kafka消息分区机制原理
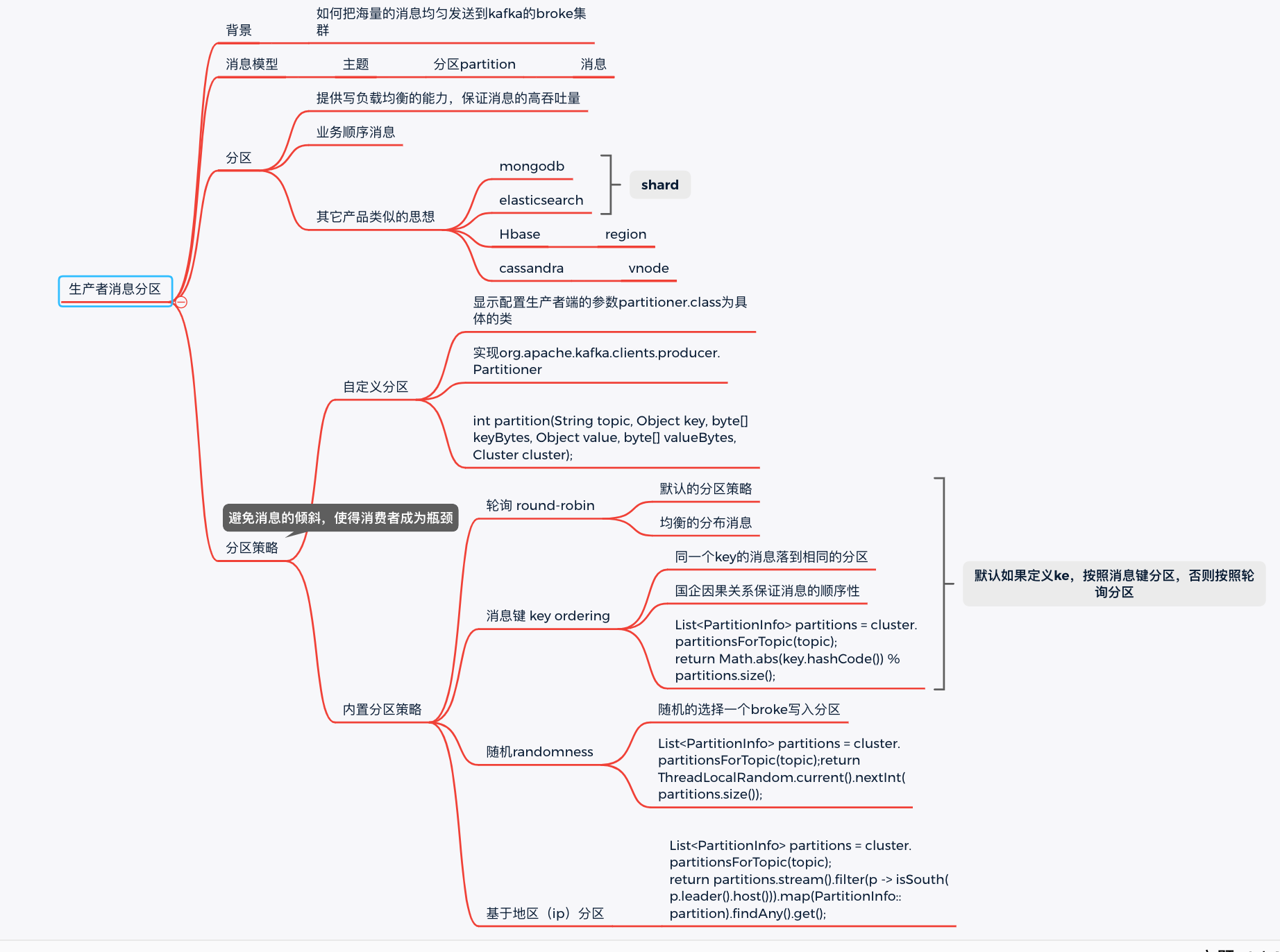
背景
kafka如何支撑海量消息的集中写入?
