当AI遇上K8S:使用Rancher安装机器学习必备工具JupyterHub
Jupyter Notebook是用于科学数据分析的利器,JupyterHub可以在服务器环境下为多个用户托管Jupyter运行环境。本文将详细介绍如何使用Rancher安装JupyterHub来为数据科学和机器学习开发创建可扩展的工作区。

本文来自 Rancher Labs
人工智能(AI)和机器学习(ML)正在成为技术领域的关键差异化因素。从本质上讲,人工智能和机器学习都是计算量巨大的工作负载,它们需要一流的分布式计算环境才能够蓬勃发展。因此,AI和ML为Kubernetes提供了一个完美的用例,他们能够最大化展现Kubernetes可以运行大量工作负载的特点。
什么是JupyterHub?
Jupyter Notebook是用于科学数据分析的利器,JupyterHub可以在服务器环境下为多个用户托管Jupyter运行环境。JupyterHub是一个多用户数据探索工具,通常是数据科学和机器学习研究与开发的关键工具。它为工程师、科学家、研究人员和学生提供了云或数据中心的计算能力,同时仍然像本地开发环境一样易于使用。本质上,JupyterHub使用户可以访问计算环境和资源,而不会给他们增加安装和维护任务的负担。用户可以在工作区中使用共享资源,系统管理员会对其进行有效管理。
在AI/ML工作负载中使用Kubernetes
Kubernetes非常擅长让我们利用大型分布式计算环境。因为其声明式设计和基于发现的服务器寻址方法,所以将计算资源应用于工作负载很容易。通常在AI/ML工作负载中,工程师或研究人员需要分配更多的资源。而Kubernetes让在物理基础架构之间迁移工作负载更加可行。在本文中,我们将展示如何使用Rancher安装JupyterHub。
使用Rancher安装JupyterHub
首先,假设我们在Rancher环境中拥有现代化的Kubernetes部署。在本文发布时,Kubernetes的稳定版本是1.16。对于JupyterHub来说,其中一个前期准备是持久化存储,所以你将需要思考如何在这个集群中提供它。出于演示的目的,我们可以使用Rancher Catalog中包含的实验性NFS提供程序来提供持久化存储。点开App Catalog并选择【启动】。然后搜索NFS提供程序。保留默认设置,然后单击屏幕底部的【启动】。如果你已经有持久化存储的解决方案,也可以直接使用它。

导航到Rancher App Catalog
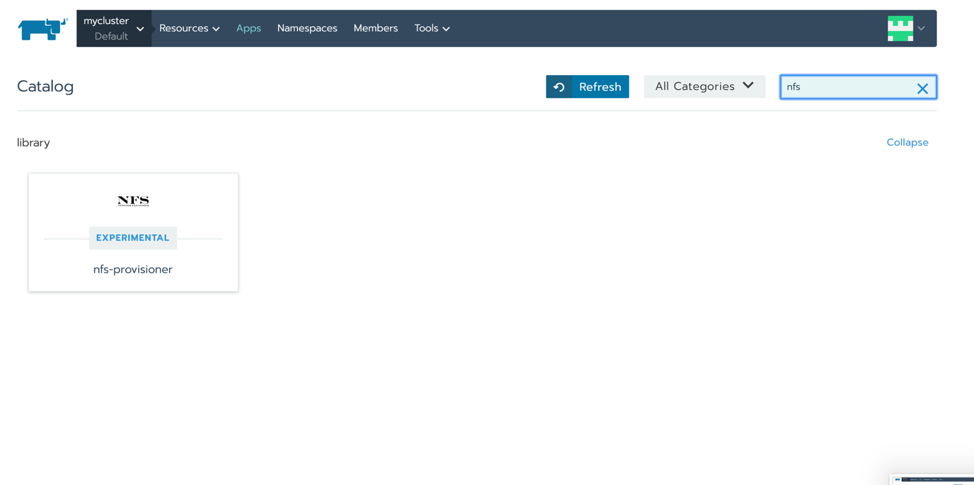
搜索NFS提供程序
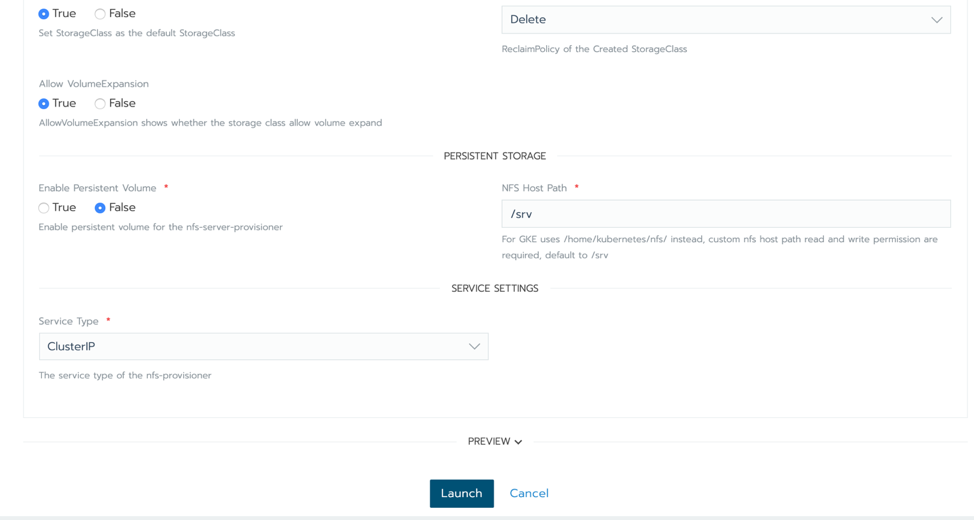
启动NFS提供程序
