【每周小项目】使用 puppeteer 插件爬取动态网站
0. 前言
这两天对爬虫开始感兴趣,最开始是源于天涯的一个房价神贴,盖了上万层,追着读了好久。天涯网页端的“只看楼主”需要会员,手机端可以“只看楼主”,但是体验不太好,记录也不方便,于是决定把楼主发言单独爬下来,既可以保存,也可以检索。
最开始想法很简单,对每一页进行元素检索,发帖人与楼主名字匹配的,就把里面的content拷出来。
首先在网上找到的工具是cheerio插件,它在读取网站之后,将网站内容存下来,通过元素选择器进行内容选取。在使用递归后,还能解决翻页问题。
事实上也确实如此,通过简单几步操作,就把楼主的发言保存了下来,也让我对爬虫产生了兴趣。
问题
cheerio确实简单好用,在应对简单静态网页时没有问题。但对付具备一定反爬机制的网站就无能为力了。比如cheerio解决翻页问题,靠的是动态修改url链接。但是有的网站,比如我最爱的煎蛋,它的网页链接页码是乱码,就没办法实现自动翻页。再比如有的房产网站,在罗列在售资源时,为了用户体验,使用了懒加载,只有将页面滚动到底部后,才能触发加载。
以上种种实际上就是cheerio对于网页操作是无能为力的。
解决
在网上查找对付懒加载的方法时,发现了puppeteer插件。谷歌浏览器在17年自行开发了Chrome Headless特性,并与之同时推出了puppeteer,本质上就是一个不含界面的浏览器,有点像电脑的终端,所有操作都通过代码进行操作。
这样,我们就可以在对网站进行检索之前,操作指定元素滚动到底部,以触发更多信息。或者在需要翻页的时候,操作代码对翻页按钮进行点击,然后对翻页后的页面进行相关处理。
1. 下载与引包
// 下载
npm i puppeteer
// 引包
const puppeteer = require('puppeteer')
2. 使用步骤
// 将整个操作放置在一个闭包的异步函数中,以便于进行异步操作
(async () => {
// 1. 使用puppetee插件启动一个浏览器,并开启一个新页面
const brower = await puppeteer.launch({
args: ['--no-sandbox'],
dumpio: false,
headless:false, // 默认为true,设为false时,可以显示可视化浏览器界面
})
const page = await brower.newPage() // 开启一个新页面
// 2. 打开指定网页
await page.goto('http://jandan.net/ooxx', {
waitUntil: 'networkidle2' // 网络空闲说明已加载完毕
});
// 3. 对动态网站进行自动化操作,这一步是其精髓所在
