大数据篇:YARN
大数据篇:YARN

YARN是什么?
YARN是一种新的 Hadoop 资源管理器,它是一个通用资源管理系统,可为上层应用提供统一的资源管理和调度,它的引入为集群在利用率、资源统一管理和数据共享等方面带来了巨大好处。
如果没有YARN!
- 无法管理集群资源分配问题。
- 无法合理的给程序分配合理的资源。
- 不方便监控程序的运行状态及日志。
1 YARN概念
1.1 基本架构

- ResourceManager
- 整个集群只有一个,负责集群资源的统一管理和调度
- 处理客户端请求,启动/监控ApplicationMaster
- 监控NodeManager,汇总上报资源
- 资源分配与调度
- NodeManager
- 整个集群有多个(每个从属节点一个)
- 单个节点上的资源管理和任务管理
- 监控资源使用情况(cpu,memory,disk,network)并向ResourceManager汇报
- 基本思想衍进
- 在MapReduce1.0中 JobTracker = 资源管理器 + 任务调度器
- 拥有yarn后,将资源管理器,任务调度器做了切分
- 资源管理
- 让ResourceManager负责
- 任务调度
- 让ApplicationMaster负责
- 每个作业启动一个
- 根据作业切分任务的tasks
- 向ResourceManager申请资源
- 与NodeManager协作,将分配申请到的资源给内部任务tasks
- 监控tasks运行情况,重启失败的任务
- 让ApplicationMaster负责
- 资源管理
- JobHistoryServer
- 每个集群每种计算框架一个
- 负责搜集归档所有的日志
- Container
- 计算资源抽象为Container
- 任务运行资源(节点、内存、CPU)
- 任务启动命令
- 任务运行环境
1.2 基本架构 YARN运行过程剖析

1. 客户端发送请求,由Resource Manager分析需要多少内存资源。
2. Resource Manager告诉Node Manager用什么样的jar包什么样的启动命令。
3. Node Manager创建Container,在Container启动Application Master。
4. Application Master向Resource Manager发送ResourceRequest请求去Resource Manager申请资源
5. 启动对应的Node Manager进行通信
6. Node Manager找到对应的Container执行Task
1.3 YARN容错性
- 失败类型
- 程序失败 进程崩溃 硬件问题
- 如果作业失败了
- 作业异常会汇报给Application Master
- 通过心跳信号检查挂住的任务
- 一个作业的任务失败比例超过配置,就会认为该任务失败
- 如果Application Master失败了
- Resource Manager接收不到心跳信号时会重启Application Master
- 如果Node Manager失败了
- Resource Manager接收不到心跳信号时会将其移出
- Resource Manager接收Application Master,让Application Master决定任务如何处理
- 如果某个Node Manager失败任务次数过多,Resource Manager调度任务时不再其上面运行任务
- 如果Resource Manager运行失败
- 通过checkpoint机制,定时将其状态保存到磁盘,失败的时候,重新运行
- 通过Zooleeper同步状态和实现透明的HA
1.4 YARN调度框架
- 双层调度框架
- RM将资源分配给AM
- AM将资源进一步分配给各个Task
- 基于资源预留的调度策略
- 资源不够时,会为Task预留,直到资源充足
- 与“all or nothing”策略不同(Apache Mesos)

1.5 YARN资源调度算法
集群资源调度器需要解决:
- 多租户(Multi-tenancy):
- 多用户同时提交多种应用程序
- 资源调度器需要解决如何合理分配资源
- 可扩展性:增加集群机器数量可以提高整体集群性能。
- 多租户(Multi-tenancy):
Yarn使用列队解决多租户中共享资源的问题
root
|---prd
|---dev
|---eng
|---science
支持三种资源调度器(yarn.resourcemanager.scheduler.class)

