深度学习与人类语言处理-语音识别(part2)
上节回顾深度学习与人类语言处理-语音识别(part1),这节课我们将学习如何将seq2seq模型用在语音识别
LAS

那我们来看看LAS的Encoder,Attend,Decoder分别是什么
Listen
Listen是一个典型的Encoder结构,输入为声学特征\({x^1,x^2,...,x^T}\),输出和输入长度相同,是对声学特征的高阶表示,\({h^1,h^2,...,h^T}\).
我们希望Encoder可以做到以下两件事:
- 提取输入的内容信息
- 移除不同说话者之间的差异,去掉噪音
那Encoder怎么做呢?可以用RNN、CNN、self-attention
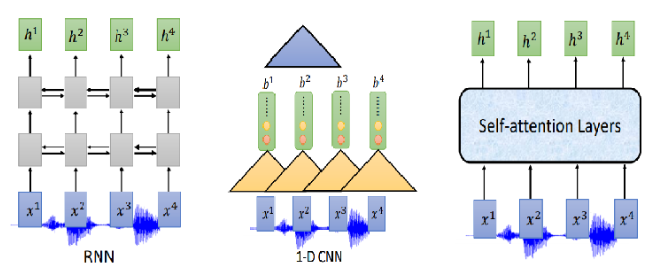
通常我们需要对声音信号进行下采样,为什么呢?当然是声音信号太长了,1s的声音信号就有100个向量(上节声学特征部分讲过),而且相邻的信号之间的差异不是特别大,下采样可以帮助我们有效的进行训练。下图是关于RNN的两个下采样方法
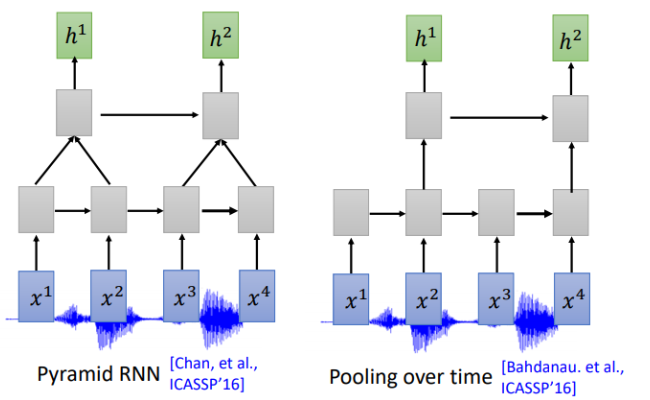
Pyramid RNN将下层每两个隐状态加起来作为下一层,实践证明这种方法还是很有效的。Pooling over time 和Pyramid RNN 很像,不同没有加起来,直接每两个隐状态取一次作为下层输入。
那CNN和self-attention是不是也可以用类似的下采样呢?答案是肯定的。对于CNN常用的变形是TDNN (Time-delay DNN),不同于传统的CNN做卷积操作时会考虑范围内所有的输入,TDNN相当于只让部分参与了运算,提高效率。
同样,对于self-attention,在机器翻译等任务中每一个位置的输入会看过序列中所有的输入,但是在语音识别中,序列实在太长了,Truncated Self-attention 就是让每一个位置的输入只看窗口范围内的其他输入,窗口大小是一个可以调节的参数,例如可以只看未来4个,看以前的30个。

attention
LAS的attention和机器翻译中的attention并没有什么不同,文献中提到了两种attention计算方法,dot-product attention 和additive attention
- dot-product attention
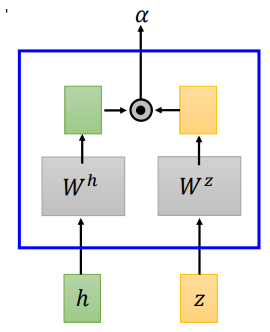
dot-product attention 将输入\(h\)和\(z\)经过矩阵\(W^h、W^z\)转换,将转换结果进行点积,得到\(\alpha\)
- additive attention
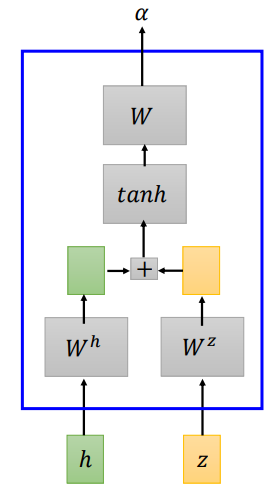
additive attention 将输入\(h\)和\(z\)经过矩阵\(W^h、W^z\)转换,将转换结果相加,经过一个线性变换得到\(\alpha\)
我们来看看LAS的attention具体怎么做的
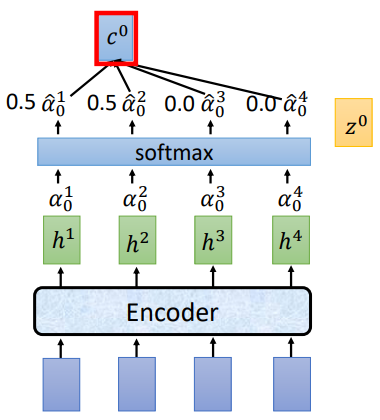
将\(z^0\)分别和\(h^1,h^2,h^3,h^4\)做attention运算得到\(\alpha ^1 _ 0,\alpha ^2 _ 0,\alpha ^3 _ 0,\alpha ^4 _ 0\),经过softmax归一化,再将归一化后的结果和\(h^i\)相乘求和得到 \(c^0\),将 \(c^0\)作为Decoder部分的输入
举个栗子:
讲过attention计算和softmax归一化后,得到的\(\hat{\alpha_0}\)为[0.5,0.5,0.0,0.0],\(c^0 = \sum\hat{\alpha}^i_0h^i=0.5h^1+0.5h^2\).
