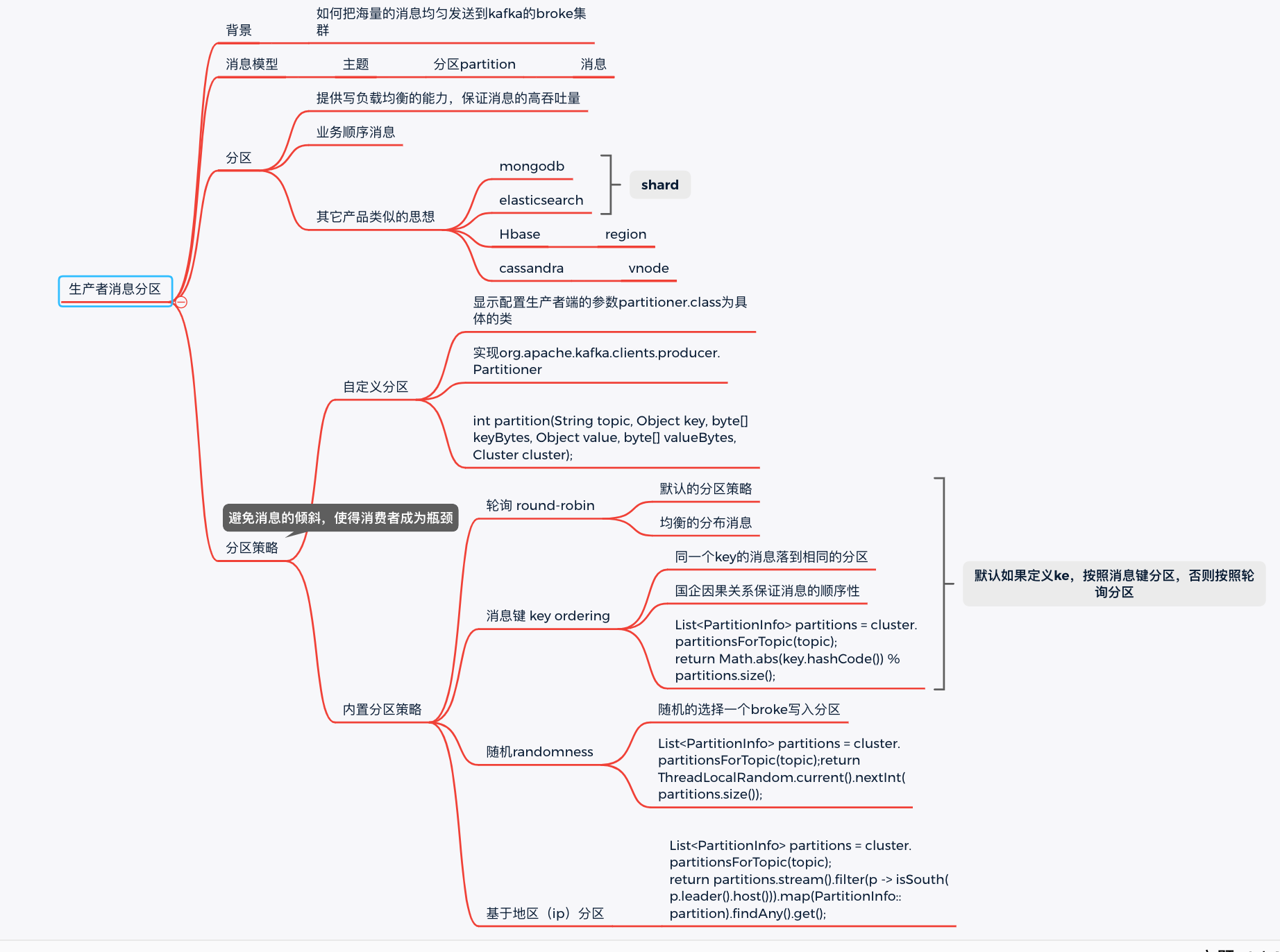
kafka消息分区机制原理
背景
kafka如何支撑海量消息的集中写入?