FIFO
- 所有向集群提交的作业使用一个列队
- 根据提交作业的顺序来运行(先来先服务)
- 优点:简单,可以按照作业优先级调度
- 缺点:资源利用率不高,不允许抢占
Capacity Scheduler
设计思想:资源按照比例分配给各个列队
计算能力保证:以列队为单位划分资源,每个列队最低资源保证
灵活:当某个列队空闲时,其资源可以分配给其他的列队使用
支持优先级:单个列队内部使用的就是FIFO,支持作业优先级调度
多租户:
- 考虑多种因素防止单个作业,用户列队独占资源
- 每个列队可以配置一定比例的最低资源配置和使用上限
- 每个列队有严格的访问控制,只能向自己列队提交任务
基于资源调度:支持内存资源调度和CPU资源的调度
从2.8.0版本开始支持抢占
root
|---prd 70%
|---dev 30%
|---eng 50%
|---science 50%
Fair Scheduler(推荐)
- 设计思想:资源公平分配
- 具有与Capacity Scheduler相似的特点
- 树状队列
- 每个列队有独立的最小资源保证
- 空闲时可以分配资源给其他列队使用
- 支持内存资源调度和CPU资源调度
- 支持抢占
- 不同点
- 核心调度策略不同
- Capacity Scheduler优先选择资源利用率低的列队
- 公平调度器考虑的是公平,公平体现在作业对资源的缺额
- 单独设置列队间资源分配方式
- FAIR(只考虑Mamory)
- DRF(主资源公平调度,共同考虑CPU和Mamory)
- 单独设置列队内部资源分配方式
- FAIR DRF FIFO
- 核心调度策略不同
多类型资源调度
- 采用DRF算法(论文:“Dominant Resource Fairness: Fair Allocation of
Multiple Resource Types”) - 目前支持CPU和内存两种资源
- 采用DRF算法(论文:“Dominant Resource Fairness: Fair Allocation of
多租户资源调度器
- 支持资源按比例分配
- 支持层级队列划分方式
- 支持资源抢占
配置案例


调用Wordcount案例,看看效果吧
hadoop jar /opt/cloudera/parcels/CDH-6.2.0-1.cdh6.2.0.p0.967373/lib/hadoop-mapreduce/hadoop-mapreduce-examples-3.0.0-cdh6.2.0.jar wordcount -Dmapreduce.job.queuename="root.default" /word.txt /output #任务2将会失败root.users is not a leaf queue,有了自列队就不能提交
hadoop jar /opt/cloudera/parcels/CDH-6.2.0-1.cdh6.2.0.p0.967373/lib/hadoop-mapreduce/hadoop-mapreduce-examples-3.0.0-cdh6.2.0.jar wordcount -Dmapreduce.job.queuename="root.users" /word.txt /output1 hadoop jar /opt/cloudera/parcels/CDH-6.2.0-1.cdh6.2.0.p0.967373/lib/hadoop-mapreduce/hadoop-mapreduce-examples-3.0.0-cdh6.2.0.jar wordcount -Dmapreduce.job.queuename="root.users.dev" /word.txt /output2 hadoop jar /opt/cloudera/parcels/CDH-6.2.0-1.cdh6.2.0.p0.967373/lib/hadoop-mapreduce/hadoop-mapreduce-examples-3.0.0-cdh6.2.0.jar wordcount -Dmapreduce.job.queuename="root.users.test" /word.txt /output3
1.6 YARN资源隔离方案
- 支持内存和CPU两种资源隔离
- 内存是一种“决定生死”的资源
- CPU是一种“影响快慢”的资源
- 内存隔离
- 基于线程监控的方案
- 基于Cgroups的方案
- CPU隔离
- 默认不对CPU资源进行隔离
- 基于Cgroups的方案
1.7 YARN支持的调度语义
- 支持的语义
- 请求某个特定节点/机架上的特定资源量
- 将某些节点加入(或移除)黑名单,不再为自己分配这些节点上的资源
- 请求归还某些资源
- 不支持的语义
- 请求任意节点/机架上的特定资源量
- 请求一组或几组符合某种特质的资源
- 超细粒度资源
- 动态调整Container资源
1.8 YARN常用命令
- 列出所有的Application: yarn application -list
- 根据Application状态过滤: yarn application -list -appStates ACCEPTED
- Kill掉Application: yarn application -kill [ApplicationId]
- 查看Application日志: yarn logs -applicationId [ApplicationId]
- 查询Container日志:yarn logs -applicationId [ApplicationId] -containerId [containerId] -nodeAddress [nodeAddress]
- 配置是配置文件中:yarn.nodemanager.webapp.address参数指定
2 Hadoop YARN应用
2.1 应用程序种类繁多

2.2 YARN设计目标
- 通用的统一资源管理系统
- 同时运行长应用程序和短应用程序
- 长应用程序
- 通常情况下,永不停止运行的程序
- Service、HTTP Server等
- 短应用程序
- 短时间(秒级、分钟级、小时级)内会运行结束的程序
- MR job、Spark Job等
2.3 以YARN为核心的生态系统