现在我们已经有了存储提供程序并且定义了默认存储类,我们可以继续部署应用程序组件。我们将使用Helm3来完成这一操作。查看helm官方文档(https://helm.sh/docs/intro/install/ ),在你的电脑上安装helm3客户端。另外,你也可以使用Rancher Catalog来部署helm chart,而无需任何其他工具。需要确保将repo添加到Rancher catalog中。
在我们使用helm之前,我们需要为应用程序创建一个命名空间。在Rancher UI中,进入集群并选择顶端菜单栏的【项目/命名空间】。你可以为JupyterHub创建一个新的命名空间。例如,我们将命名空间称为“jhub“。请注意此名称,因为我们将之后会使用。
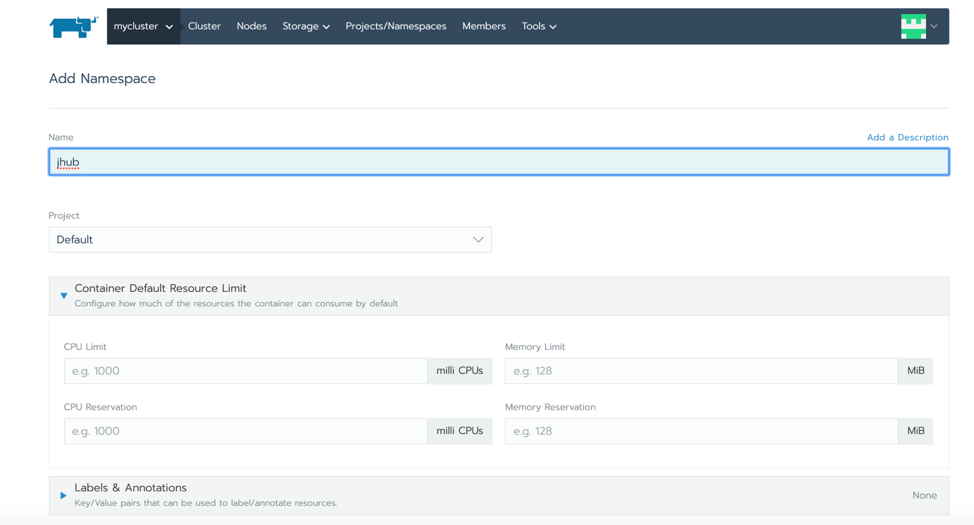
创建一个命名空间
接下来,我们可以为将要使用的JupyterHub Chart添加Helm repo。如果使用的是Rancher catalog,你需要在UI上完成此操作而不是Helm CLI:
helm repo add jupyterhub https://jupyterhub.github.io/helm-chart/
helm repo update
然后,让我们创建一个config文件,其中包含了我们要与此chart一起使用的设置。我们将该文件命名为config.yaml:
proxy:
secretToken: "<secret token>"
ingress:
enabled: true
hosts:
- <host name>
让我们替换几个项目,使它们是唯一的。用以下输出替换secretToken:
openssl rand -hex 32
并替换为你打算用来访问JyupiterHub UI的可解析DNS名称。
有了配置文件之后,就可以安装chart了。我们将引用该配置文件,因此请确保该文件存在你当前的工作目录中:
RELEASE=jhub
NAMESPACE=jhub
helm upgrade --install $RELEASE jupyterhub/jupyterhub --namespace $NAMESPACE --version=0.8.2 --values config.yaml
Helm现在应该部署所需的组件。这将需要一些时间,但是最终你应该能够通过之前设置的主机名访问UI。你也可以通过转到Rancher UI中的“工作负载“选项卡来检查状态。当我们尝试在浏览器中设置的主机名时,它将显示以下登录界面:
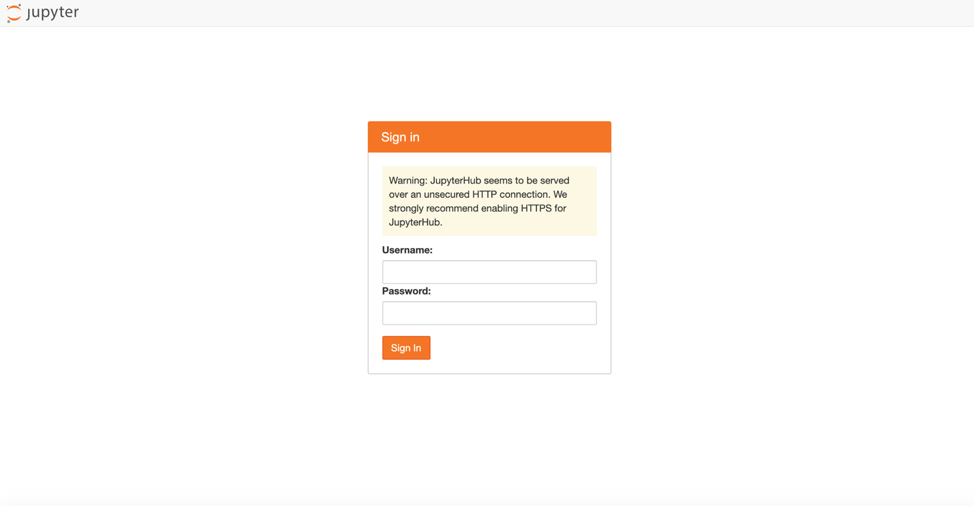
主机名登录界面
在撰写本文时,有一个issue是Kubernetes 1.16中的更改导致Jyupiter Hub的代码在尝试与Kuberentes API交互时中断。如果要立即修复,我们可以运行以下patch命令:
