中文分词工具——jieba
汉字是智慧和想象力的宝库。 ——索尼公司创始人井深大
简介
在英语中,单词就是“词”的表达,一个句子是由空格来分隔的,而在汉语中,词以字为基本单位,但是一篇文章的表达是以词来划分的,汉语句子对词构成边界方面很难界定。例如:南京市长江大桥,可以分词为:“南京市/长江/大桥”和“南京市长/江大桥”,这个是人为判断的,机器很难界定。在此介绍中文分词工具jieba,其特点为:
- 社区活跃、目前github上有19670的star数目
- 功能丰富,支持关键词提取、词性标注等
- 多语言支持(Python、C++、Go、R等)
- 使用简单
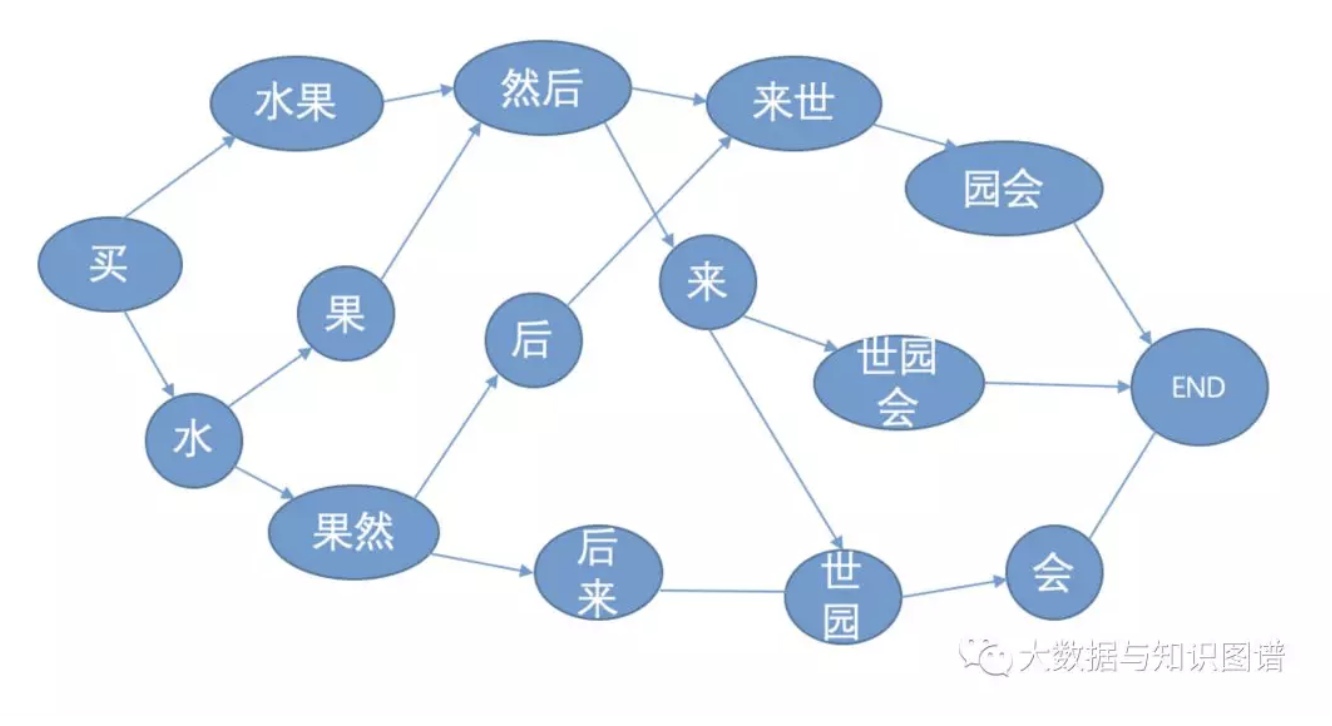
Jieba分词结合了基于规则和基于统计这两类方法。首先基于前缀词典进行词图扫描,前缀词典是指词典中的词按照前缀包含的顺序排列,例如词典中出现了“买”,之后以“买”开头的词都会出现在这一部分,例如“买水”,进而“买水果”,从而形成一种层级包含结构。若将词看成节点,词与词之间的分词符看成边,则一种分词方案对应着从第一个字到最后一个字的一条分词路径,形成全部可能分词结果的有向无环图。
jieba安装
安装很简单,先创建一个python3.6的虚拟环境,再激活环境,最后安装命令如下:
conda create -n nlp_py3 python=3.6
source activate nlp_py3
pip install jieba
jieba的三种分词模式
支持三种分词模式:
精确模式,试图将句子最精确地切开,适合文本分析。
全模式,把句子中所有的可以成词的词语都扫描出来, 速度非常快,但是不能解决歧义。
搜索引擎模式,在精确模式的基础上,对长词再次切分,提高召回率,适合用于搜索引擎分词。
支持繁体分词
支持自定义词典
MIT 授权协议
主要功能
1. 分词
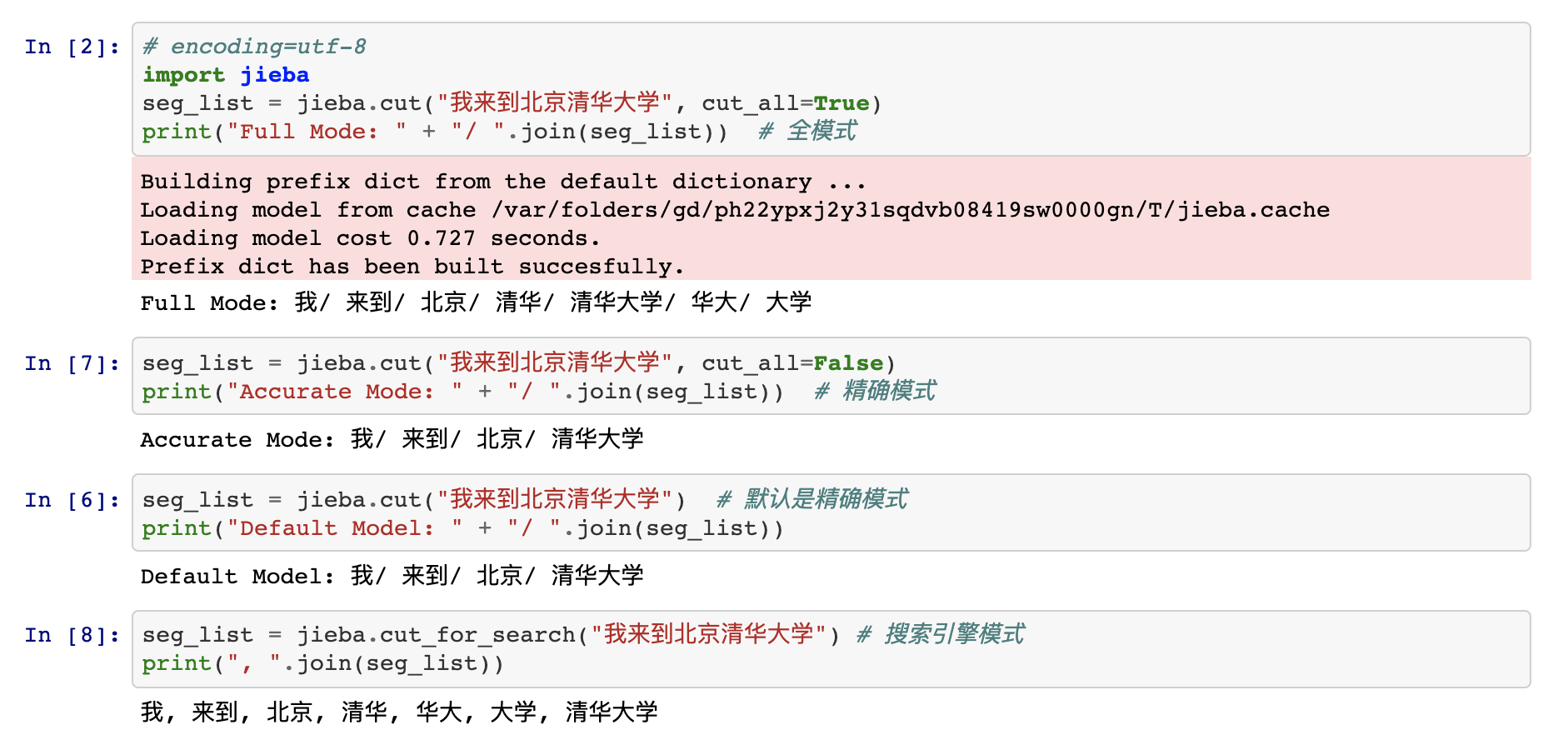
- jieba.cut 方法接受三个输入参数: 需要分词的字符串;cut_all 参数用来控制是否采用全模式;HMM 参数用来控制是否使用 HMM 模型
- jieba.cut_for_search 方法接受两个参数:需要分词的字符串;是否使用 HMM(隐马尔可夫) 模型。该方法适合用于搜索引擎构建倒排索引的分词,粒度比较细
- jieba.lcut 以及 jieba.lcut_for_search 直接返回 list
执行示例:
2.添加自定义词典
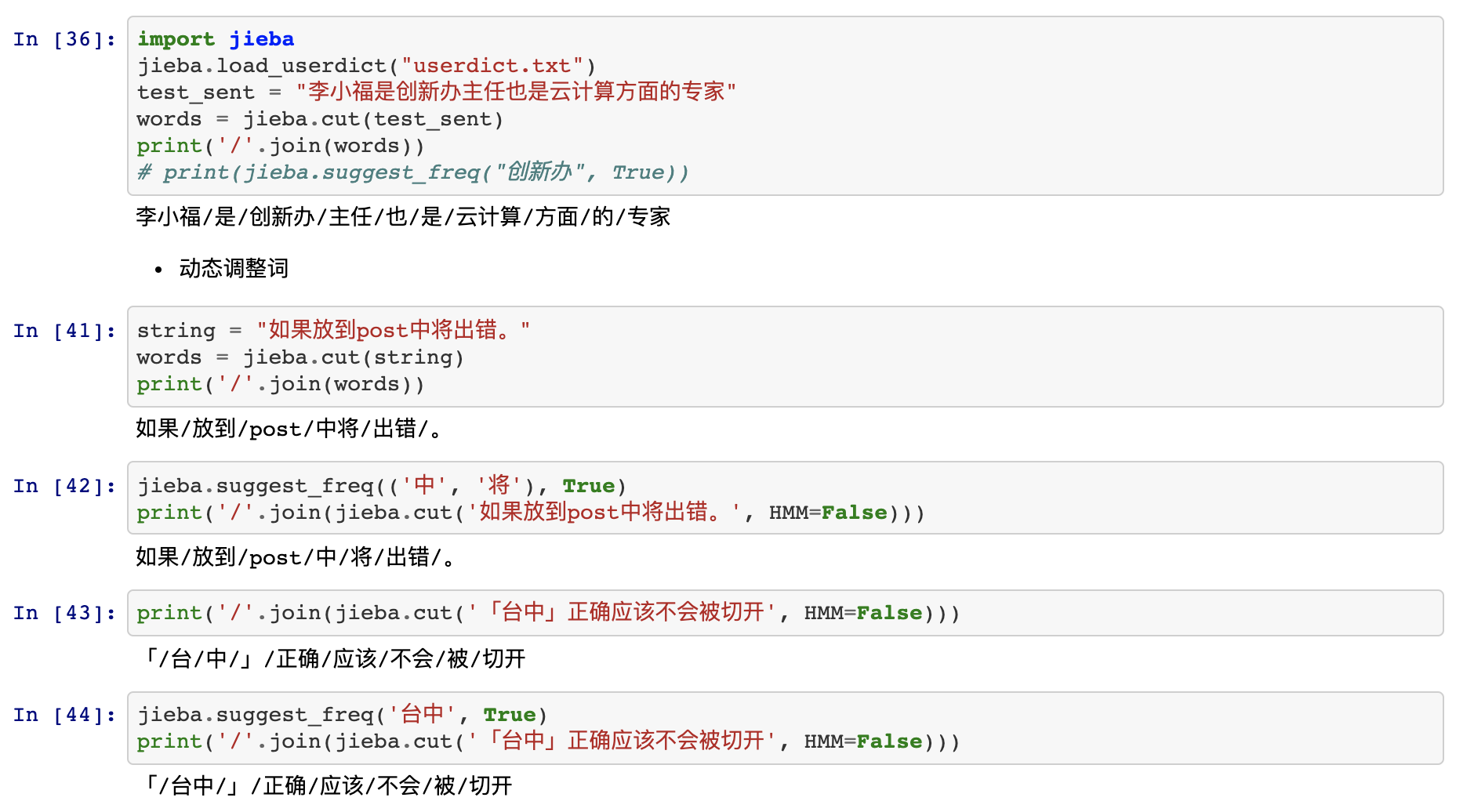