Spell
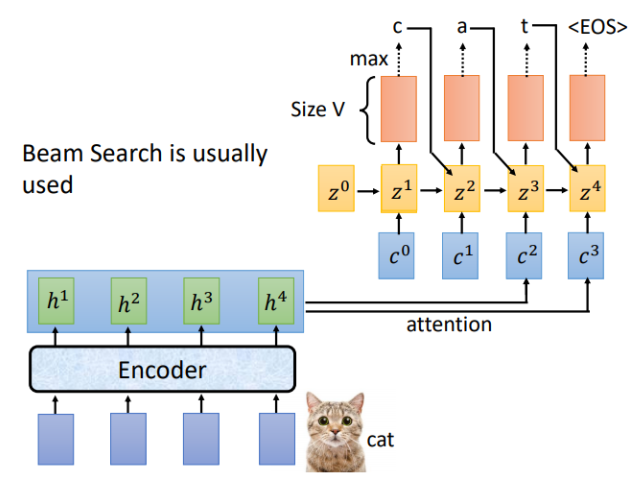
LAS的Listen对应Encoder,Spell对应的就是Decoder,假设Encoder的输入为“cat",Decoder的每一个时间步对应的输出就是词汇表中每个词的分布,通常会选概率最大的那个作为输出。

刚才是用\(z^0\)计算得到\(c^0\),现在我们用\(z^1\)进行运算,重复attention过程,就得到了\(c^1\),对应的结果如下

完整的Spell流程如下,通常输出结果会用束搜索(beam search),有关beam search 的内容可以自行了解。
Trainging
训练过程有一个重要的不同就是Teacher Forcing。刚才在Spell部分我们说到,一个时刻的输入其实有三个部分(\(c^1,z^0,o^0)\),当前位置的attention结果context向量,上一时刻的隐状态,以及上一时刻的预测输出。但是在training阶段,我们会将\(o^0\)换成真实的上一时刻的输出。假如\(t_0\)预测的输出为\(x\),实际应该输出\(c\),我们会将\(c\)作为下一时刻的输入。这就是Teacher Forcing
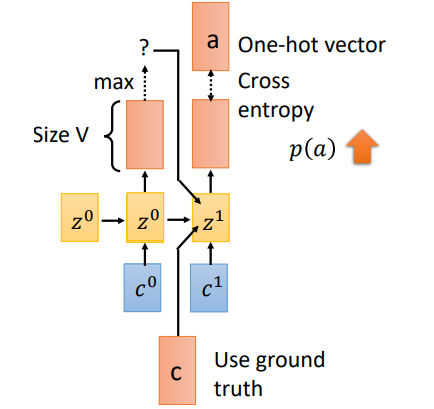
那为什么需要Teacher forcing呢?我们来看看如果使用上一时刻预测的输出作为输入会发生什么
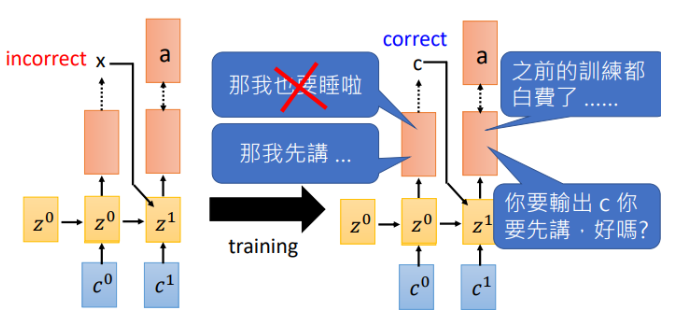
假如在\(t_0\)输出了\(x\),下一时刻机器就会学习在输入为\(x\)时我需要输出\(a\),然而等到训练的一定回合时,\(t_0\)可以做出正确的预测了,告诉机器输入\(c\)需要输出\(a\),此刻机器已经懵了,刚才不是说\(x\)对应\(a\)吗,那之前的训练就白费了。就开始互掐了。。。
- back to attention
我们在回到之前的attention操作,attention计算得到的context被用于下一时刻的输入(左图),现在还有另一种attention架构,将context直接用于当前时刻的输入(右图)