kubectl patch deploy -n $NAMESPACE hub --type json --patch '[{"op": "replace", "path": "/spec/template/spec/containers/0/command", "value": ["bash", "-c", "\nmkdir -p ~/hotfix\ncp -r /usr/local/lib/python3.6/dist-packages/kubespawner ~/hotfix\nls -R ~/hotfix\npatch ~/hotfix/kubespawner/spawner.py << EOT\n72c72\n< key=lambda x: x.last_timestamp,\n---\n> key=lambda x: x.last_timestamp and x.last_timestamp.timestamp() or 0.,\nEOT\n\nPYTHONPATH=$HOME/hotfix jupyterhub --config /srv/jupyterhub_config.py --upgrade-db\n"]}]'
你现在已经在Rancher上部署了可以正常工作的JupyterHub环境。默认情况下,JupyterHub使用PAM身份验证。因此,可以使用系统上的任何有效Linux用户登录。登录后,我们应该能够创建新的notebook:
Jupyter登录界面
创建新的notebook
另外,你可以查看其他你可能想配置的身份验证选项。例如,你可以使用Github身份验证来允许用户登录并且创建基于他们Github ID的notebook。你选择好一个身份验证的工具之后,需要按照说明更新我们之前创建的config.yml文件,然后重新运行helm upgrade命令。
总 结
在本文中,我们展示了如何使用Rancher安装JupyterHub来为数据科学和机器学习开发创建可扩展的工作区。如果你想要安装功能齐全的JupyterHub安装,你可能还需要考虑其他因素。本文只是向你展示了如何快速搭建一个基础功能的JupyterHub,希望能帮助你快速开启AI旅程!
当AI遇上K8S:使用Rancher安装机器学习必备工具JupyterHub的更多相关文章
- 关于ubuntu服务器上部署postgresql 以及安装pgadmin4管理工具(web版)
进入目录:cd pgadmin4 source bin/activate cd pgadmin4-1.6/ 启动pgadmin4:python web/pgAdmin4.py pgadmi ...
