一步一步理解AdaBoosting(Adaptive Boosting)算法
最近学习《西瓜书》的集成学习之Boosting算法,看了一个很好的例子(https://zhuanlan.zhihu.com/p/27126737),为了方便以后理解,现在更详细描述一下步骤。
AdaBoosting(Adaptive Boosting)算法本质思想如下:
以最大准确率拟合第一个学习器;
第二个需要修正第一个的错误:筛选出错误并把它们放大;
第三个再修正之前的错误;
重复以上步骤,直到学习器数目达事先指定的值,再将这些学习器进行加权结合。
给定数据集如下:

注:
1)y的取值只有1和-1,没有其他任何值。
准备工作:
现在我们要选一个threshold值使得这个数据集最后的预测结果误差最小。
比如选threshold =0.5
如果有选择器规则,所有(x>0.5)都被判定为-1,(x<0.5)都被判定为1 。这样明显可以看出x = 1/2/6/7/8都是被预测错误,错误率达到了0.5 。
按照这样的方法,来计算出每个threshold对应的错误是多少,如下图:

再如选threshold =0.5
如果有另一个选择器规则,所有(x<0.5)都被判定为-1,(x>0.5)都被判定为1 。这样明显可以看出x = 0/3/4/5/9都是被预测错误,错误率达到了0.5 。
按照这样的方法,来计算出每个threshold对应的错误是多少,如下图:

了解这些之后,进入第一轮学习器建立过程。
===========================第m=1个学习器学习过程:=================================================================================
第m=1个学习器学习过程:
w是指每个数据的权重,最开始我们没有任何信息的时候默认权重一样,即1/n(n是样本数据个数)。
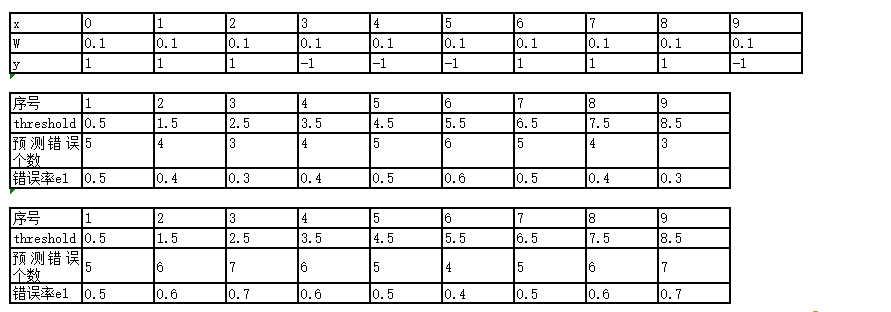
错误率e1:是由相应的权重之和得到的。
找到错误率最小的,显然当Threshold = 2.5时, 此时x= 6/7/8 出错,错误率e1 = 0.1+0.1+0.1(即权重w之和)。
也即学习器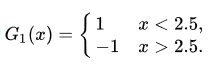
根据e1计算出学习器系数alpha1 = 0.4236。公式为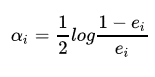
很简单推导可以得出这个式子中,当(ei<1/2),(alphai>0)是有意义的。
根据以下式子开始推导下一轮的数据权重:
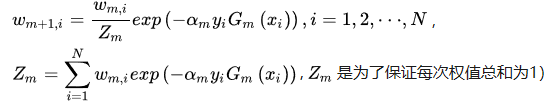
那么我们先算Zm(第一轮学习器的权重跟新总和):在本轮中有三个数据权重需要增大,剩下七个数据权重减小。
Z1 = 0.13exp(alpha1)+ 0.17exp(0-alpha1) = 3exp( 0.4236 ) +7exp(0 - 0.4236)
W10=W11=W12=W13=W14=W15=W19 = 0.1* 3exp(alpha1)/Z1 = 0.13exp(0.4236)/Z1 = 0.07143
W16=W17=W18 = 0.13exp(0 - alpha1)/Z1 = 0.13*exp(0 - 0.4236)/Z1 = 0.16667
更新后的详细权重如下:

此时更新之后的假设算法和学习器关系为:

根据得到的算法使用最初的数据集发现还是并不能很好地预测出分类,所以还要继续学习过程
===========================第m=2个学习器学习过程:=================================================================================

