中文分词工具——jieba
汉字是智慧和想象力的宝库。 ——索尼公司创始人井深大
简介
在英语中,单词就是“词”的表达,一个句子是由空格来分隔的,而在汉语中,词以字为基本单位,但是一篇文章的表达是以词来划分的,汉语句子对词构成边界方面很难界定。例如:南京市长江大桥,可以分词为:“南京市/长江/大桥”和“南京市长/江大桥”,这个是人为判断的,机器很难界定。在此介绍中文分词工具jieba,其特点为:
- 社区活跃、目前github上有19670的star数目
- 功能丰富,支持关键词提取、词性标注等
- 多语言支持(Python、C++、Go、R等)
- 使用简单
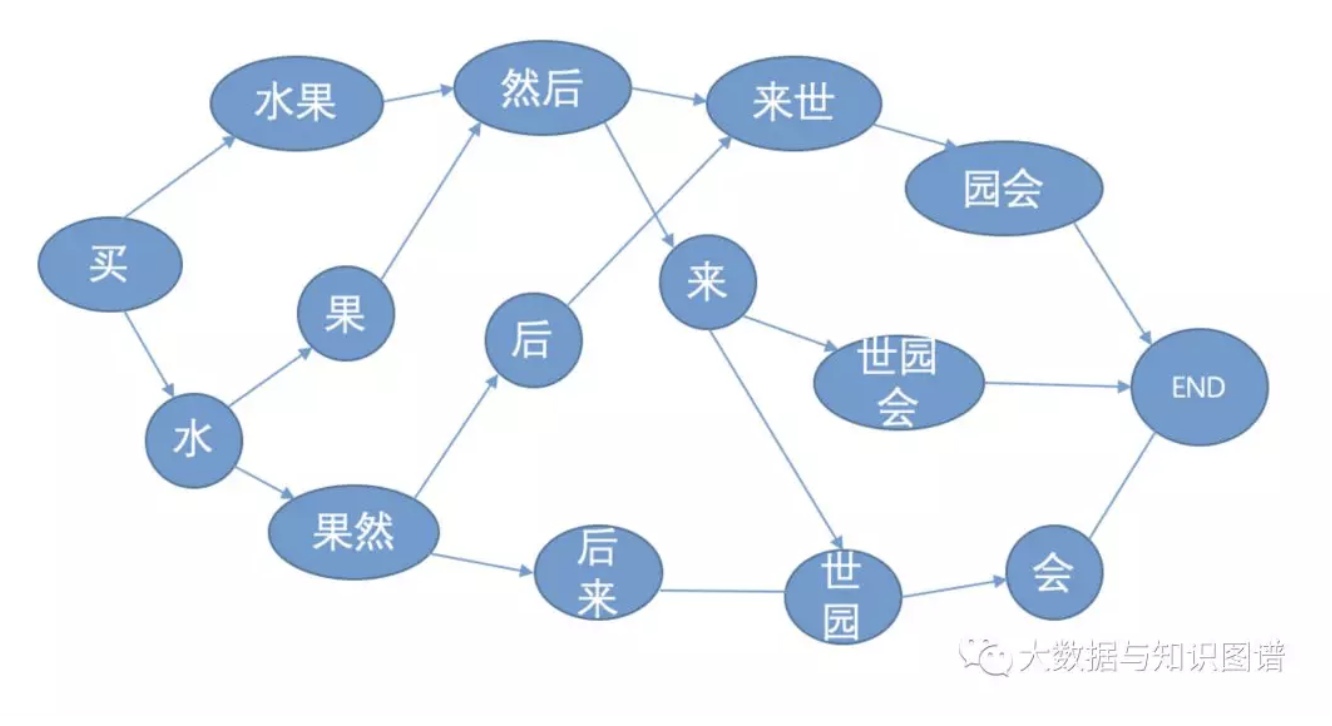
Jieba分词结合了基于规则和基于统计这两类方法。首先基于前缀词典进行词图扫描,前缀词典是指词典中的词按照前缀包含的顺序排列,例如词典中出现了“买”,之后以“买”开头的词都会出现在这一部分,例如“买水”,进而“买水果”,从而形成一种层级包含结构。若将词看成节点,词与词之间的分词符看成边,则一种分词方案对应着从第一个字到最后一个字的一条分词路径,形成全部可能分词结果的有向无环图。
jieba安装
安装很简单,先创建一个python3.6的虚拟环境,再激活环境,最后安装命令如下:
conda create -n nlp_py3 python=3.6
source activate nlp_py3
pip install jieba
jieba的三种分词模式
支持三种分词模式:
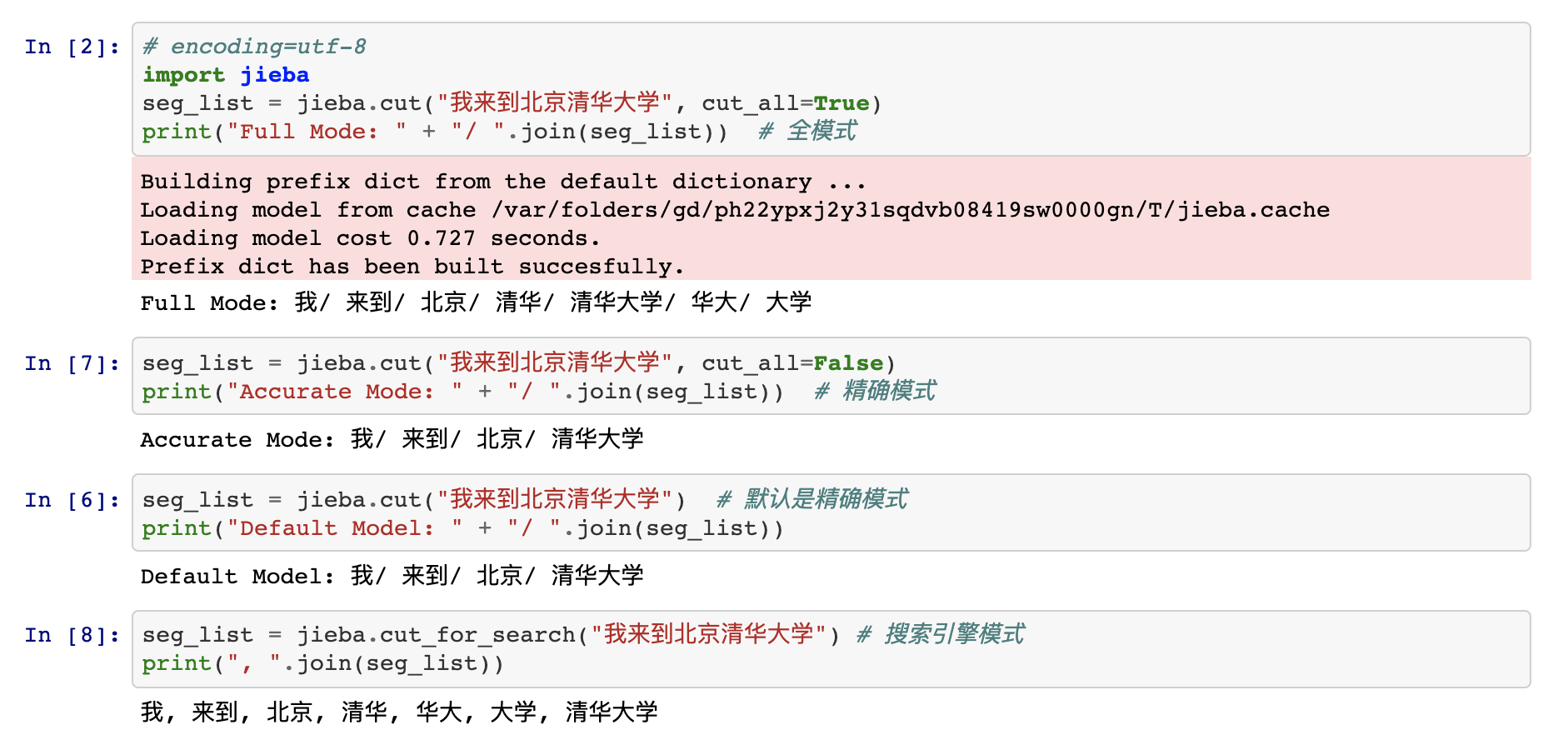
精确模式,试图将句子最精确地切开,适合文本分析。
全模式,把句子中所有的可以成词的词语都扫描出来, 速度非常快,但是不能解决歧义。
搜索引擎模式,在精确模式的基础上,对长词再次切分,提高召回率,适合用于搜索引擎分词。
支持繁体分词
支持自定义词典
MIT 授权协议
主要功能
1. 分词
- jieba.cut 方法接受三个输入参数: 需要分词的字符串;cut_all 参数用来控制是否采用全模式;HMM 参数用来控制是否使用 HMM 模型
- jieba.cut_for_search 方法接受两个参数:需要分词的字符串;是否使用 HMM(隐马尔可夫) 模型。该方法适合用于搜索引擎构建倒排索引的分词,粒度比较细
- jieba.lcut 以及 jieba.lcut_for_search 直接返回 list
执行示例:
2.添加自定义词典
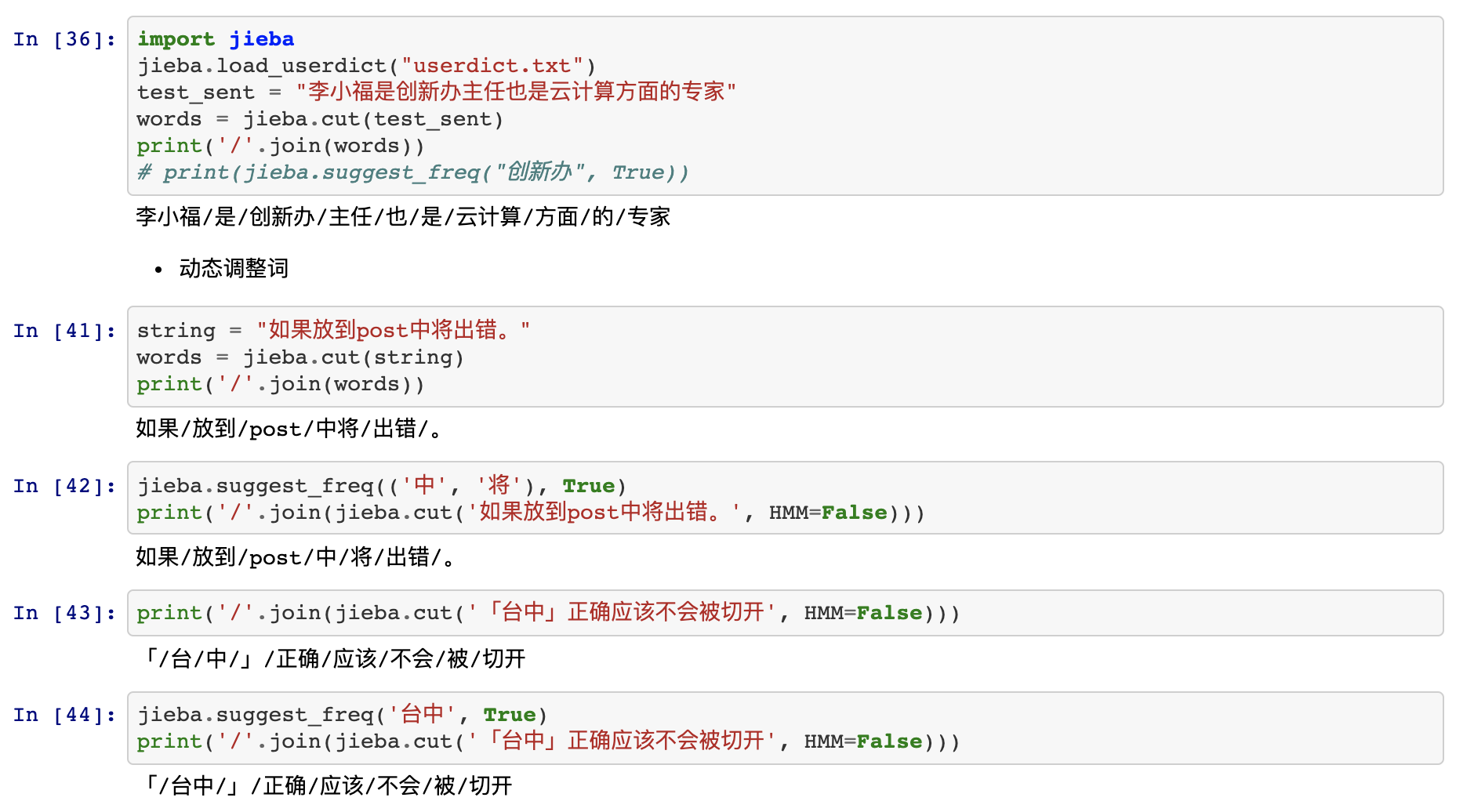
- 开发者可以指定自己自定义的词典,以便包含 jieba 词库里没有的词。虽然 jieba 有新词识别能力,但是自行添加新词可以保证更高的正确率
- 用法: jieba.load_userdict(file_name) # file_name 为文件类对象或自定义词典的路径
- 词典格式和 dict.txt 一样,一个词占一行;每一行分三部分:词语、词频(可省略)、词性(可省略),用空格隔开,顺序不可颠倒。file_name 若为路径或二进制方式打开的文件,则文件必须为 UTF-8 编码。
词频省略时使用自动计算的能保证分出该词的词频。
执行示例:
tips:
P(台中) < P(台)×P(中),“台中”词频不够导致其成词概率较低
解决方法:强制调高词频
jieba.add_word('台中')
或者
jieba.suggest_freq('台中', True)
参考官网:https://github.com/fxsjy/jieba

中文分词工具——jieba的更多相关文章
- 中文分词工具jieba中的词性类型
jieba为自然语言语言中常用工具包,jieba具有对分词的词性进行标注的功能,词性类别如下: Ag 形语素 形容词性语素.形容词代码为 a,语素代码g前面置以A. a 形容词 取英语形容词 adje ...