- .NET遇上Docker - Harbor的安装与基本使用
Harbor是一个开源企业级Docker注册中心,可以用于搭建私有的Docker Image仓库.可以实现权限控制等. 安装Harbor 首先,需要安装Docker和Docker Compose,参考 ...
- ubuntu 18.04 64bit下如何安装python开发工具jupyterhub
注:这是多用户版本 1.安装依赖 sudo apt-get install npm nodes sudo apt-get install python3-distutils wget https:// ...
- 初识genymotion安装遇上的VirtualBox问题
想必做过Android开发的都讨厌那慢如蜗牛的 eclipse原生Android模拟器吧! 光是启动这个模拟器都得花上两三分钟,慢慢的用起来手机来调试,但那毕竟不是长久之计,也确实不方便,后来知道了g ...
- 微服务中台落地 中台误区 当中台遇上DDD,我们该如何设计微服务
小结: 1. 微服务中台不是 /1堆砌技术组件就是中台 /2拥有服务治理就是中台 /3增加部分业务功能就是中台 /4Cloud Native 就是中台 https://mp.weixin.qq.com ...
- K8s集群安装--最新版 Kubernetes 1.14.1
K8s集群安装--最新版 Kubernetes 1.14.1 前言 网上有很多关于k8s安装的文章,但是我参照一些文章安装时碰到了不少坑.今天终于安装好了,故将一些关键点写下来与大家共享. 我安装是基 ...
- mac上k8s学习踩坑
本文学习k8s参考内容:http://docs.kubernetes.org.cn/126.html,学习过程中遇到一些坑,记录如下: -------------------------------- ...
- 前端遇上Go: 静态资源增量更新的新实践
前端遇上Go: 静态资源增量更新的新实践https://mp.weixin.qq.com/s/hCqQW1F8FngPPGZAisAWUg 前端遇上Go: 静态资源增量更新的新实践 原创: 洋河 美团 ...
- Kubernetes(k8s)集群安装
一:简介 二:基础环境安装 1.系统环境 os Role ip Memory Centos 7 master01 192.168.25.30 4G Centos 7 node01 192.168.25 ...
随机推荐
- Hibernate实现步骤
1. 引入jar文件(hibernate3.jar, lib\required目录下所有的jar,log4j记录的log4j-1.2.16.jar,slf4j-log4j12-1.5.8.jar,oj ...
- 插入排序算法&算法分析
- 查漏补缺:Vector中去重
对于STL去重,可以使用<algorithm>中提供的unique()函数. unique()函数用于去除相邻元素中的重复元素(所以去重前需要对vector进行排序),只留下一个.返回去重 ...
- Redis 机器内核参数优化
" > /proc/sys/vm/overcommit_memory echo never > /sys/kernel/mm/transparent_hugepage/enabl ...
- 二手iPhone,为什么没有火?
据相关媒体报道,日前苹果准备向印度市场销售二手iPhone,以提高自己在这个市场内的竞争力,但却遭遇到了强烈的反对,首先是印度本土手机制造商担心二手iPhone会冲击他们的销售,让其本就微薄的利润更加 ...
- 从wordpress换hexo博客后
之前用wordpress做blog, 为什么换为hexo呢? 第一 wordpress的文章都保存在服务器的数据库, 维护不是很直观. 而hexo是自己编写markdown文章,本地一份,而b ...
- kafka相关问题总结
一直在使用kafka,遇到过很多问题,总结一下 很多人对比kafka和AMQP的时候,都会强调kafka会丢数据,感觉好像只要用kafka就会丢数据一样,从而排斥使用kafka,亦或者在使用的过程中, ...
- css进阶之二:flex弹性布局
布局模式是指一个盒子与其兄弟.祖先盒的关系决定其尺寸与位置的算法.css2.1中定义了四种布局模式,分别是块布局.行内布局.表格布局.以及定位布局.css3引入了新的布局模式Flexbox布局,灵活度 ...
- 从2019-nCoV趋势预测问题,联想到关于网络安全态势预测问题的讨论
0. 引言 在这篇文章中,笔者希望和大家讨论一个话题,即未来趋势是否可以被精确或概率性地预测. 对笔者所在的网络安全领域来说,由于网络攻击和网络入侵常常变现出随机性.非线性性的特征,因此纯粹的未来预测 ...
- 线程状态,BLOCKED和WAITING有什么区别
线程可以通过notify,join,LockSupport.park方式进入wating状态,进入wating状态的线程等待唤醒(notify或notifyAll)才有机会获取cpu的时间片段来继续执 ...