答案就是消息分区。
核心思想是:负载均衡,采用合适的分区策略把消息写到不同的broker上的分区中;
其它的产品中有类似的思想。
比如monogodb, es 里面叫做 shard; hbase叫region, cassdra叫vnode;
消息的三层结构
如下图:
即 topic -> partition -> message ;
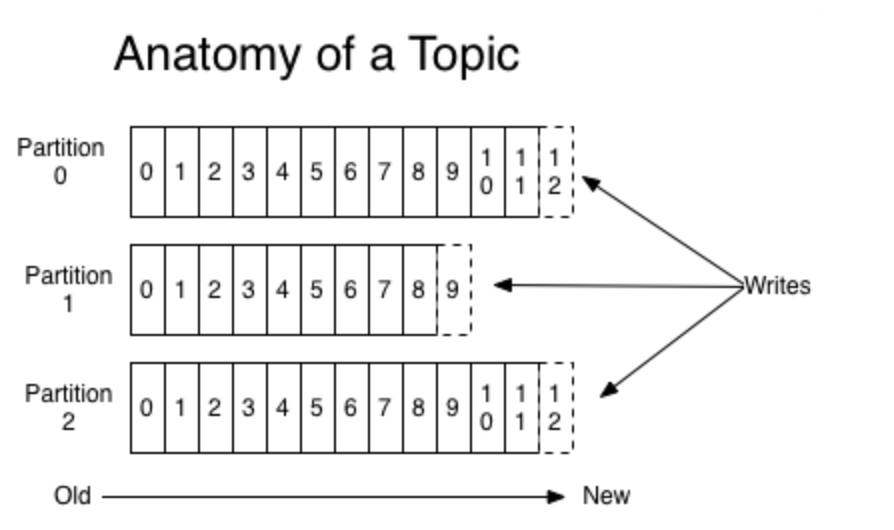
topic是逻辑上的消息容器;
partition实际承载消息,分布在不同的kafka的broke上;
message即具体的消息。
分区策略
round-robin轮询
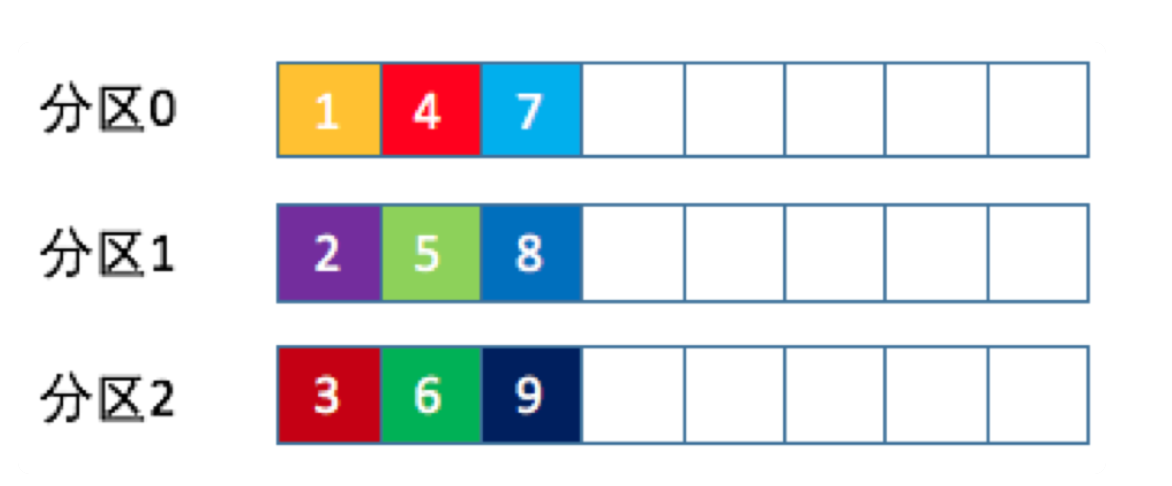
消息按照分区挨个的写。
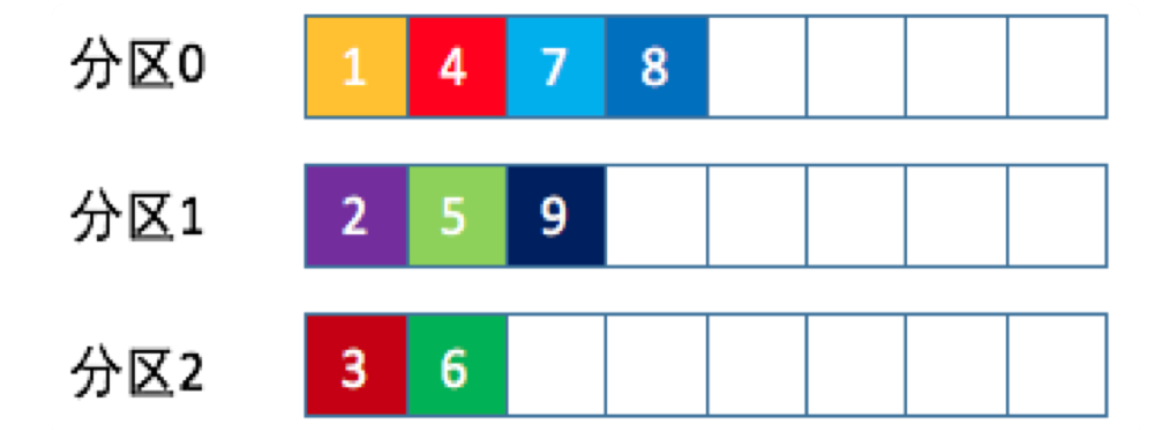
randomness随机分区
随机的找一个分区写入,代码如下:
List<PartitionInfo> partitions = cluster.partitionsForTopic(topic);
return ThreadLocalRandom.current().nextInt(partitions.size());
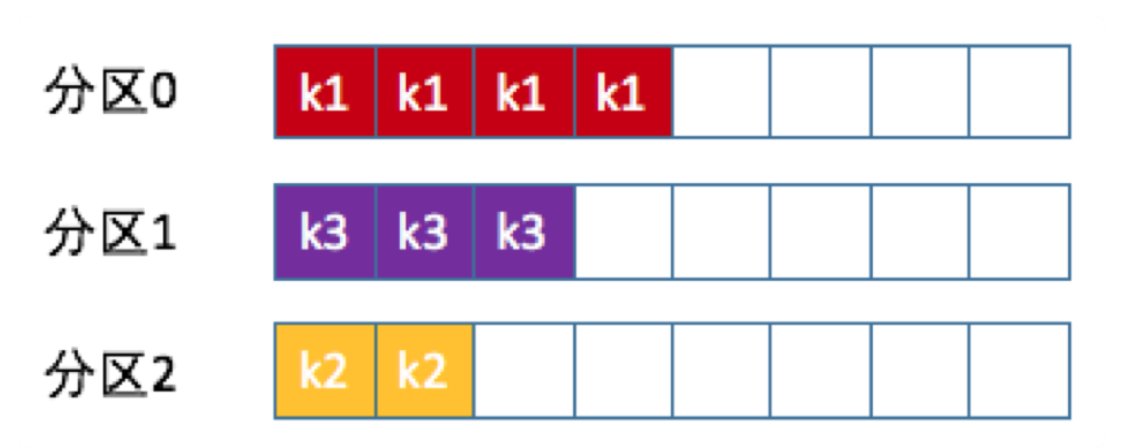
key
相同的key的消息写到固定的分区中
自定义分区
必须完成两步:
1,自定义分区实现类,需要实现org.apache.kafka.clients.producer.Partitioner接口。
主要是实现下面的方法:
int partition(String topic, Object key, byte[] keyBytes,
Object value, byte[] valueBytes, Cluster cluster);
比如按照区域分区。