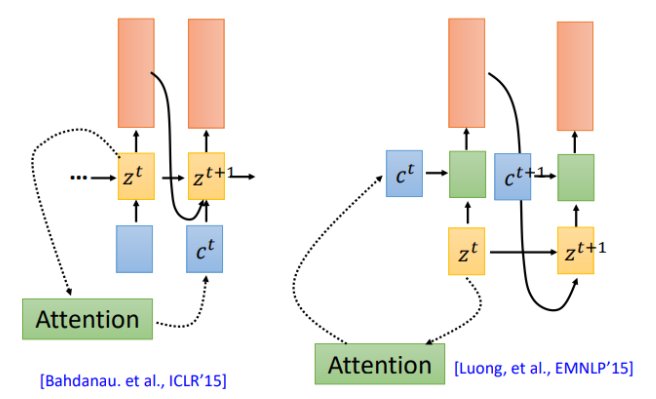
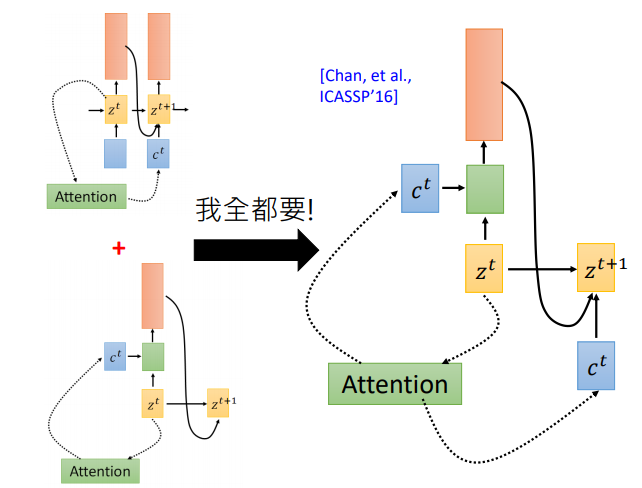
那么哪一种更有效呢?该用那个呢。第一篇使用seq2seq做语音识别的论文说:我全都要。context向量即作用于当前位置,也作用于下一位置
使用Attention作语音识别真的好吗?
有点杀鸡用牛刀的感觉!为好么呢,我们知道用attention的seq2seq模型首先用在机器翻译上,在翻译任务中,输入和输出没有一致的对应关系,需要attention自己寻找对应的那个词。但是对语音来说输入输出是对应的,有人提出了location-aware attention
LAS —Does it work?
刚开始的时候LAS其实打不过传统模型,后来随着训练集的增加以及各种trick,LAS已经很厉害了。可以看到刚开始的时候,打不过传统模型,2018年google在12500小时的训练集上训练,最终打败了传统模型,并没有使用location-aware attention,而且最重要的是模型变小了,从原来的7.2G变成0.4G

那LAS还有什么问题呢?
LAS采用经典的Encoder和Decoder架构,也就是说,只有在完整的听完一句话之后模型才会输出,那如果我们希望机器在听到声音的同时就输出怎么做呢?我们下节课再讲。
深度学习与人类语言处理-语音识别(part2)的更多相关文章
- 深度学习与人类语言处理-语音识别(part1)
语音识别 语音识别该何去何从? 1969年,J.R. PIERCE:"语音识别就像把水变成汽油.从大海中淘金.治疗癌症.人类登陆月球" 当然,这是50年前的想法,那么语音识别该如何 ...
- 深度学习与人类语言处理-语音识别(part3)
上节回顾深度学习与人类语言处理-语音识别(part2),这节课我们接着看seq2seq模型怎么做语音识别 上节课我们知道LAS做语音识别需要看完一个完整的序列才能输出,把我们希望语音识别模型可以在听到 ...
