Pika源码学习--pika的通信和线程模型
pika的线程模型有官方的wiki介绍https://github.com/Qihoo360/pika/wiki/pika-%E7%BA%BF%E7%A8%8B%E6%A8%A1%E5%9E%8B,这里主要介绍了pika都有哪些线程,这些线程用来干嘛。本篇文章主要涉及监听线程DispatchThread、IO工作线程WorkerThread和工作线程池ThreadPool,结合代码介绍里面实现的一些细节。
- 1.监听线程DispatchThread
在创建PikaServer的时候,会构造一个PikaDispatchThread,这个PikaDispatchThread,实际上是用了pink网络库的DispatchThread::DispatchThread

DispatchThread构造函数里面会初始化好若干个WorkerThread
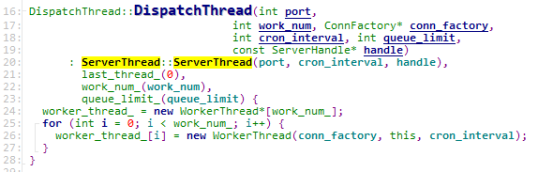
DispatchThread继承自ServerThread,ServerThread继承了Thread,线程启动时实际上运行的是子类的ThreadMain方法,继承了Thread类的子类需要有自己的ThreadMain,监听线程start的时候,入口是ServerThread::ThreadMain()。线程启动会先ServerThread::InitHandle(),绑定和监听端口,下面看看ServerThread::ThreadMain()里面做了啥。
ServerThread::ThreadMain()主要逻辑是一个epoll,当有新的连接事件来的时候,accept,然后调用DispatchThread::HandleNewConn来处理这个新的连接
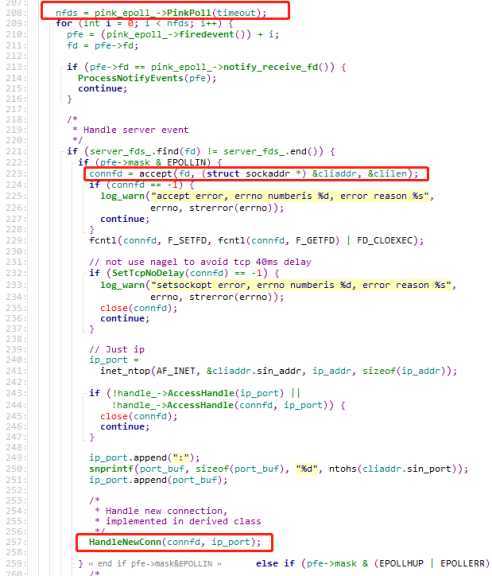
DispatchThread::HandleNewConn如何处理连接呢?实际上监听线程会把连接分发给IO工作线程WorkerThread来处理。每个WorkerThread都有一个PinkEpoll,PinkEpoll有一个notify_queue_,新的连接会以PinkItem的形式push到这个队列里面,然后通知WorkerThread来处理。分发的方式类似轮训,会按顺序分发给notify_queue_没有满的WorkerThread。
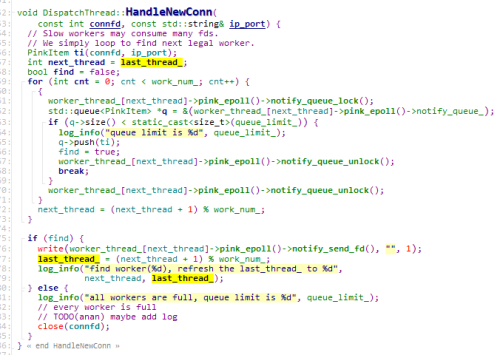
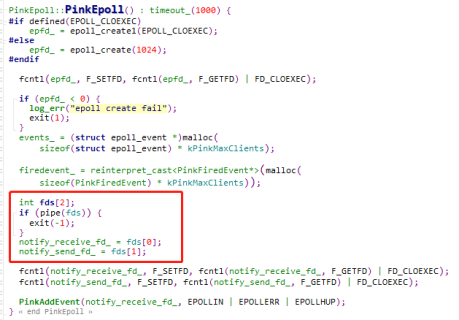