2.4 运行在YARN上的计算框架
- 离线计算框架:MapReduce
- DAG计算框架:Tez
- 流式计算框架:Storm
- 内存计算框架:Spark
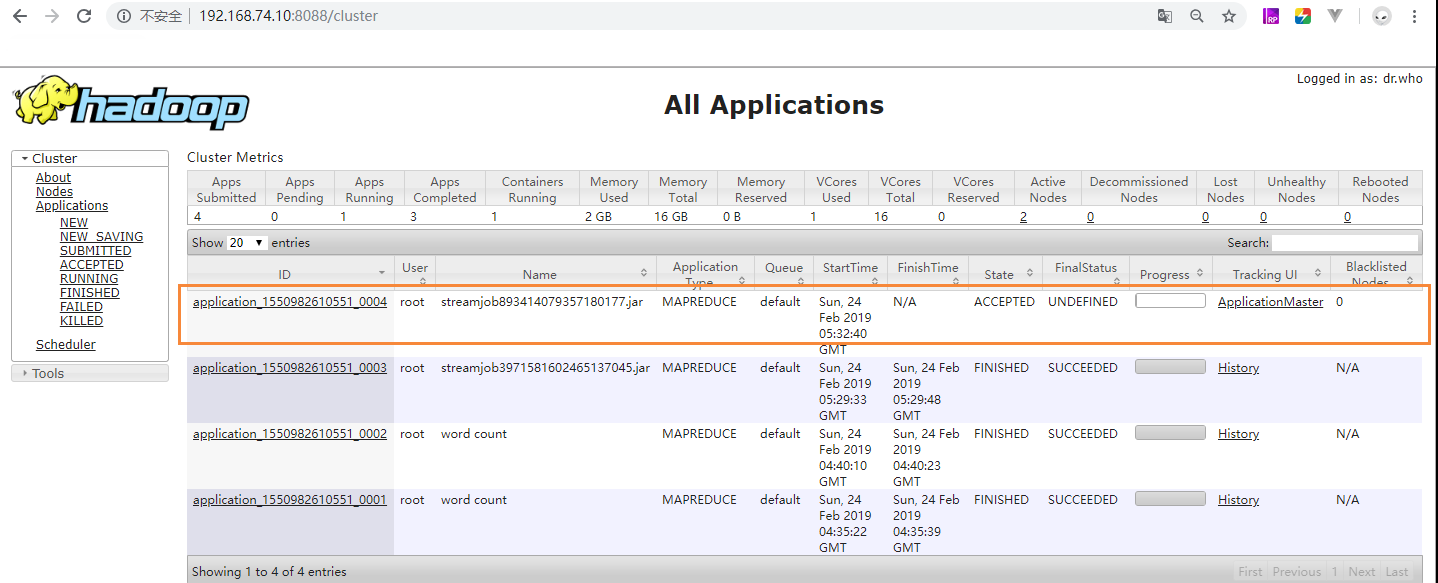
3 监控页面
4 YARN HA

从图中看出yarn的HA相对于HDFS的HA简单很多。原因是YARN在开发的过程中,HDFS才考虑到HA的应用(在出2.0版本),HDFS为了老代码的兼容性,和新代码的可拓展性加入了ZKFailoverController(ZKFC)来处理ZK相关的业务。而YARN就直接将ZK的相关的业务规划进了源架构中,所以架构图看起来比HDFS HA简单很多。
4.1 CDH中YARN配置HA