// 由于我们监控的是动态网页,刚打开网页时,所需元素也许还未出现,所以需要进行监听,例如“下一页按钮”
await page.waitForSelector('a.previous-comment-page'); // 括号内是元素选择器
// 当下一页按钮出现时,模拟点击
await page.click('a.previous-comment-page')
// 4. 这时我们可以执行爬取我们需要的数据了,我们可以去审查页面的dom结果,来循环遍历这些数据。
// page.evaluate() 为在浏览器中执行函数,相当于在控制台中执行函数,返回一个 Promise
const result = await page.evaluate(() => {
// 拿到页面上的jQuery
var $ = window.$;
// 在这里进行熟悉的 DOM 操作
// Do something
});
// 5. 关闭浏览器,在console里面打印我们需要的数据
brower.close();
// 6. 对结果进行处理
console.log(result);
})();
3. 爬过的几个坑
page.evaluate 的传参问题
因为打开的这个 page 只是一个木偶,并不是真正的浏览器页面,所以在这个页面上的操作与一般页面上的操作有差异。
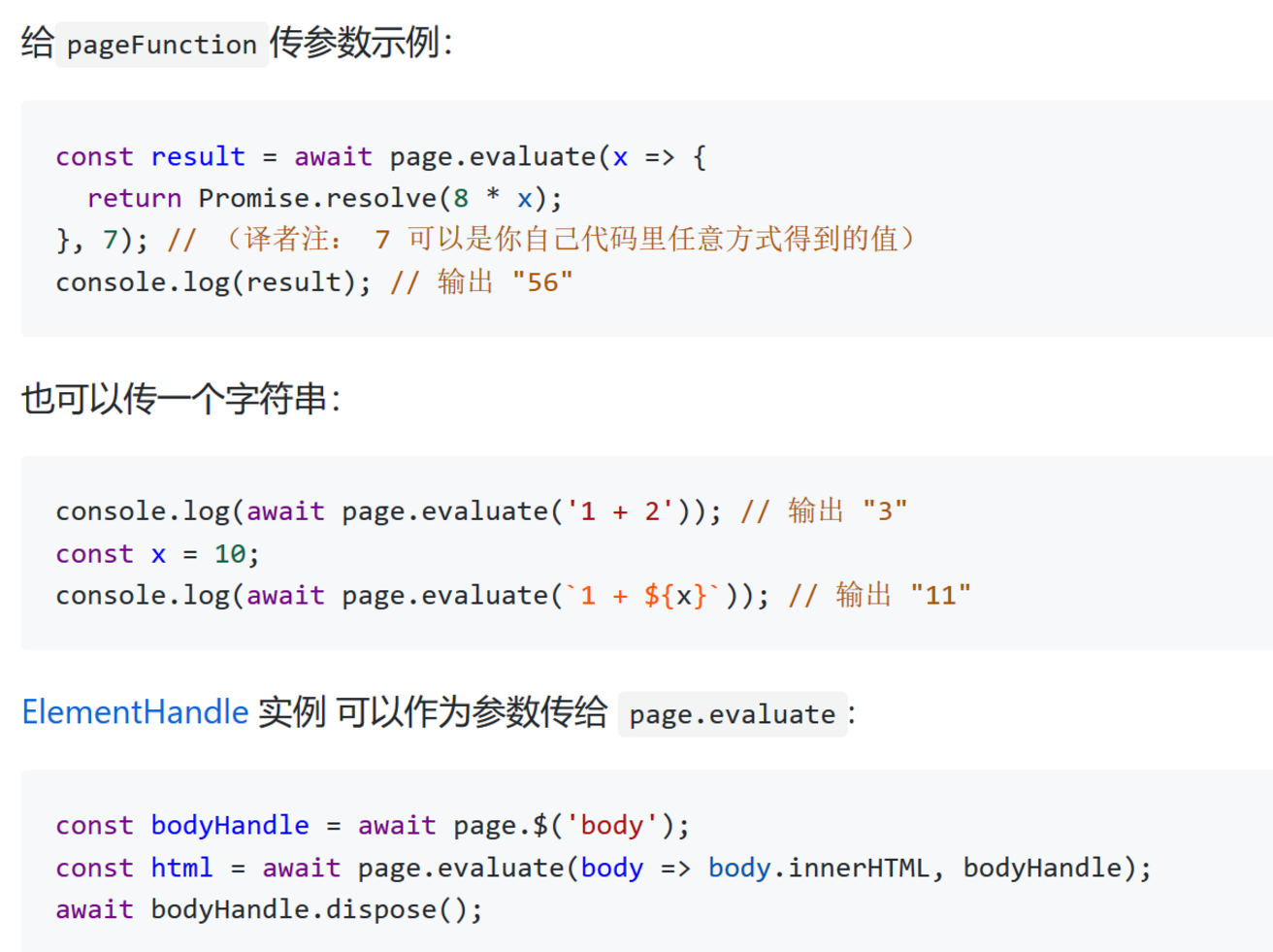
官方文档里说,这个参数是这样的。在实际使用中,可以传一个字符串变量,但是到更复杂一点的,比如‘fs’,自定义外部函数时,都无法读取。
这也是我建议在第6步,对页面操作完成后,统一对结果进行处理。(主要是因为我没有解决这个问题,所以认怂绕开走了……)
元素操作问题
puppeteer中,最重要的函数执行和要素选择都与一般浏览器上操作有些区别,这里有些坑要爬,现在我也说不清楚。
【每周小项目】使用 puppeteer 插件爬取动态网站的更多相关文章
- python3爬取动态网站图片
思路: 1.图片放在<image>XXX</image>标签中 2.利用fiddler抓包获取存放图片信息的js文件url 3.利用requests库获取html内容,然后获取 ...
- Python 爬虫练习项目——异步加载爬取
项目代码 from bs4 import BeautifulSoup import requests url_prefix = 'https://knewone.com/discover?page=' ...
- 用Python爬取斗鱼网站的一个小案例
思路解析: 1.我们需要明确爬取数据的目的:为了按热度查看主播的在线观看人数 2.浏览网页源代码,查看我们需要的数据的定位标签 3.在代码中发送一个http请求,获取到网页返回的html(需要注意的是 ...
