制各类数据发送方,用于收集数据:同时,Flum ...
- 日志收集框架flume的安装及简单使用
flume介绍 Flume是一个分布式.可靠.和高可用的海量日志采集.聚合和传输的系统. Flume可以采集文件,socket数据包等各种形式源数据,又可以将采集到的数据输出到HDFS.hbase.h ...
- Flume的安装,配置及使用
1,上传jar包 2,解压 3,改名 4,更改配置文件 将template文件重镜像 root@Ubuntu-1:/usr/local/apache-flume/conf# cat flume-env ...
- Flume介绍安装使用
APache Flume官网:http://flume.apache.org/releases/content/1.9.0/FlumeUserGuide.html#memory-channel 目录 ...
- 大数据系统之监控系统(二)Flume的扩展
一些需求是原生Flume无法满足的,因此,基于开源的Flume我们增加了许多功能. EventDeserializer的缺陷 Flume的每一个source对应的deserializer必须实现接口E ...
- centos 6x系统下源码安装mysql操作记录
在运维工作中经常部署各种运维环境,涉及mysql数据库的安装也是时常需要的.mysql数据库安装可以选择yum在线安装,但是这种安装的mysql一般是系统自带的,版本方面可能跟需求不太匹配.可以通过源 ...
- 腾讯云Linux系统中启动自己安装的tomcat
腾讯云Linux系统中启动自己安装的tomcat 首先通过工具查看一下安装的tomcat的位置 进入命令行之后输入以下指令: 此时,tomcat已经启动了.
随机推荐
- leetcode3 Two Sum III – Data structure design
Question: Design and implement a TwoSum class. It should support the following operations: add and f ...
- linux更改shell
1.查看机器安装了哪些shell? 有两种方法可以查看. 第一种: 使用env命令查看环境变量里面的shell信息第二种: $ cat /etc/shells 2.查看当前正在使用的shell是哪个? ...
- java信号量PV操作 解决生产者-消费者问题
package test1; /** * 该例子演示生产者和消费者的问题(设只有一个缓存空间.一个消费者和一个生产者) * MySystem类定义了缓冲区个数以及信号量 * @author HYY * ...
- 一篇文章教会你,如何做到招聘要求中的“要有扎实的Java基础
来历 本文来自于一次和群里猿友的交流,具体的情况且听LZ慢慢道来. 一日,LZ在群里发话,“招人啦.” 然某群友曰,“群主,俺想去.” LZ回之,“你年几何?” 群友曰,“两年也.” LZ憾言之,“惜 ...
- Android安装常见问题
在初次运行Android程序的时候会出现类似的错误,导致程序无法继续运行,如下面的几个例子: 问题1:PC安卓模拟器 PANIC: Could not open: C:\Documents and S ...
- MySQL数据库乱码 - Linux下乱码问题一
乱码问题是很让人抓狂的问题,下面我将记录一下linux下mysql乱码问题的解决方法. mysql在linux下乱码问题 一.操作 mysql默认字符集是latin1,但是我们大部分程序使用的字符集是 ...
- Linux配置vpn
配置如下
- Android开发UI之开源项目第一篇——个性化控件(View)篇
原文:http://blog.csdn.net/java886o/article/details/24355907 本文为那些不错的Android开源项目第一篇——个性化控件(View)篇,主要介绍A ...
- Android开发UI之textview实现高亮显示并点击跳转
textview实现高亮显示,带下划线,带背景,主要是通过SpannableString类实现. 具体实现请看代码: TextView showMoreContent=(TextView)findvi ...
- poj2186Popular Cows(强连通分量)
http://poj.org/problem?id=2186 用tarjan算出强连通分量的个数 将其缩点 连成一棵树 则题目所求即变成求出度为0 的那个节点 在树中是唯一的 即树根 #includ ...