- 开发者可以指定自己自定义的词典,以便包含 jieba 词库里没有的词。虽然 jieba 有新词识别能力,但是自行添加新词可以保证更高的正确率
- 用法: jieba.load_userdict(file_name) # file_name 为文件类对象或自定义词典的路径
- 词典格式和 dict.txt 一样,一个词占一行;每一行分三部分:词语、词频(可省略)、词性(可省略),用空格隔开,顺序不可颠倒。file_name 若为路径或二进制方式打开的文件,则文件必须为 UTF-8 编码。
词频省略时使用自动计算的能保证分出该词的词频。
执行示例:
tips:
P(台中) < P(台)×P(中),“台中”词频不够导致其成词概率较低
解决方法:强制调高词频
jieba.add_word('台中')
或者
jieba.suggest_freq('台中', True)
参考官网:https://github.com/fxsjy/jieba

中文分词工具——jieba的更多相关文章
- 中文分词工具jieba中的词性类型
jieba为自然语言语言中常用工具包,jieba具有对分词的词性进行标注的功能,词性类别如下: Ag 形语素 形容词性语素.形容词代码为 a,语素代码g前面置以A. a 形容词 取英语形容词 adje ...
- 中文分词工具探析(二):Jieba
1. 前言 Jieba是由fxsjy大神开源的一款中文分词工具,一款属于工业界的分词工具--模型易用简单.代码清晰可读,推荐有志学习NLP或Python的读一下源码.与采用分词模型Bigram + H ...
- 中文分词工具简介与安装教程(jieba、nlpir、hanlp、pkuseg、foolnltk、snownlp、thulac)
2.1 jieba 2.1.1 jieba简介 Jieba中文含义结巴,jieba库是目前做的最好的python分词组件.首先它的安装十分便捷,只需要使用pip安装:其次,它不需要另外下载其它的数据包 ...
- 中文分词工具探析(一):ICTCLAS (NLPIR)
1. 前言 ICTCLAS是张华平在2000年推出的中文分词系统,于2009年更名为NLPIR.ICTCLAS是中文分词界元老级工具了,作者开放出了free版本的源代码(1.0整理版本在此). 作者在 ...
- 开源中文分词工具探析(三):Ansj
Ansj是由孙健(ansjsun)开源的一个中文分词器,为ICTLAS的Java版本,也采用了Bigram + HMM分词模型(可参考我之前写的文章):在Bigram分词的基础上,识别未登录词,以提高 ...
