Kubernetes 持久化存储是个难题,解决方案有哪些?\n
像Kubernetes 这样的容器编排工具正在彻底改变应用程序的开发和部署方式。随着微服务架构的兴起,以及基础架构与应用程序逻辑从开发人员的角度解耦,开发人员越来越关注构建软件和交付价值。
Kubernetes 对管理的物理机器进行抽象。使用Kubernetes,你可以通过描述获取所需的内存总量和计算能力,而无需担心底层基础架构。
在管理Docker 镜像时,Kubernetes 还让应用程序变得可移植。一旦使用Kubernetes 开发容器化架构,它们就可以部署在任何地方 - 公有云、混合云、本地 - 无需对底层代码进行任何更改。
虽然Kubernetes 在许多方面非常有用,例如可伸缩性、可移植性和管理能力,但它不支持存储状态。几乎所有的生产应用程序都是有状态的,即需要某种外部存储。
Kubernetes 的架构是不断变化的。容器的创建和销毁,取决于负载和开发人员的规范。容器组和容器可以自我修复和复制。从本质上讲,它们的生命周期是短暂的。
但是,持久化存储解决方案无法承受这种动态行为。持久化存储不能绑定到动态创建和销毁的规则上。
当有状态应用需要部署在另一个基础架构,可能是另一个云提供商、本地或混合模型上时,它们在可移植性方面面临挑战。持久化存储解决方案会绑定到特定的云提供商。
此外,云原生应用程序的存储版图不容易理解。Kubernetes 存储术语可能会造成混淆,因为许多术语都有复杂的含义和微妙的变化。此外,在做出决策之前,开发人员必须考虑许多选项,包括原生Kubernetes、开源框架、托管或付费服务。
在下面的CNCF 版图中可以看到列出的云原生存储解决方案:

首先想到的可能就是在Kubernetes 中部署数据库:选择适合你需求的数据库解决方案,将其容器化并在本地磁盘上运行,然后将其作为另一个工作负载部署在集群中。但是,由于数据库的固有属性,这种方法不是特别好。
容器是基于无状态原则构建的。这使得容器很容易进行伸缩。由于不需要保存和迁移数据,通常来说,集群不需要处理很密集的磁盘读写操作。
使用数据库,需要保存状态。如果数据库以容器方式部署在集群上,不进行迁移或者频繁伸缩,那么实际的数据存储将起作用。理想情况下,将使用数据的容器与数据库位于同一个容器中。
这并不是说在容器中部署数据库是一个坏主意 - 在某些用例中,这种方法可能就足够了。在测试环境中,或者对于不需要生产级数据量的任务,由于所保存的数据规模较小,因此集群中的数据库可能是有意义的。
在生产中,开发人员通常依赖外部存储。
Kubernetes 如何与存储通信?它使用控制平面接口。这些接口将Kubernetes 与外部存储相关联。这些与Kubernetes 连接的外部存储解决方案称为卷插件。卷插件可以抽象存储并赋予存储可移植性。
以前,卷插件使用Kubernetes 核心代码库构建、链接、编译和发布。这极大地限制了开发人员的灵活性,并带来了额外的维护成本。添加新的存储选项需要更改Kubernetes 代码库。
通过引入CSI 和Flexvolume,可以在集群上部署卷插件,而无需更改代码库。