答案就是消息分区。
核心思想是:负载均衡,采用合适的分区策略把消息写到不同的broker上的分区中;
其它的产品中有类似的思想。
比如monogodb, es 里面叫做 shard; hbase叫region, cassdra叫vnode;
消息的三层结构
如下图:
即 topic -> partition -> message ;
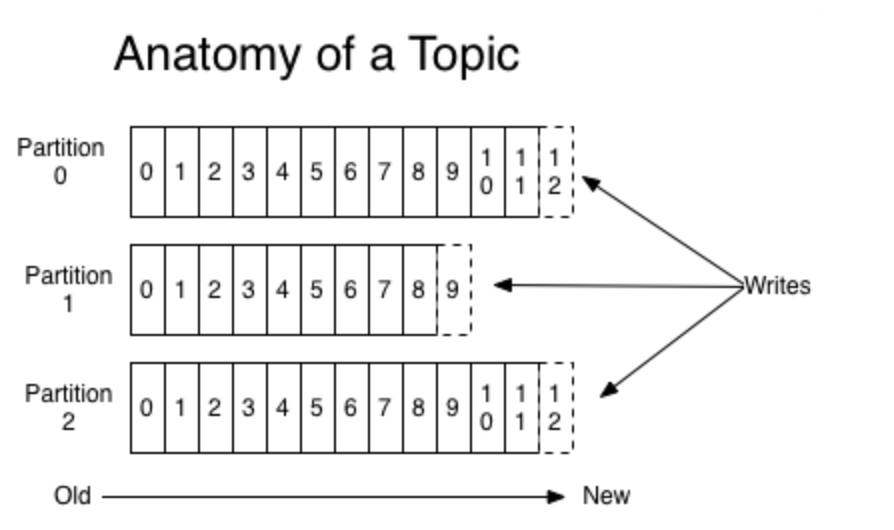
topic是逻辑上的消息容器;
partition实际承载消息,分布在不同的kafka的broke上;
message即具体的消息。
分区策略
round-robin轮询
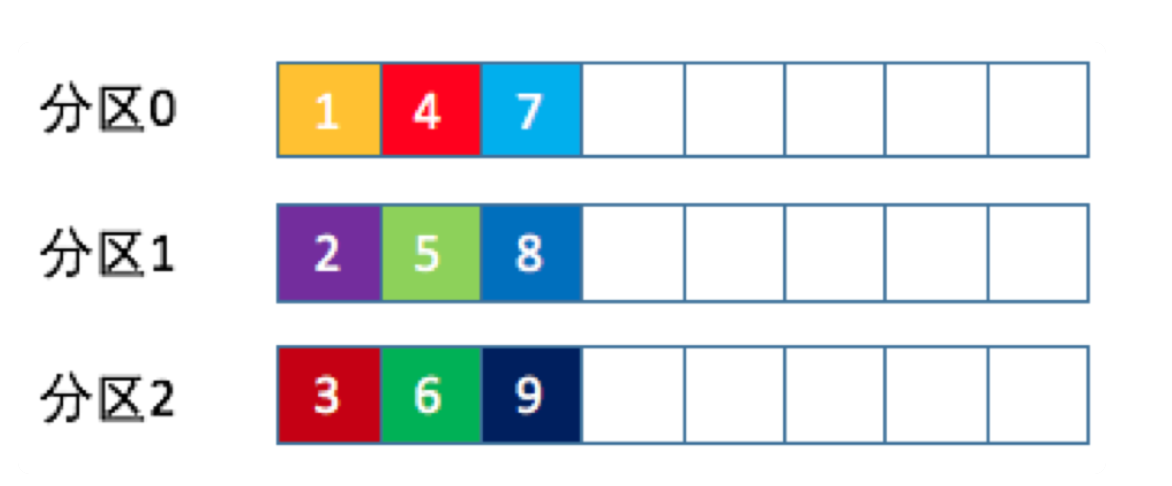
消息按照分区挨个的写。
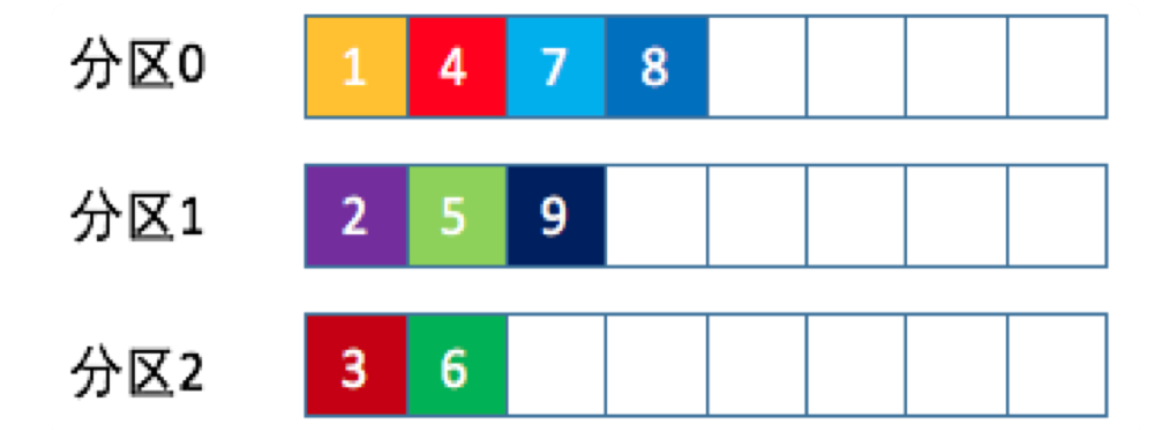
randomness随机分区
随机的找一个分区写入,代码如下:
List<PartitionInfo> partitions = cluster.partitionsForTopic(topic);
return ThreadLocalRandom.current().nextInt(partitions.size());
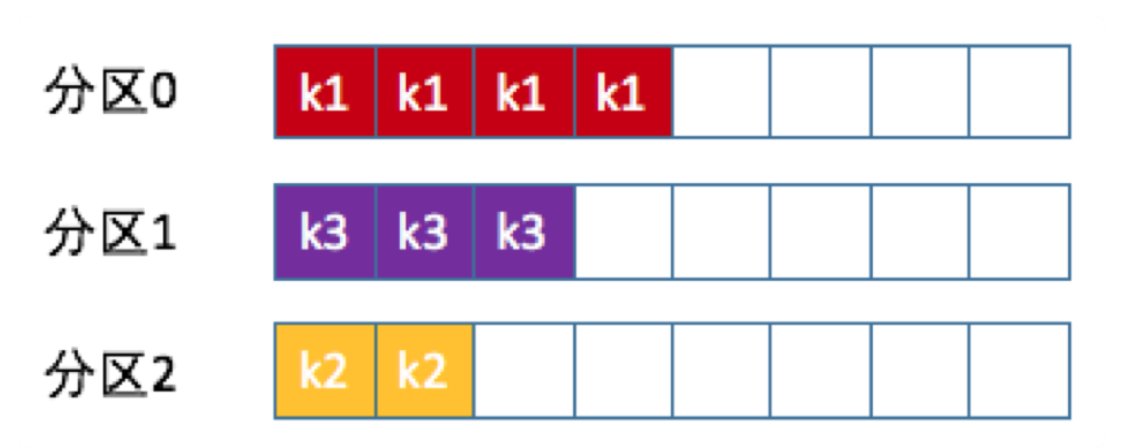
key
相同的key的消息写到固定的分区中
自定义分区
必须完成两步:
1,自定义分区实现类,需要实现org.apache.kafka.clients.producer.Partitioner接口。
主要是实现下面的方法:
int partition(String topic, Object key, byte[] keyBytes,