- webmagic爬取渲染网站
最近突然得知之后的工作有很多数据采集的任务,有朋友推荐webmagic这个项目,就上手玩了下.发现这个爬虫项目还是挺好用,爬取静态网站几乎不用自己写什么代码(当然是小型爬虫了~~|). 好了,废话少说 ...
- 爬虫系列4:Requests+Xpath 爬取动态数据
爬虫系列4:Requests+Xpath 爬取动态数据 [抓取]:参考前文 爬虫系列1:https://www.cnblogs.com/yizhiamumu/p/9451093.html [分页]:参 ...
- Golang+chromedp+goquery 简单爬取动态数据
目录 Golang+chromedp+goquery 简单爬取动态数据 Golang的安装 下载golang软件 解压golang 配置golang 重新导入配置 chromedp框架的使用 实际的代 ...
- 爬虫系列2:Requests+Xpath 爬取租房网站信息
Requests+Xpath 爬取租房网站信息 [抓取]:参考前文 爬虫系列1:https://www.cnblogs.com/yizhiamumu/p/9451093.html [分页]:参考前文 ...
- 利用python的requests和BeautifulSoup库爬取小说网站内容
1. 什么是Requests? Requests是用Python语言编写的,基于urllib3来改写的,采用Apache2 Licensed 来源协议的HTTP库. 它比urllib更加方便,可以节约 ...
- phantomjs+selenium实现爬取动态网址
之前使用 selenium + firefox驱动浏览器来实现爬取动态网址,但是firefox经常更新,更新后时常会导致webdriver启动不来,所以改用phantomjs+selenium来改善一 ...
随机推荐
- 小程序打开web-view传参数注意事项
通过URL传参数过去的参数值建议使用BASE64 加密后传输 (尤其是值含有 ‘中文’,‘符号’,‘http’ 的内容) 试过使用 encodeURI, encodeURLComment ,es ...
- almost最好的Vue + Typescript系列02 项目结构篇
基于vue-cli 3.x,配合typescript的环境构建的新vue项目,跟以前的结构相比,有了一些变化,下面我们来简单的了解一下 基本结构: node_modules: 项目中安装的依赖模块 p ...
- tensorflow feature_column踩坑合集
踩坑内容包含以下 feature_column的输入输出类型,用一个数据集给出demo feature_column接estimator feature_column接Keras feature_co ...
- Flink系列之状态及检查点
Flink不同于其他实时计算的框架之处是它可以提供针对不同的状态进行编程和计算.本篇文章的主要思路如下,大家可以选择性阅读. 1. Flink的状态分类及不同点. 2. Flink针对不同的状态进行编 ...
- Effective Go中文版(更新中)
原文链接:https://golang.org/doc/effective_go.html Introduction Go是一种新兴的编程语言.虽然它借鉴了现有语言的思想,但它具有不同寻常的特性,使得 ...
- 简说python之安装
Python是跨平台程序语言,做为世界流行的语言之一,它可以平滑地部署在Windows,Linux,Mac等平台之上,并有很多第三方模块的函数可供使用. 学习Python,首先需要把Python的编译 ...
- [BUG]微信小程序生成小程序码"小程序页面路径不存在,请重新输入"
描述 小程序页面线上能打开. 微信官方 获取小程序页面小程序码 页面 ,输入 小程序页面路径,提示 "小程序页面路径不存在,请重新输入". 使用微信复制小程序路径方法, 也是同样的 ...
- 浅谈ASP.NET Core中的DI
DI的一些事 传送门马丁大叔的文章 什么是依赖注入(DI: Dependency Injection)? 依赖注入(DI)是一种面向对象的软件设计模式,主要是帮助开发人员开发出松耦合的应用程序 ...
- channel的基本使用
1.管道分类 读写管道 只读管道 只写管道 缓冲通道 :创建时指定大小(如果不指定默认为非缓冲通道) 2.正确使用管道 管道关闭后自能读,不能写 写入管道不能超过管道的容量cap,满容量还写则会阻塞 ...
- 聊一聊 React 中的 CSS 样式方案
和 Angular,Vue 不同,React 并没有如何在 React 中书写样式的官方方案,依靠的是社区众多的方案.社区中提供的方案有很多,例如 CSS Modules,styled-compone ...