List<PartitionInfo> partitions = cluster.partitionsForTopic(topic);
return partitions.stream().filter(p -> isSouth(p.leader().host()))
.map(PartitionInfo::partition).findAny().get();
2,显示配置生产者端的参数partitioner.class为具体的类
系统默认:如果消息有key,按照key分区策略,否则按照轮询策略。
小结
kafka的分区实现消息的高吞吐量的主要依托,主要是实现了写的负载均衡。可以指定各种负载均衡算法。
负载均衡算法非常重要,需要极力避免消息分区不均的情况,可能给消费者带来性能瓶颈。
小结如下:
原创不易,点赞关注支持一下吧!转载请注明出处,让我们互通有无,共同进步,欢迎沟通交流。
我会持续分享Java软件编程知识和程序员发展职业之路,欢迎关注,我整理了这些年编程学习的各种资源,关注公众号‘李福春持续输出’,发送'学习资料'分享给你!

kafka消息分区机制原理的更多相关文章
- Kafka 消息的消费原理
https://www.cnblogs.com/huxi2b/p/6061110.html 1.老版本的kafka的offset是维护在zk上的,新版本的kafka把consumer的offset维护 ...
- kafka(三)原理剖析
一.生产者消息分区机制原理剖析 在使用Kafka 生产和消费消息的时候,肯定是希望能够将数据均匀地分配到所有服务器上.比如很多公司使用 Kafka 收集应用服务器的日志数据,这种数据都是很多的,特别是 ...
- Kafka(3)--kafka消息的存储及Partition副本原理
消息的存储原理: 消息的文件存储机制: 前面我们知道了一个 topic 的多个 partition 在物理磁盘上的保存路径,那么我们再来分析日志的存储方式.通过 [root@localhost ~]# ...