Object value, byte[] valueBytes, Cluster cluster);
比如按照区域分区。
List<PartitionInfo> partitions = cluster.partitionsForTopic(topic);
return partitions.stream().filter(p -> isSouth(p.leader().host()))
.map(PartitionInfo::partition).findAny().get();
2,显示配置生产者端的参数partitioner.class为具体的类
系统默认:如果消息有key,按照key分区策略,否则按照轮询策略。
小结
kafka的分区实现消息的高吞吐量的主要依托,主要是实现了写的负载均衡。可以指定各种负载均衡算法。
负载均衡算法非常重要,需要极力避免消息分区不均的情况,可能给消费者带来性能瓶颈。
小结如下:
原创不易,点赞关注支持一下吧!转载请注明出处,让我们互通有无,共同进步,欢迎沟通交流。
我会持续分享Java软件编程知识和程序员发展职业之路,欢迎关注,我整理了这些年编程学习的各种资源,关注公众号‘李福春持续输出’,发送'学习资料'分享给你!

kafka消息分区机制原理的更多相关文章
- Kafka 消息的消费原理
https://www.cnblogs.com/huxi2b/p/6061110.html 1.老版本的kafka的offset是维护在zk上的,新版本的kafka把consumer的offset维护 ...
- kafka(三)原理剖析
一.生产者消息分区机制原理剖析 在使用Kafka 生产和消费消息的时候,肯定是希望能够将数据均匀地分配到所有服务器上.比如很多公司使用 Kafka 收集应用服务器的日志数据,这种数据都是很多的,特别是 ...