那么监听线程如何通知WorkerThread来处理新的连接呢?使用的是管道的方式,PinkEpoll会创建一个管道用来通知,并且把这个管道加到Epoll里面。在确定好要分发的WorkerThread后,往这个WorkerThread的管道写进去一个1字节的内容,来触发这个管道的读事件。
- 2.IO工作线程WorkerThread
DispatchThread::StartThread的时候会起WorkerThread线程,WorkerThread也是继承了Thread,因此工作线程的入口是WorkerThread::ThreadMain。上文说到监听线程把新的连接放到WorkerThread的队列里面后,通知了WorkerThread进行处理。下面我们看看WorkerThread怎么处理的。
WorkerThread同样是一个Epoll,这里会处理新连接请求事件和已连接请求的事件,如果Epoll返回的fd是notify_receive_fd,即管道的接收fd,说明是内部的通知事件,一次性读取多个字节的内容,因为前面已知每个通知是1个字节,因此这里读到了多少个字节就说明有多少个通知,然后在一个循环里面处理这些请求。类型为kNotiConnect则是新的连接,这里会把监听线程push的PinkItem取出来,然后创建一个NewPinkConn,加到conns_里面,并且把这个fd加到WorkerThread的epoll,后续的消息事件就可以在这个epoll被处理。这里conn_factory用的是ClientConnFactory,返回的是PikaClientConn,继承了pink::RedisConn。

连接绑定到WorkerThread后,已建立连接的客户端发送请求过来,则是走的下面的分支,根据fd在conns_里面找到PinkConn,我们先只看读请求部分,回响应部分后面再看。
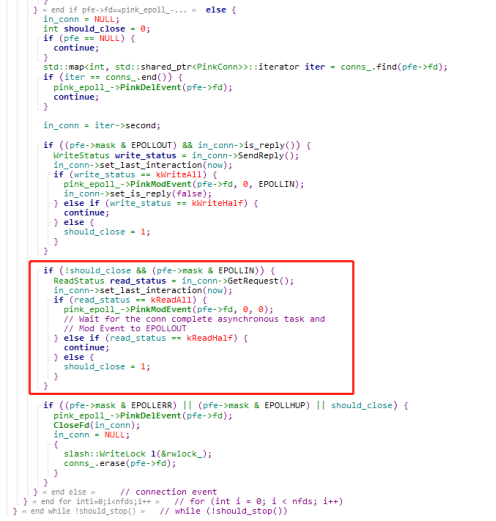
在conns_里面找到的是对应fd的PikaClientConn,使用RedisConn::GetRequest来读取客户端的的请求,此处有一个细节,如果read_status为kReadAll,则一次完整的请求被读取,会先把这个请求fd的读写事件给删除。这是为啥呢?删除了不是后续就处理不了这个请求的读写吗,这个我们后面讲到了再说明。
RedisConn::GetRequest里面,使用RedisParser::ProcessRequestBuffer来解析读取到的内容,然后有2种处理方式,DealMessage和Complete
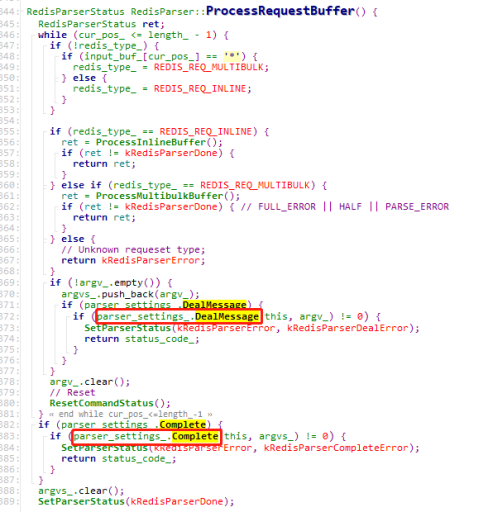
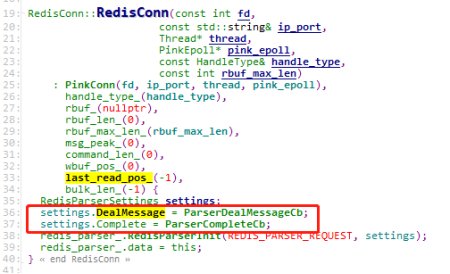