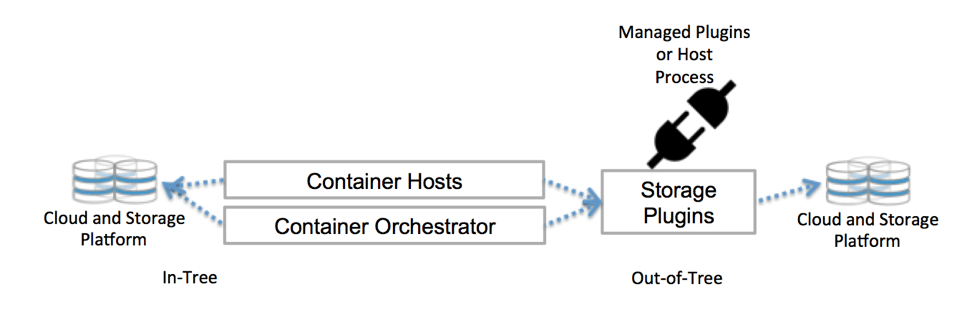
Kubernetes 原生和存储
Kubernetes 原生如何处理存储?Kubernetes 自身提供了一些管理存储的解决方案:临时选项、持久化存储卷、持久化存储卷声明、存储类和有状态副本集。这可能很混乱。
持久化存储卷(PV)是由管理员配置的存储单元。它们独立于任何一个容器组,使它们摆脱容器组的短暂生命周期。
另一方面,持久化存储卷声明(PVC)是对存储的请求,即PVs。使用PVC,可以将存储绑定到特定节点,使其可供该节点使用。
有两种处理存储的方法:静态和动态。
采用静态配置,管理员在实际请求之前,为他们认为可能需要的容器组提供PVs,并且通过明确指定的PVCs,将这些PV 手动绑定到指定的容器组。
实际上,静态定义的PV 与Kubernetes 的可移植结构不兼容,因为正在使用的存储可能依赖于环境,例如AWS EBS 或GCE Persistent Disk。手动绑定需要更改YAML 文件以指向特定供应商的存储解决方案。
在开发人员如何考虑资源方面,静态配置也违背了Kubernetes 的思维方式:CPU 和内存未事先分配并绑定到容器组或容器。它们是动态授予的。
动态配置使用存储类完成。集群管理员无需事先手动创建PV。他们改为创建多个存储配置文件,就像模板一样。当开发人员创建PVC 时,根据请求的要求,在请求时创建其中一个模板,并将其附加到容器组。
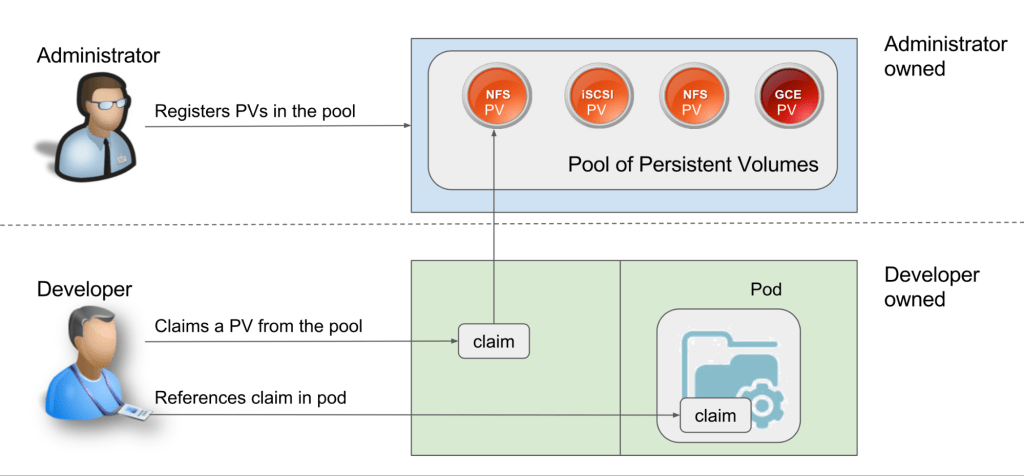
这是对外部存储通常如何使用原生Kubernetes 进行处理的一个宽泛的概述。但是,还有许多其他选择需要考虑。
CSI - 容器存储接口
在继续之前,我想介绍容器存储接口(CSI)。CSI 是由CNCF 存储工作组创建的统一工作,旨在定义标准容器存储接口,使存储驱动程序能够在任何容器编排器上工作。
CSI 规范已经适用于Kubernetes,并且在Kubernetes 集群上有大量驱动程序插件可供部署。开发人员可以Kubernetes 上使用CSI 卷类型访问CSI 兼容卷驱动程序公开的存储。
随着CSI 的引入,存储可以被视为另一个工作负载容器化,并在Kubernetes 集群上部署。
开源项目
围绕云原生技术的工具和项目大幅增加。作为生产环境中最突出的问题之一,有相当多的开源项目致力于解决云原生架构上的存储问题。
关于存储的最受欢迎的项目是Ceph 和Rook。
Ceph是一个动态管理,可水平扩展的分布式存储集群。Ceph 提供了对存储资源的逻辑抽象。它被设计为没有单点故障,可自我管理并基于软件。Ceph 为同一存储集群同时提供块、对象和文件系统接口。
Ceph 的架构很复杂,有许多底层技术,如RADOS、librados、RADOSGW、RDB、CRUSH 算法,以及监视器、OSD和MDS等组件。Ceph 是一个分布式存储集群,不需要深入研究其体架构,关键在于,它是一个分布式存储集群,可以更轻松地实现可扩展性,在不牺牲性能的情况下消除单点故障,并提供了对对象、块和文件的访问的统一存储。