- 中文分词工具探析(二):Jieba
1. 前言 Jieba是由fxsjy大神开源的一款中文分词工具,一款属于工业界的分词工具--模型易用简单.代码清晰可读,推荐有志学习NLP或Python的读一下源码.与采用分词模型Bigram + H ...
- 中文分词工具简介与安装教程(jieba、nlpir、hanlp、pkuseg、foolnltk、snownlp、thulac)
2.1 jieba 2.1.1 jieba简介 Jieba中文含义结巴,jieba库是目前做的最好的python分词组件.首先它的安装十分便捷,只需要使用pip安装:其次,它不需要另外下载其它的数据包 ...
- 中文分词工具探析(一):ICTCLAS (NLPIR)
1. 前言 ICTCLAS是张华平在2000年推出的中文分词系统,于2009年更名为NLPIR.ICTCLAS是中文分词界元老级工具了,作者开放出了free版本的源代码(1.0整理版本在此). 作者在 ...
- 开源中文分词工具探析(三):Ansj
Ansj是由孙健(ansjsun)开源的一个中文分词器,为ICTLAS的Java版本,也采用了Bigram + HMM分词模型(可参考我之前写的文章):在Bigram分词的基础上,识别未登录词,以提高 ...
- 开源中文分词工具探析(四):THULAC
THULAC是一款相当不错的中文分词工具,准确率高.分词速度蛮快的:并且在工程上做了很多优化,比如:用DAT存储训练特征(压缩训练模型),加入了标点符号的特征(提高分词准确率)等. 1. 前言 THU ...
- 开源中文分词工具探析(五):FNLP
FNLP是由Fudan NLP实验室的邱锡鹏老师开源的一套Java写就的中文NLP工具包,提供诸如分词.词性标注.文本分类.依存句法分析等功能. [开源中文分词工具探析]系列: 中文分词工具探析(一) ...
- 开源中文分词工具探析(五):Stanford CoreNLP
CoreNLP是由斯坦福大学开源的一套Java NLP工具,提供诸如:词性标注(part-of-speech (POS) tagger).命名实体识别(named entity recognizer ...
- 开源中文分词工具探析(七):LTP
LTP是哈工大开源的一套中文语言处理系统,涵盖了基本功能:分词.词性标注.命名实体识别.依存句法分析.语义角色标注.语义依存分析等. [开源中文分词工具探析]系列: 开源中文分词工具探析(一):ICT ...
随机推荐
- docker 安装centos7并SSH远程连接
1.安装centos7 镜像 1.搜索并拉取centos镜像(默认最新镜像) docker search centos docker pull centos 2.建立本机对应docker-centos ...
- 练习//编写函数norepeat(arr) 将数组的重复元素去掉,并返回新的数组
function norepeat(n){ for(var i=0;i<arr.length;i++){ for(var j=i+1;j<arr.l ...
- Pycharm修改HTML模板
- 戴尔服务器ipmi报错
戴尔服务器ipmi配置完成,用浏览器打开报错 查看器已终止,网络已中断 原因:这个问题是java报错,用火狐打开报错 解决方法: 用IE打开就没问题,IE要用较高版本的,楼主的是win10-IE11
- Dubbo(七):redis注册中心的应用
上篇我们讲了Dubbo中有一个非常本质和重要的功能,那就是服务的自动注册与发现,而这个功能是通过注册中心来实现的.上篇中使用zookeeper实现了注册中心的功能,同时了提了dubbo中有其他许多的注 ...
- 转载-git使用之忽略不需要上传的文件的几种方式
在我们使用git 的时候通常会遇到一些问题,一些文件我创建了但是我并不想上传或者有些文件我修改了但是并不想上传(为了适应个自己的开发环境),但是在每次git status的时候总能看到它,不仅感到很心 ...
- LeetCode寻找两个有序数组的中位数
题目: 给定两个大小为 m 和 n 的有序数组 nums1 和 nums2. 请你找出这两个有序数组的中位数,并且要求算法的时间复杂度为 O(log(m + n)). 你可以假设 nums1 和 nu ...
- [hdu5203]计数水题
思路:把一个木棍分成3段,使之能够构成三角形的方案总数可以这样计算,枚举一条边,然后可以推公式算出当前方案数.对于已知一条边的情况,也用公式推出.用max和min并维护下,以减少情况数目. #prag ...
- shell 光标处理快捷键
Ctrl+左右键 单词之间跳转Ctrl+a跳到本行的行首, Ctrl+e则跳到页尾. Ctrl+u删除当前光标前面的文字 ctrl+k-删除当前光标后面的文字 Ctrl+w和Alt+d-对于当前的单词 ...
- linux --自已的域名无法登陆机器的解决办法:同步时间
昨天发现自己的域名无法访问host了,因此我们测试环境便无法安装,显示SSH not connectted ,随后发现时间不同步: 因此以下命令可以实现时间同步: /opt/quest/bin/vas ...