先看下这两个函数的初始化,DealMessage对应着ParserDealMessageCb,Complete对应着ParserCompleteCb
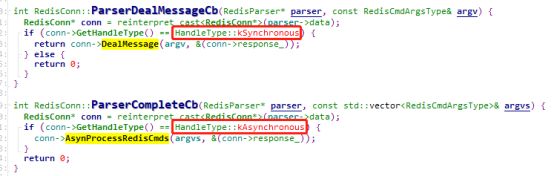
我们看这两个方法,原来一个是同步处理,一个是异步,同步的话就是一个个命令调用DealMessage来处理,异步的话是解析完合成一组命令统一调Complete处理。异步的处理方式是将请求的命令提交给线程池来处理PikaClientConn::AsynProcessRedisCmds,怎么提交的我们在工作线程池里面介绍。
- 3.工作线程池ThreadPool
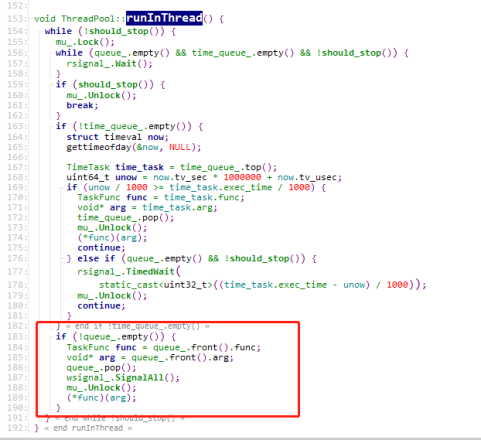
PikaServer构造的时候会创建一个PikaClientProcessor,PikaClientProcessor里面有一个ThreadPool,ThreadPool启动时会创建Worker线程,Worker线程实际的处理函数是ThreadPool::runInThread()

前面讲到WorkerThread解析完redis命令后会把命令提交给ThreadPool来处理,实际上是调用了线程池的ThreadPool::Schedule方法,Schedule需要一个TaskFunc来真正处理命令,这里使用的是DoBackgroundTask

ThreadPool::Schedule里面,把参数封装成Task,然后push到线程池的任务队列,接着通知线程池处理,这里WorkerThread是生产者,线程池是消费者。
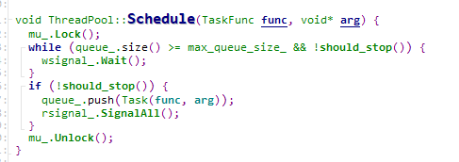
而线程池的工作线程,则是不断地在队列里面取出Task进行处理。
- 4.命令处理和响应流程
线程池里面实际处理命令的是DoBackgroundTask,我们先来看看命令是怎么被处理的。DoBackgroundTask里面调用的是PikaClientConn::BatchExecRedisCmd
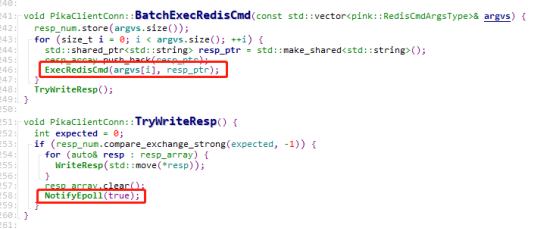
BatchExecRedisCmd里面是命令一个一个取出来ExecRedisCmd,然后PikaClientConn::DoCmd,响应消息先塞到resp_array,在TryWriteResp里面又把响应一个个取出来塞到response_里,并且把is_reply_置为true,然后做了一个NotifyEpoll的操作。
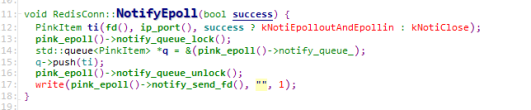