当然,Ceph 已经适应了云原生环境。可以通过多种方式部署Ceph 集群,例如使用Ansible。可以从Kubernetes 集群中使用CSI 和PVC 接口访问部署的Ceph 集群。
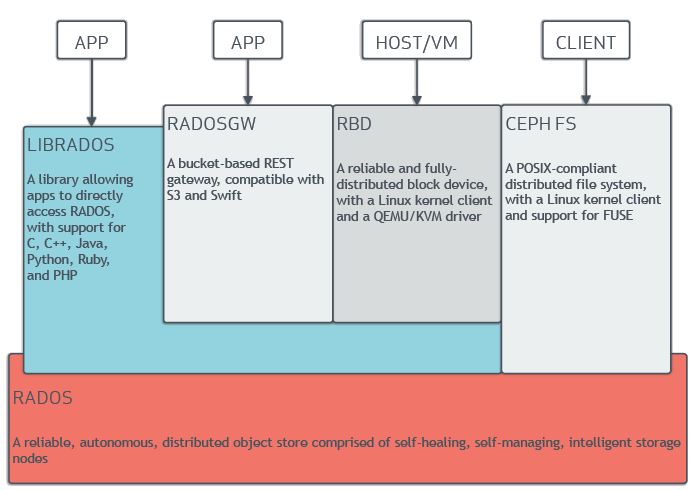
另一个有趣且颇受欢迎的项目是Rook,一个旨在融合Kubernetes 和Ceph 的工具 - 将计算和存储集中在一个集群中。
Rook是一个云原生存储编排器。它扩展了Kubernetes。Rook 本质上允许将Ceph 放入容器中,并提供集群管理逻辑,以便在Kubernetes 上可靠地运行Ceph。Rook 自动化部署、引导、配置、扩展、负载均衡,即集群管理员需要做的工作。
Rook 允许通过yaml 文件部署Ceph 集群,就像Kubernetes 一样。此文件用作集群管理员在集群中所需内容的高级声明。Rook 整合集群,并开始积极监控。Rook 充当运维人员或控制器,确保yaml 文件中声明的期望状态得到保证。Rook 在一个协调循环中运行,观察状态并根据检测到的差异采取行动。
Rook 没有自己的持久化状态,也不需要管理。它的确是根据Kubernetes 的原则构建的。
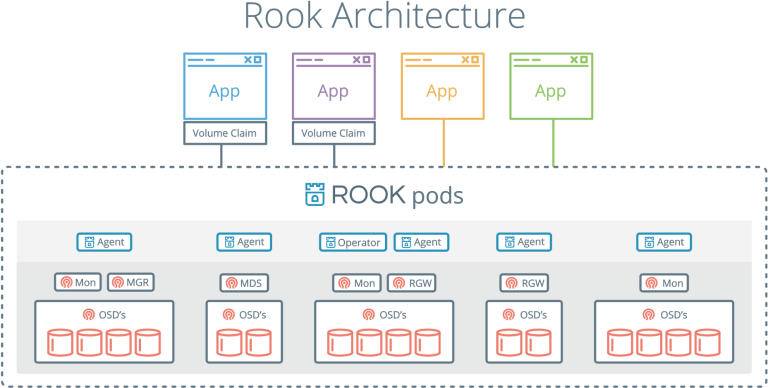
Rook 将Ceph 和Kubernetes 结合在一起,是最受欢迎的云原生存储解决方案之一,在Github 上拥有近4000 颗星,1630万 下载量和100多名贡献者。
作为被CNCF 接受的首个存储项目,Rook 近期已进入孵化阶段。
对于应用程序中的任何问题,确定需求,设计系统和选择相应工具非常重要。云原生环境中的存储也不例外。虽然问题非常复杂,但仍有许多工具和方法。随着云原生世界的发展,无疑也会出现新的解决方案。
查看英文原文:https://softwareengineeringdaily.com/2019/01/11/why-is-storage-on-kubernetes-is-so-hard/
https://softwareengineeringdaily.com/2019/01/07/stateful-kubernetes-with-saad-ali/
https://i2.wp.com/softwareengineeringdaily.com/wp-content/uploads/2018/05/logo.png
Kubernetes 持久化存储是个难题,解决方案有哪些?\n的更多相关文章
- Kubernetes持久化存储2——探究实验
目录贴:Kubernetes学习系列 一.简介 本文在“创建PV,创建PVC挂载PV,创建POD挂载PVC”这个环境的基础上,进行各种删除实验,并记录.分析各资源的状态. 二.实验脚本 实验创建了一个 ...
- Kubernetes持久化存储1——示例
目录贴:Kubernetes学习系列 一.简介 存储管理与计算管理是两个不同的问题.Persistent Volume子系统,对存储的供应和使用做了抽象,以API形式提供给管理员和用户使用.要完成这一 ...