- Kafka(3)--kafka消息的存储及Partition副本原理
消息的存储原理: 消息的文件存储机制: 前面我们知道了一个 topic 的多个 partition 在物理磁盘上的保存路径,那么我们再来分析日志的存储方式.通过 [root@localhost ~]# ...
- 消息队列——Kafka基本使用及原理分析
文章目录 一.什么是Kafka 二.Kafka的基本使用 1. 单机环境搭建及命令行的基本使用 2. 集群搭建 3. Java API的基本使用 三.Kafka原理浅析 1. topic和partit ...
- Kafka设计解析(八)- Exactly Once语义与事务机制原理
原创文章,首发自作者个人博客,转载请务必将下面这段话置于文章开头处. 本文转发自技术世界,原文链接 http://www.jasongj.com/kafka/transaction/ 写在前面的话 本 ...
- Kafka设计解析(八)Exactly Once语义与事务机制原理
转载自 技术世界,原文链接 Kafka设计解析(八)- Exactly Once语义与事务机制原理 本文介绍了Kafka实现事务性的几个阶段——正好一次语义与原子操作.之后详细分析了Kafka事务机制 ...
- 第1节 kafka消息队列:11、kafka的数据不丢失机制,以及kafka-manager监控工具的使用;12、课程总结
12.kafka如何保证数据的不丢失 12.1生产者如何保证数据的不丢失 kafka的ack机制:在kafka发送数据的时候,每次发送消息都会有一个确认反馈机制,确保消息正常的能够被收到 如果是同步模 ...
- Kafka消息的压缩机制
最近在做 AWS cost saving 的事情,对于 Kafka 消息集群,计划通过压缩消息来减少消息存储所占空间,从而达到减少 cost 的目的.本文将结合源码从 Kafka 支持的消息压缩类型. ...
- 深入理解 Android 消息机制原理
欢迎大家前往腾讯云社区,获取更多腾讯海量技术实践干货哦~ 作者:汪毅雄 导语: 本文讲述的是Android的消息机制原理,从Java到Native代码进行了梳理,并结合其中使用到的Epoll模型予以介 ...
随机推荐
- Springboot学习笔记【持续更新】
1.Springboot四大核心: 自动配置 与Spring应用程序和常见的应用功能,Springboot能自动提供相关配置 起步依赖 告诉Springboot需要什么功能,它就能引入需要的依赖库 A ...
- UNIX环境高级编程——TCP/IP网络编程 常用网络信息检索函数
UNIX环境高级编程——TCP/IP网络编程 常用网络信息检索函数 gethostname() getppername() getsockname() gethostbyname() ...
- iOS URL schemes
来源:知乎 launch center pro支持的参数主要有两个,[prompt]文本输入框和[clipboard]剪贴板 淘宝宝贝搜索 taobao://http://s.taobao.com/? ...
- 莎士比亚电路ヾ(≧▽≦*)o
偶尔记录一件有趣的事儿! 这个电路叫做 "莎士比亚电路"[1],请自行参悟,ヾ(≧▽≦)o,ヾ(≧▽≦)o,ヾ(≧▽≦*)o ヾ(≧▽≦*)o . <穿越计算机的迷雾> ...
- Eclipse无法查看第三方jar包源代码解决
我在csdn写了过了:https://blog.csdn.net/weixin_40404606/article/details/105174820
- mybatis 源码赏析(一)sql解析篇
本系列主要分为三部分,前两部分主要分析mybatis的实现原理,最后一部分结合spring,来看看mybtais是如何与spring结合的就是就是mybatis-spring的源码. 相较于sprin ...
- python—json
一.json数据类型:是字符串 # json通用数据类型,所有语言都可以用 # {k-v}形式存在,里面只能用双引号"" # 定义json字符串,要用'''{}'''格式 #htt ...
- AngularJS插件使用---angular-cookies.js
首先在项目中引入angular-cookies.js angular模块中添加依赖:‘ngCookies’ 在控制器中依赖注入$cookies,使用$cookies操作cookie $cookiesP ...
- Material Design 组件之 CollapsingToolbarLayout
CollapsingToolbarLayout 主要用于实现一个可折叠的标题栏,一般作为 AppBarLayout 的子 View 来使用,下面总结一下 CollapsingToolbarLayout ...
- 【原创】Linux RCU原理剖析(一)-初窥门径
背景 Read the fucking source code! --By 鲁迅 A picture is worth a thousand words. --By 高尔基 说明: Kernel版本: ...