可以看到,这里把处理结果又封装成一个PinkItem,然后和前面介绍的监听线程把连接请求分发给WorkerThread一样,把PinkItem放到PinkEpoll的队列里面,然后通过在管道里面写了一个字节的字符触发epoll的读事件。所以我们回过头来看看WorkerThread的处理WorkerThread::ThreadMain
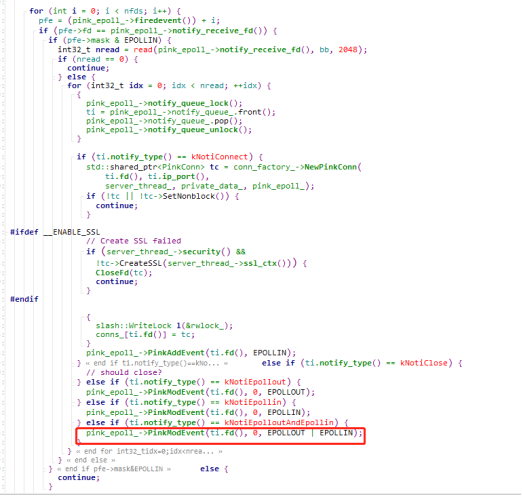
这里的流程和前面介绍的差不多,可以看到这里把这个连接的fd的读写事件重新加到epoll里面,前面我们留了一个疑问,在一次命令读取结束后,把连接fd的读写事件从epoll里面删除了,这是为啥呢?这里我们看到命令处理结束后又把读写事件加回来了。应该是因为pika用的是异步处理,一个连接的命令是异步地交给线程池处理,如果同个连接发了2个命令,因为是异步处理,没有办法保证2个命令满足FIFO,即先来的命令需要先回复,后来的命令后回复,redis是单线程模型,因此天然满足,pika是多线程异步处理,所以这里在读取了第一个命令后,把连接的读写事件删除了,等前一个命令处理完了才加回来,读取第二个命令来处理。
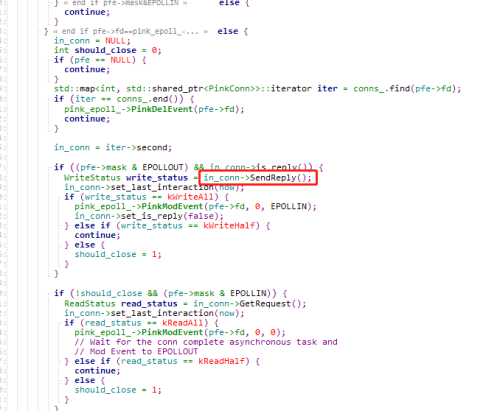
连接的fd加进epoll后,fd可写了,那么epoll会返回可写事件,用RedisConn::SendReply来发送响应给客户端,如果写完了会把fd的写事件给删掉,如果没写完,则等fd可写了会继续触发写事件来写回复。
- 5.总结
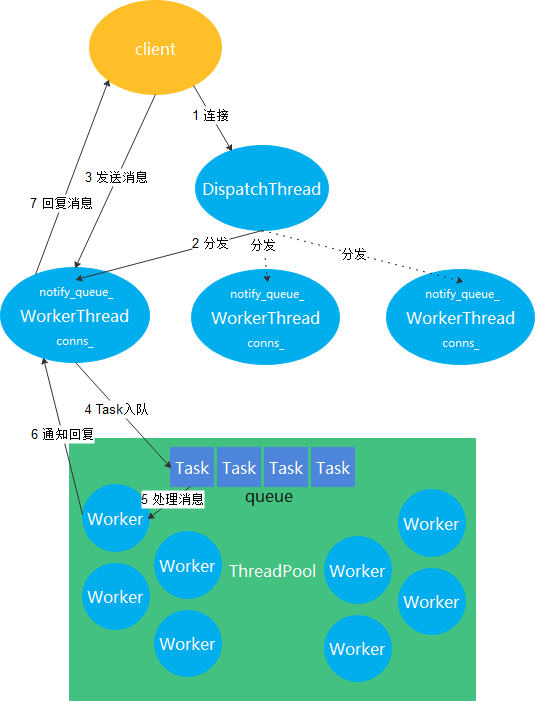
通过上面的分析可以知道,监听线程是用来监听新的连接,连接来了会交由WorkerThread处理,已建立连接的请求会由WorkerThread封装成Task交给线程池ThreadPool处理,ThreadPool处理完了后,还是由WorkerThread来回复。WorkerThread就是做接收消息,回复消息的,而ThreadPool只是处理消息,不涉及接收和回复的IO操作。这3者的关系大概如下图所示:
Pika源码学习--pika的通信和线程模型的更多相关文章
- Netty源码学习(一)Netty线程模型
给你一台4路E7-4820V2(32核心64线程),512G内存的服务器,你该如何编程才能支持百万长连接? 最直接的想法是采用BIO的模式,为每个连接新建一个线程,在一一对应的线程中直接处理连接上的数 ...
- Netty源码死磕一(netty线程模型及EventLoop机制)
引言 好久没有写博客了,近期准备把Netty源码啃一遍.在这之前本想直接看源码,但是看到后面发现其实效率不高, 有些概念还是有必要回头再细啃的,特别是其线程模型以及EventLoop的概念. 当然在开 ...