- Kubernetes 学习(十)Kubernetes 容器持久化存储
0. 前言 最近在学习张磊老师的 深入剖析Kubernetes 系列课程,最近学到了 Kubernetes 容器持久化存储部分 现对这一部分的相关学习和体会做一下整理,内容参考 深入剖析Kuberne ...
- kubernetes学习 做持久化存储
本节演示如何为 MySQL 数据库提供持久化存储,步骤: 1.创建 PV 和 PVC 2.部署 MySQL 3.向 MySQL 添加数据 4.模拟节点宕机故障,Kubernetes 将 MySQL 自 ...
- 使用Ceph集群作为Kubernetes的动态分配持久化存储(转)
使用Docker快速部署Ceph集群 , 然后使用这个Ceph集群作为Kubernetes的动态分配持久化存储. Kubernetes集群要使用Ceph集群需要在每个Kubernetes节点上安装ce ...
- Kubernetes 系列(六):持久化存储 PV与PVC
在使用容器之后,我们需要考虑的另外一个问题就是持久化存储,怎么保证容器内的数据存储到我们的服务器硬盘上.这样容器在重建后,依然可以使用之前的数据.但是显然存储资源和 CPU 资源以及内存资源有很大不同 ...
- Kubernetes 使用 ceph-csi 消费 RBD 作为持久化存储
原文链接:https://fuckcloudnative.io/posts/kubernetes-storage-using-ceph-rbd/ 本文详细介绍了如何在 Kubernetes 集群中部署 ...
- Kubernetes之持久化存储
转载自 https://blog.csdn.net/dkfajsldfsdfsd/article/details/81319735 ConfigMap.Secret.emptyDir.hostPath ...
- Kubernetes的故事之持久化存储(十)
一.Storage 1.1.Volume 官网网址:https://kubernetes.io/docs/concepts/storage/volumes/ 通过官网说明大致总结下就是这个volume ...
随机推荐
- jQuery和Vue的技术优劣对比
1.精力集中. Jq偏重于对dom的操作,由它的函数就很容易看出来,$().parent().find().我们用jq的时候经常要去考虑怎么去渲染数据,怎么从视图中取到数据,操作数据前必须对dom节点 ...
- Scratch 怎么打开SB文件怎么打开
扩展名是.sb( )的文件均可以用匹配版本的scratch或比匹配版本高的scratch打开,列表如下:类型 可打开.sb ···1.4(1.3).sb2 ···2.0.sb3··· 3.0或3.0b ...
- Docker多网卡
# 查看所有网络 docker network ls # 如果要查看更加详细的虚拟网卡,如下指令 docker network inspect [NetWorkEthName | NetWorkEth ...
- docker 私有仓库 删除镜像
1.查找官方删除法 https://github.com/burnettk/delete-docker-registry-image 2.民用删除法 https://segmentfault.com/ ...
- Linux网络安全篇,配置Yum源(二),阿里Yum源
官网教程: https://opsx.alibaba.com/mirror 1.下载配置文件到 /etc/yum.repos.d 目录 wget -O /etc/yum.repos.d/CentOS- ...
- 22.4 Extends --super 和 this 的区别
/* * this和super的区别 this:当前对象的引用 调用子类的成员变量 调用子类的成员方法 在子类的构造方法第一行调用子类其他构造方法 super:子类对象的父类引用 调用父类的成员变量 ...
- Python Requests-学习笔记(2)
你也许经常想为URL的查询字符串(query string)传递某种数据.如果你是手工构建URL, 那么数据会以键/值 对的形式置于URL中,跟在一个问号的后面.例如,httpbin.org/get? ...
- vue 中 history 模式的配置和打包
在使用 vue 进行项目开发中,默认的路由形式是 hash,表现形式就是 url 中始终带有 # 号,在后台管理类的项目中并不影响使用,但是在特殊场景,比如微信分享的H5链接中,微信会自动拼接参数,由 ...
- STC15F2K60S2串口通信的应用。
前言:由于不可抗拒因素,初始的STC12C5A60S2芯片由于无法进行烧录(...因为没带有锁紧座的开发板),暂且使用STC15F2K60S2芯片.. 一 串行通信概述: 串口通信有SPI IIC U ...
- web中拖拽排序与java后台交互实现
一.业务需求 1,在后台的管理界面通过排序功能直接进入排序界面 2,在排序界面能够人工的手动拖动需要排序的标题,完成对应的排序之后提交 3,在app或者是前端就有对应的排序实现了 二.页面展示 将整体 ...