显然在threshold = 8.5时,错误率最小,可以得到x = 3/4/5的时候出现了错误,错误率e2 = 0.07143+0.07143+0.07143 = 0.21429,alpha2 = 0.6496。
此时学习器为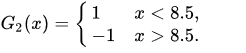
更新权值分布方式如下:
Z2 = 0.0714exp(alpha2 )+0.0714exp(alpha2 )+0.0714exp(alpha2 )+0.0714exp(0 - alpha2 )+
0.0714exp(0 - alpha2 )+0.0714exp(0 - alpha2 )+0.16667exp(alpha2 ) + 0.16667exp(alpha2 )+ 0.16667exp(alpha2 )+0.0714exp(alpha2 )
W20=W21=W22=W29 = 0.0714exp(alpha2 )/Z2 = 0.0455
W23=W24=W25= 0.0714exp(0 - alpha2 )/Z2 = 0.16667
W26=W27=W28 = 0.16667*exp(alpha2 )/Z2 = 0.1060
更新之后的权重如下:

此时更新之后的假设算法和学习器关系为:

注:在(x>8.5)的分段,我认为应该是(0.6496(-1)+0.4236(-1)= --1.0723)但是这里不影响最终的sign[f(x)]结果
根据得到的算法使用最初的数据集发现还是并不能很好地预测出分类,所以还要继续学习过程
===========================第m=3个学习器学习过程:=================================================================================
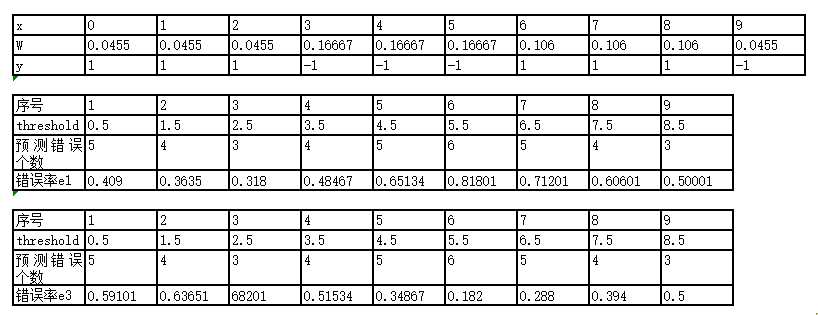
显然在threshold = 5.5时,x =1/2/3/9预测错误 ,错误率最小e3 = 0.182,alpha3 = 0.7514。
此时的学习器为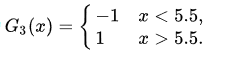
然后来继续更新权值:
Z3=0.0455exp(0 - alpha3 )+0.0455exp(0 - alpha3 )+0.0455exp(0 - alpha3 )+0.16667exp(alpha3 )+0.16667exp(alpha3 )+0.16667exp(alpha3 )+0.1060exp(alpha3 )+0.1060exp(alpha3 )+0.1060exp(alpha3 )+0.0455exp(0 - alpha3 )
W30 = W31=W32= W39 = 0.0455exp(0 - alpha3 )/Z3 = 0.125
W33=W34=W35=0.16667exp(alpha3 )/Z3 = 0.102
W36=W37=W38 = 0.1060*exp(alpha3 )/Z3 = 0.065
更新之后的权重如下:

此时更新之后的假设算法和学习器关系为:

根据得到的算法使用最初的数据集发现可以很好地预测出分类,所以结束学习过程
===========================以上结束=================================================================================
最后扩展内容:
1.Gradient-Boosting
2.在这里我们每个学习器使用的是很简单的sign函数,事实上,更多使用决策树来训练每个基学习器。
3.python实现还没完成
一步一步理解AdaBoosting(Adaptive Boosting)算法的更多相关文章
- 一步一步理解GB、GBDT、xgboost
GBDT和xgboost在竞赛和工业界使用都非常频繁,能有效的应用到分类.回归.排序问题,虽然使用起来不难,但是要能完整的理解还是有一点麻烦的.本文尝试一步一步梳理GB.GBDT.xgboost,它们 ...
- 一步一步理解Paxos算法
一步一步理解Paxos算法 背景 Paxos 算法是Lamport于1990年提出的一种基于消息传递的一致性算法.由于算法难以理解起初并没有引起人们的重视,使Lamport在八年后重新发表到 TOCS ...
- 一步一步的理解C++STL迭代器
一步一步的理解C++STL迭代器 "指针"对全部C/C++的程序猿来说,一点都不陌生. 在接触到C语言中的malloc函数和C++中的new函数后.我们也知道这两个函数返回的都是一 ...
- 一步一步理解 python web 框架,才不会从入门到放弃 -- 开始使用 Django
背景知识 要使用 Django,首先必须先安装 Django. 下图是 Django 官网的版本支持,我们可以看到上面有一个 LTS 存在.什么是 LTS 呢?LTS ,long-term suppo ...
- 一步一步理解线段树——转载自JustDoIT
一步一步理解线段树 目录 一.概述 二.从一个例子理解线段树 创建线段树 线段树区间查询 单节点更新 区间更新 三.线段树实战 -------------------------- 一 概述 线段 ...
- NLP(二十九)一步一步,理解Self-Attention
本文大部分内容翻译自Illustrated Self-Attention, Step-by-step guide to self-attention with illustrations and ...
- 一步一步理解word2Vec
一.概述 关于word2vec,首先需要弄清楚它并不是一个模型或者DL算法,而是描述从自然语言到词向量转换的技术.词向量化的方法有很多种,最简单的是one-hot编码,但是one-hot会有维度灾难的 ...
- 随机森林(Random Forest),决策树,bagging, boosting(Adaptive Boosting,GBDT)
http://www.cnblogs.com/maybe2030/p/4585705.html 阅读目录 1 什么是随机森林? 2 随机森林的特点 3 随机森林的相关基础知识 4 随机森林的生成 5 ...
- Adaptive Boosting
Boosting boosting和bagging很类似,所使用的多个分类器类型都是一致的.另外,他们的主要区别点如下: boosting中不同的分类器是通过串行得到的,每个分类器都是根据已经训练出来 ...
随机推荐
- 分布式ID的简单总结
来源:郴州网站优化 简单总结一下流行的分布式id的实现方法 雪花算法 snowflake是twitter开源的分布式ID生成算法. 核心思想是:分布式ID固定是一个long型的数字,一个long型占8 ...
- Django静态文件配置-request方法-ORM简介-字段的增删改查
app的创建注意事项: 在Django新创建的app要在seetings.py中添加注册,才会生效 创建app:django-adminapp an startapp app名称 或者 python3 ...
- 【转】Fst指数
[转]Fst指数 转载自 http://blog.csdn.net/zhu_si_tao/article/details/71513099 与 http://blog.sina.com.cn/s/bl ...
- tomcat更新class不生效
替换线上lib里的class不生效,需要想想是不是前人为了图方便在classes里面扔了一份老版本class
- topological space
\(\underline{Def:}\)A topology space \(\mathcal{X}=(\underline{X},\eth_{x})\)consists of a set \(\un ...
- ubuntu 14.04 搜狗拼音安装
打开 Software & Updates,添加软件源: sudo add-apt-repository ppa:fcitx-team/nightly 输入 sudo apt-get inst ...
- pandas常用小trick(持续更新)
记录一下pandas常用的小技巧,时间长了干别的去了会忘记,记录一下: 1. 在处理数据过程中涉及到label和null的处理方法 # 方法一 df['height'][df.height < ...
- DataGrip设置时区
新版本DataGrip以默认时区取世界标准时间.要想时间显示正常,需要将时区变为上海时区,可手动在连接配置里设置参数.如下图: 操作步骤1.右键打开你想要修改的数据库连接的Properties菜单:2 ...
- Smarty使用-模版中编写js
在smarty模版中编写js使用literal标签, Literal 标签区域内的数据将被当作文本处理,此时模板将忽略其内部的所有字符信息. 该特性用于显示有可能包含大括号等字符信息的 javas ...
- 整理汇总系统中空值的使用方法,后台+jsp
一.后台: 1. entity.getStringValue().isEmpty()://字符串自带方法,未发现非空方法实现原理:判断值的长度 public boolean isEmpty() { r ...