也很简单,一步完成。
5 参数调优
5.1 内存利用优化
- yarn.nodemanager.resource.memory-mb
单个节点可用内存,表示该节点上YARN可使用的物理内存总量。
- yarn.scheduler.maximum-allocation-mb
单个任务可申请的最多物理内存量
一般出现资源不够的情况就需要调整上述两个参数,比如前面来了1个G数据,分成10个块,每一个map占用1G内存,那么需要10G,4个reduce任务一个1G内存,这时候yarn.scheduler.maximum-allocation-mb参数就必须大于14G,而如果有2个这种任务,那么yarn.nodemanager.resource.memory-mb参数就必须大于28G。
大数据篇:YARN的更多相关文章
- 大数据篇:Zookeeper
Zookeeper 1 Zookeeper概念 Zookeeper是什么 是一个基于观察者设计模式的分布式服务管理框架,它负责和管理需要关心的数据,然后接受观察者的注册,一旦这些数据的状态发生变化,Z ...
- 大数据篇:Hive
大数据篇:Hive hive.apache.org Hive是什么? Hive是Facebook开源的用于解决海量结构化日志的数据统计,是基于Hadoop的一个数据仓库工具,可以将结构化的数据文件映射 ...
- 大数据篇:Spark
大数据篇:Spark Spark是什么 Spark是一个快速(基于内存),通用,可扩展的计算引擎,采用Scala语言编写.2009年诞生于UC Berkeley(加州大学伯克利分校,CAL的AMP实验 ...
- 大数据篇:MapReduce
MapReduce MapReduce是什么? MapReduce源自于Google发表于2004年12月的MapReduce论文,是面向大数据并行处理的计算模型.框架和平台,而Hadoop MapR ...
- 大数据篇:ElasticSearch
ElasticSearch ElasticSearch是什么 ElasticSearch是一个基于Lucene的搜索服务器.它提供了一个分布式多用户能力的全文搜索引擎,基于RESTful web接口. ...
- 大数据篇:Hbase
大数据篇:Hbase Hbase是什么 Hbase是一个分布式.可扩展.支持海量数据存储的NoSQL数据库,物理结构存储结构(K-V). 如果没有Hbase 如何在大数据场景中,做到上亿数据秒级返回. ...
- 大数据篇:一文读懂@数据仓库(PPT文字版)
大数据篇:一文读懂@数据仓库 1 网络词汇总结 1.1 数据中台 数据中台是聚合和治理跨域数据,将数据抽象封装成服务,提供给前台以业务价值的逻辑概念. 数据中台是一套可持续"让企业的数据用起 ...
- NanoProfiler - 适合生产环境的性能监控类库 之 大数据篇
上期回顾 上一期:NanoProfiler - 适合生产环境的性能监控类库 之 基本功能篇 上次介绍了NanoProfiler的基本功能,提到,NanoProfiler实现了MiniProfiler欠 ...
- 大数据篇:HDFS
HDFS HDFS是什么? Hadoop分布式文件系统(HDFS)是指被设计成适合运行在通用硬件(commodity hardware)上的分布式文件系统(Distributed File Syste ...
随机推荐
- Object的rest和spread方法
//将多个对象合并到一个对象里 const input = { a: 1, b: 2 } const test = { d: 5 } const output = { ...input, ...tes ...
- buuctf 二维码
首先下载文件 然后用解压工具解压之后 发现是一个二维码 扫描二维码 并没有拿到 flag 然后将图片拖进 hxd中搜索PK发现有一个压缩包 将压缩包提取出来 暴力破解 然后得到密码 然后解压 然后得 ...
- kill pkill
首先说一下kill命令,它是通过pid(进程ID)来杀死进程,要得到某个进程的pid,我们可以使用ps(process status)命令,默认情况下,kill命令发送给进程的终止信号是15,但是有些 ...
- vue音乐播放器
利用vue写一个简单的音乐播放器,包括功能有歌曲搜索.歌曲播放.歌曲封面.歌曲评论.播放动画.mv播放六个功能. <template> <div class="wrap&q ...
- 【Python】爬虫原理
前言 简单来说互联网是由一个个站点和网络设备组成的大网,我们通过浏览器访问站点,站点把HTML.JS.CSS代码返回给浏览器,这些代码经过浏览器解析.渲染,将丰富多彩的网页呈现我们眼前: 一.爬虫是什 ...
- concat merge
# concat import numpy as np import pandas as pd from pandas import Series,DataFrame df1 = DataFrame( ...
- pwnable.kr-flag-Writeup
MarkdownPad Document *:first-child { margin-top: 0 !important; } body>*:last-child { margin-botto ...
- python基础之函数,递归,内置函数
一.数学定义的函数与python中的函数 初中数学函数定义:一般的,在一个变化过程中,如果有两个变量x和y,并且对于x的每一个确定的值,y都有唯一确定的值与其对应,那么我们就把x称为自变量,把y称为因 ...
- Plastic Bottle Manufacturer: Characteristic Analysis Of Plastic Packaging Bottles
Plastic packaging bottles are usually made of 7 materials. Due to its inherent characteristics, the ...
- 《实战Java高并发程序设计》读书笔记五
第五章 并行模式与算法 1.单例模式 是一种对象创建模式,用于产生一个对象的具体实例,它可以确保系统一个类只产生一个实例. 对于频繁创建使用的对象可以省略new 操作花费的时间,可以减少系统开销. 由 ...