- Linux内核源码分析之调度、内核线程模型 And Centos7.2's Kernel Resource Analysis
本文分为概述.历史.el7.2代码架构图解三部分. 解决的问题: a.Kernel调度发展过程: b.以架构图的方式,详解el7.2具体调度实现.内核线程模型.调度时间片计算,以及探究整个Kernel ...
- netty源码解解析(4.0)-7 线程模型-IO线程EventLoopGroup和NIO实现(二)
把NIO事件转换成对channel unsafe的调用或NioTask的调用 processSelectedKeys()方法是处理NIO事件的入口: private void processSelec ...
- netty源码解解析(4.0)-6 线程模型-IO线程EventLoopGroup和NIO实现(一)
接口定义 io.netty.channel.EventLoopGroup extends EventExecutorGroup 方法 说明 ChannelFuture register(Channel ...
- netty源码解解析(4.0)-5 线程模型-EventExecutorGroup框架
上一章讲了EventExecutorGroup的整体结构和原理,这一章我们来探究一下它的具体实现. EventExecutorGroup和EventExecutor接口 io.netty.util.c ...
- netty源码解解析(4.0)-4 线程模型-概览
netty线程体系概览 netty的高并发能力很大程度上由它的线程模型决定的,netty定义了两种类型的线程: I/O线程: EventLoop, EventLoopGroup.一个EventLoop ...
- async-validator 源码学习笔记(二):目录结构
上一篇文章<async-validator 源码学习(一):文档翻译>已经将 async-validator 校验库的文档翻译为中文,看着文档可以使用 async-validator 异步 ...
- nginx源码学习资源(不断更新)
nginx源码学习是一个痛苦又快乐的过程,下面列出了一些nginx的学习资源. 首先要做的当然是下载一份nginx源码,可以从nginx官方网站下载一份最新的. 看了nginx源码,发现这是一份完全没 ...
随机推荐
- python 递归、匿名函数、
1.递归:就是函数自己调用自己.(注:递归最多循环999) 2.匿名函数(意义:减少内存占用) lambada 定义一个匿名函数,eg:lambad x,b:x+b (:前面是入参eg:x,b,:后 ...
- PHP 5.6连接MySQL 8.0版本遇到的坑
一.数据库失败Warning: mysqli_connect(): The server requested authentication method unknown to t... <?ph ...
- MySQL 归纳总结
1.MySQL存储引擎 主要使用的就是两个存储引擎,分别是InnoDB和MyISAM. InnoDB InnoDB是MySQL的默认存储引擎.InnoDB采用MVCC来支持高并发,并且实现了四个标准的 ...
- Daily Scrum 1/18/2016
Yandong & Zhaoyang: Prepare bug bash slides for Beta release; Dong & Fuchen:Prepare demo for ...
- api_DZFPKJ & api_DZFPCX(get_AES_url代码优化)
通过AES加密网站的接口来传值,不需要手动加密字符串后复制过来传值. #coding:utf-8 import requests import re def get_aes_url(key, text ...
- 详解 Map集合
(请关注 本人"集合总集篇"博文--<详解 集合框架>) 首先,本人来讲解下 Map集合 的特点: Map集合 的特点: 特点: 通过 键 映射到 值的对象 一个 映射 ...
- Blazor WebAssembly 3.2.0 已在塔架就位 将发射新一代前端SPA框架
最美人间四月天,春光不负赶路人.在充满无限希望的明媚春天里,一路风雨兼程的.NET团队正奋力实现新的突破. 根据计划,新一代基于WebAssembly 技术研发的前端SPA框架Blazor 将于5月1 ...
- 是时候学习python了
“ 学习Pyhton,如何学以致用 -- 知识往问题靠,问题往知识靠” 01 为什么学Python 一直有听说Python神奇,总是想学,虽然不知道为啥.奈何每天写bug,修bug忙得不亦乐乎,总是不 ...
- 任意文件下载(pikachu)
任意文件下载漏洞 很多网站都会提供文件下载功能,即用户可以通过点击下载链接,下载到链接所对应的文件. 但是,如果文件下载功能设计不当,则可能导致攻击者可以通过构造文件路径,从而获取到后台服务器上的其他 ...
- Inno setup: check for new updates
Since you've decided to use a common version string pattern, you'll need a function which will parse ...