- 开源中文分词工具探析(四):THULAC
THULAC是一款相当不错的中文分词工具,准确率高.分词速度蛮快的:并且在工程上做了很多优化,比如:用DAT存储训练特征(压缩训练模型),加入了标点符号的特征(提高分词准确率)等. 1. 前言 THU ...
- 开源中文分词工具探析(五):FNLP
FNLP是由Fudan NLP实验室的邱锡鹏老师开源的一套Java写就的中文NLP工具包,提供诸如分词.词性标注.文本分类.依存句法分析等功能. [开源中文分词工具探析]系列: 中文分词工具探析(一) ...
- 开源中文分词工具探析(五):Stanford CoreNLP
CoreNLP是由斯坦福大学开源的一套Java NLP工具,提供诸如:词性标注(part-of-speech (POS) tagger).命名实体识别(named entity recognizer ...
- 开源中文分词工具探析(七):LTP
LTP是哈工大开源的一套中文语言处理系统,涵盖了基本功能:分词.词性标注.命名实体识别.依存句法分析.语义角色标注.语义依存分析等. [开源中文分词工具探析]系列: 开源中文分词工具探析(一):ICT ...
随机推荐
- Java——IO流超详细总结
该系列博文会告诉你如何从入门到进阶,一步步地学习Java基础知识,并上手进行实战,接着了解每个Java知识点背后的实现原理,更完整地了解整个Java技术体系,形成自己的知识框架. 在初学Java时,I ...
- MES系统的模型结构和主要功能(二)
上一节,我们主要说了Mes系统是什么,以及它的特点和难点,本节,再来讨论一下一个合格的MES系统的模型结构和基本功能. 现代工厂的快速发展,对MES系统提出了更高的要求,其必须满足范围广泛的任务要求, ...
- P3983 赛斯石(双背包)
这题不算难的,但是脑子真的特别乱.....传送门 \(Ⅰ.物品可以拆开来但船不能拆开来,所以1-10载重船的最大收益完全可以用背包求出来.\) \(Ⅱ.最后一定是选一些船走,而船的收益已经固定.所以用 ...
- spring boot项目中无法访问resources文件夹问题
如图,浏览器默认访问static文件下的内容,无法访问templates文件下的html文件. 解决方法: 在application.properties文件中添加静态资源目录的配置即可.
- 【Java基础总结】Java基础语法篇(上)
Java基础语法 思维导图 一.Java语言介绍 1.Java应用平台 JavaSE(Java Platform Standard Edition):开发普通桌面和商务应用程序,是另外两类的基础 Ja ...
- 数据结构——ArrayList的源码分析(你所有的疑问,都会被解答)
一.首先来看一下ArrayList的类图: 1,实现了RandomAccess接口,可以达到随机访问的效果. 2,实现了Serializable接口,可以用来序列化或者反序列化. 3,实现了List接 ...
- imos-累积和法
在解AOJ 0531 Paint Color时,学到了一个累积和的妙用--imos法,由于原文是日语,所以特意翻译过来.值得一提的是,作者Kentaro Imajo跟鄙人同龄,却已取得如此多的成就,而 ...
- 1005 Spell It Right (20分)
1005 Spell It Right (20分) 题目: Given a non-negative integer N, your task is to compute the sum of all ...
- JAVA异常以及字节流
异常 JAVA异常可以分为编译时候出现的异常和执行时候出现的异常 JVM默认处理异常的方法是抛出异常 异常处理 //第一种 try{ 可能会出错的代码 }catch{ 发生异常后处置方法 }final ...
- Elasticsearch系列---几个高级功能
概要 本篇主要介绍一下搜索模板.映射模板.高亮搜索和地理位置的简单玩法. 标准搜索模板 搜索模板search tempalte高级功能之一,可以将我们的一些搜索进行模板化,使用现有模板时传入指定的参数 ...