- 消息队列——Kafka基本使用及原理分析
文章目录 一.什么是Kafka 二.Kafka的基本使用 1. 单机环境搭建及命令行的基本使用 2. 集群搭建 3. Java API的基本使用 三.Kafka原理浅析 1. topic和partit ...
- Kafka设计解析(八)- Exactly Once语义与事务机制原理
原创文章,首发自作者个人博客,转载请务必将下面这段话置于文章开头处. 本文转发自技术世界,原文链接 http://www.jasongj.com/kafka/transaction/ 写在前面的话 本 ...
- Kafka设计解析(八)Exactly Once语义与事务机制原理
转载自 技术世界,原文链接 Kafka设计解析(八)- Exactly Once语义与事务机制原理 本文介绍了Kafka实现事务性的几个阶段——正好一次语义与原子操作.之后详细分析了Kafka事务机制 ...
- 第1节 kafka消息队列:11、kafka的数据不丢失机制,以及kafka-manager监控工具的使用;12、课程总结
12.kafka如何保证数据的不丢失 12.1生产者如何保证数据的不丢失 kafka的ack机制:在kafka发送数据的时候,每次发送消息都会有一个确认反馈机制,确保消息正常的能够被收到 如果是同步模 ...
- Kafka消息的压缩机制
最近在做 AWS cost saving 的事情,对于 Kafka 消息集群,计划通过压缩消息来减少消息存储所占空间,从而达到减少 cost 的目的.本文将结合源码从 Kafka 支持的消息压缩类型. ...
- 深入理解 Android 消息机制原理
欢迎大家前往腾讯云社区,获取更多腾讯海量技术实践干货哦~ 作者:汪毅雄 导语: 本文讲述的是Android的消息机制原理,从Java到Native代码进行了梳理,并结合其中使用到的Epoll模型予以介 ...
随机推荐
- ASP.NET Core AutoWrapper 自定义响应输出
前言 AutoWrapper是一个简单可自定义全局异常处理程序和ASP.NET Core API响应的包装.他使用ASP.NET Core middleware拦截传入的HTTP请求,并将最后的结果使 ...
- mycat主要参数
以下内容源于mycat官方文档,记录下来方便直接查看: mycat版本:1.6 负载均衡类型,目前的取值有 3 种:1. balance="0", 不开启读写分离机制,所有读操作都 ...
- Building Applications with Force.com and VisualForce(Dev401)( 八):Designing Applications for Multiple users:Managing your users' experience II
Dev 401-008: Design Applications for Multiple Users' Experience Part 2Universal Containers Scenario1 ...
- Google AI推出新的大规模目标检测挑战赛
来源 | Towards Data Science 整理 | 磐石 就在几天前,Google AI在Kaggle上推出了一项名为Open Images Challenge的大规模目标检测竞赛.当今计算 ...
- TensorFlow系列专题(二):机器学习基础
欢迎大家关注我们的网站和系列教程:http://www.tensorflownews.com/ ,学习更多的机器学习.深度学习的知识! 目录: 数据预处理 归一化 标准化 离散化 二值化 哑编码 特征 ...
- jmeter参数化之函数助手(十五)
jmeter-参数化: 参数化的作用:调用接口入参时.有时要求参数经常变化,如果每次去修改就会变得很繁琐,这时候就需要把经常变化的值改变为提前编辑好的文档或函数中,便于调用时使用不同的值. Jmete ...
- 计算机视觉基本原理——RANSAC
公众号[视觉IMAX]第31篇原创文章 一 前言 对于上一篇文章——一分钟详解「本质矩阵」推导过程中,如何稳健地估计本质矩阵或者基本矩阵呢?正是这篇文章重点介绍的内容. 基本矩阵求解方法主要有: 1) ...
- [hdu1269]城堡迷宫<tarjan强连通分量>
题目链接:http://acm.hdu.edu.cn/showproblem.php?pid=1269 tarjan算法是oi里很常用的一个算法,在理解方面需要多下一些功夫,如果不行直接记模板也行,因 ...
- 2.1.JVM的垃圾回收机制,判断对象是否死亡
因为热爱,所以坚持. 文章下方有本文参考电子书和视频的下载地址哦~ 这节我们主要讲垃圾收集的一些基本概念,先了解垃圾收集是什么.然后触发条件是什么.最后虚拟机如何判断对象是否死亡. 一.前言 我们 ...
- 错误:Attempt to resolve method: [XXX方法] on undefined variable or class name: [XXX类]的解决(IDEA打包jar问题)
问题: 使用JMeter调用jar包的时候,报错误信息Typed variable declaration : Attempt to resolve method:[XXX方法] on undefin ...