hbase的读写过程
hbase的读写过程:
hbase的架构:
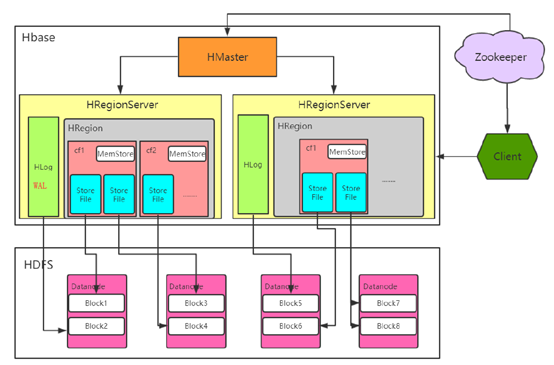
Hbase真实数据
hbase真实数据存储在hdfs上,通过配置文件的hbase.rootdir属性可知,文件在/user/hbase/下
hdfs dfs -ls /user/hbase
Found 8 items
drwxr-xr-x - root supergroup 0 2019-05-30 10:05 /user/hbase/.tmp
drwxr-xr-x - root supergroup 0 2019-05-30 11:11 /user/hbase/MasterProcWALs
drwxr-xr-x - root supergroup 0 2019-05-30 10:05 /user/hbase/WALs
drwxr-xr-x - root supergroup 0 2019-05-27 18:49 /user/hbase/archive
drwxr-xr-x - root supergroup 0 2019-05-27 18:11 /user/hbase/data
-rw-r--r-- 3 root supergroup 42 2019-05-27 14:33 /user/hbase/hbase.id
-rw-r--r-- 3 root supergroup 7 2019-05-27 14:33 /user/hbase/hbase.version
drwxr-xr-x - root supergroup 0 2019-05-30 11:16 /user/hbase/oldWALs
.tmp
当对表做创建或者删除操作的时候,会将表move 到该 tmp 目录下,然后再去做处理操作。
MasterProcWALS
记录创建表等DDL操作时的一些事务信息,用于处理如 HMaster 中断导致的 DDL 无法执行、回滚等问题
WALS
属于hbase的预写日志(write-ahead-logs),记录Hbase在数据写入时候的数据信息。数据写入过程中是先写入到WAL中,再写入到memstore。当发生 RegionServer 宕机重启后,RS 会读取 HDFS中的 WAL 进行 REPLAY 回放从而实现故障恢复。从数据安全的角度,建议开启 WAL
archive
HBase 在做 Split或者 compact 操作完成之后,会将 HFile 先移到archive 目录中,然后将之前的hfile删除掉,该目录由 HMaster 上的一个定时任务定期去清理。
data
真实数据文件HFile,HFile是通过memestore刷下来的.
hbase.id
序列化文件,标识hbase集群的唯一id号,是一个 uuid。
hbase.version
序列化文件,标识hbase集群的版本号。
oldWALs
存放旧的被回收的WAL文件
命名空间目录
hdfs dfs -ls /user/hbase/data
Found 2 items
drwxr-xr-x - root supergroup 0 2019-05-30 11:43 /user/hbase/data/default
drwxr-xr-x - root supergroup 0 2019-05-27 14:33 /user/hbase/data/hbase
表级目录
hdfs dfs -ls -R /user/hbase/data/default/t1
drwxr-xr-x /user/hbase/data/default/t1/.tabledesc
drwxr-xr-x /user/hbase/data/default/t1/.tmp
drwxr-xr-x /user/hbase/data/default/t1/68e61220e866d62a27d0cdeb0c1eed83 #HFile
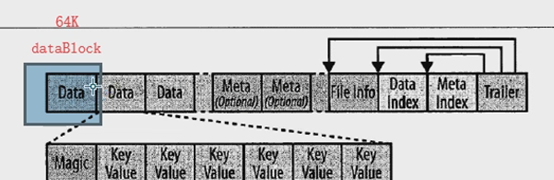
HFile、WAL和Memstore
HFile
HBase实际的存储文件功能是由HFile类实现的,它被专门创建以达到一个目的:有效的存储HBase数据。
HFile数据都在前面的data里:
WAL
regionserver会将数据保存到menstore(内存)中,直到积攒足够多的数据再将其刷写到磁盘上,这样可以避免创建很多小文件。但是存储在内存中的数据是不稳定的。例如,在服务器断电的情况下数据可能会丢失。