- 李宏毅深度学习与人类语言处理-introduction
深度学习与人类语言处理(Deep learning for Human Language Processing) 李宏毅老师深度学习与人类语言处理课程笔记,请看正文 这门课会学到什么? 为什么叫人类语 ...
- 纯干货:深度学习实现之空间变换网络-part2
https://www.jianshu.com/p/854d111670b6 纯干货:深度学习实现之空间变换网络-part1 在第一部分中,我们主要介绍了两个非常重要的概念:仿射变换和双线性插值,并了 ...
- 【PyTorch深度学习60分钟快速入门 】Part2:Autograd自动化微分
在PyTorch中,集中于所有神经网络的是autograd包.首先,我们简要地看一下此工具包,然后我们将训练第一个神经网络. autograd包为张量的所有操作提供了自动微分.它是一个运行式定义的 ...
- R语言︱H2o深度学习的一些R语言实践——H2o包
每每以为攀得众山小,可.每每又切实来到起点,大牛们,缓缓脚步来俺笔记葩分享一下吧,please~ --------------------------- R语言H2o包的几个应用案例 笔者寄语:受启发 ...
- 碎片︱R语言与深度学习
笔者:受alphago影响,想看看深度学习,但是其在R语言中的应用包可谓少之又少,更多的是在matlab和python中或者是调用.整理一下目前我看到的R语言的材料: ---------------- ...
- [翻译]深度学习的机器(The learning machines)
学习的机器 用大量的数据识别图像和语音,深度学习的计算机(deep-learning computers) 向真正意义上的人工智能迈出了一大步. Nicola Jones Computer Scien ...
- Bengio最新博文:深度学习展望
Bengio最新博文:深度学习展望 人类一直梦想着创造有智能的机器.早在第一台可编程计算机问世前100多年,发明家就对如何能让由连杆和齿轮组成的设备也变得更加智能这一命题充满好奇.后来,20世纪40年 ...
随机推荐
- java170道面试题汇总+详细解析
2013年年底的时候,我看到了网上流传的一个叫做<Java面试题大全>的东西,认真的阅读了以后发现里面的很多题目是重复且没有价值的题目,还有不少的参考答案也是错误的,于是我花了半个月时间对 ...
- Qt 添加Includes、Libraries库
1 #------------------------------------------------- # # 加载相机SDK-Includes-Libraries # #------------- ...
- 使用zxing生成和解析二维码
二维码: 是用某种特定的几何图形按一定规律在平面(二维方向上)分布的黑白相间的图形记录数据符号信息的: 在代码编制上巧妙的利用构成计算机内部逻辑基础的0和1比特流的概念,使用若干个与二进制相对应的几何 ...
- spring给予XML配置的声明式事务
步骤: 1.添加aop.tx命名空间声明: 2.配置事务管理器: 3.配置增强: 4.配置aop 具体xml设置如下: <?xml version="1.0" encodin ...
- Win32下双缓冲绘图技术
一:双缓冲原理 为了解决窗口刷新频率过快所带来的闪烁问题,利用双缓冲技术进行绘图.所谓双缓冲技术,就是将资源加载到内存,然后复制内存数据到设备DC(这个比较快),避免了直接在设备DC上绘图(这个比较慢 ...
- vue基础指令了解补充及组件介绍
v-once指令 """ v-once:单独使用,限制的标签内容一旦赋值,便不可被动更改(如果是输入框,可以主动修改) """ <di ...
- 吴裕雄--天生自然 PYTHON数据分析:医疗数据分析
import numpy as np # linear algebra import pandas as pd # data processing, CSV file I/O (e.g. pd.rea ...
- http://yuedu.baidu.com/ebook/36edd3d7ba1aa8114531d911
本书概述: 全面深入自动化测试技术,包括接口自动化测试.app自动化测试.性能自动化测试技术:实践,理论结合,方案,环境,代码 java语言,python语言,自动化测试开发 ...
- 月薪20k+的测试工程师都会这项技能!
一说到测试,很多人认为就是在一直"点点点"找bug的重复性工作,这是早期手工测试给人的刻板印象,随着测试行业的发展,"会代码"越来越成为测试工程师的一个标签. ...
- iOS多线程之Thread
多线程 • Thread 是苹果官方提供的,简单已用,可以直接操作线程对象.不过需要程序员自己管理线程的生命周期,主要是创建那部分 优缺点 面向对象,简单易用 直接操作线程对象 需要自己管理线程生命周 ...