一个常见的解决方法是预写日志(WAL):每次更新操作都会写入日志,只有写入成功才会通知客户端操作成功,然后服务器可以按需自由的批量处理或聚合内存中的数据
优化手段:
hbase数据是先写入到WAL然后写入到memstore,所以有的优化,建议大家关闭WAL
但是,关闭WAL之后,写入数据时如果发生宕机,那么数据肯定会丢失
而且,关闭WAL对于写入性能的提升,其实不是很明显.WAL其实就类似于hadoop中的edits文件
Hbase元数据:
# 列出hbase名字空间的表
hbase(main):023:0> list_namespace_tables 'hbase'
TABLE
meta
namespace
2 row(s) in 0.0140 seconds
Hbase数据定位过程:
Hbase在数据读取的时候,需要先查询hbase:meta表,通过这个表到指定的regionserver获取region信息并进行数据的读取。详细过程如下:
1.client通过zookeeper获取管理hbase:meta表的regionserver
2.zookeeper返回oldboy-node103
3.向oldboy-node103获取hbase:meta表的的数据信息
4.查找到t1的row1所对应的region是被oldboy-node102所管理
5.将信息返回给客户端
6.向oldboy-node102获取对应region的数据
一旦知道区域(region)的位置,Hbase会缓存这次查询信息。之后客户端可以通过缓存信息定位所需的数据位置,而不用再次查找hbase:meta。
读取过程:
区域(region)和列族(column family)是以文件夹形式存在于HDFS的,所以在读取的时候:
如果确定了区域位置,就直接从指定的region目录读取数据。
如果一个列族文件夹中的文件有多个StoreFile,客户端会通过布隆过滤器筛选出可能存在数据的块,对这些块进行数据的查找。
如果此行有多个列族的话,就会在所有的列族文件夹中同时进行以上操作
写入过程:
从上图可以看出,除了真实数据(StoreFile)外,Hbase还处理一种HLog文件,此文件称为预写日志(WAL)。用户发起put请求时,也会先定位数据位置,然后:
第一步,决定数据是否需要写到由HLog实现的预写日志(WAL)中,预写日志(WAL)存储了序列号和实际数据,所以在服务器崩溃时可以回滚到还未持久化的数据。
一旦数据被写入到WAL中,数据会被放到MemStore内存数据中。同时regionserver会检查MemStore是否已经写满,如果满了,就会被刷写(flush)到磁盘中。会把数据写成HDFS中的新StoreFile,同时也会保存最后写入的序列号,系统就知道那些数据被持久化了。
当Storefile 越来越多,会触发Compact 合并操作,把过多的 Storefile 合并成一个Storefile。
当Storefile 越来越大,Region 也会越来越大。达到阈值后,会触发Split 切割region操作。
hbase的读写过程的更多相关文章
- HBase 文件读写过程描述
HBase 数据读写过程描述 我们熟悉的在 Hadoop 使用的文件格式有许多种,例如: Avro:用于 HDFS 数据序序列化与 Parquet:常见于 Hive 数据文件保存在 HDFS中 HFi ...
- HBase的简单介绍,寻址过程,读写过程
HBase是列族数据库,主要由,表,行键,列族,列标识,值,时间戳 组成, 表 其中HBase 主要底层存储依赖与hdfs,可以在HDFS中看到每个表名都作为一个独立的目录结构 ...
- HBase 数据读写流程
HBase 数据读写流程 2016-10-18 杜亦舒 读数据 HBase的表是按行拆分为一个个 region 块儿,这些块儿被放置在各个 regionserver 中 假设现在想在用户表中获取 ro ...
- f2fs源码分析之文件读写过程
本篇包括三个部分:1)f2fs 文件表示方法: 2)NAT详细介绍:3)f2fs文件读写过程:4) 下面详细阐述f2fs读写的过程. 管理数据位置关键的数据结构是node,node包括三种:inode ...
- HDFS 文件读写过程
HDFS 文件读写过程 HDFS 文件读取剖析 客户端通过调用FileSystem对象的open()来读取希望打开的文件.对于HDFS来说,这个对象是分布式文件系统的一个实例. Distributed ...
- Hbse的读写过程
1.Hbase的读取过程. 以读取test_region表,row key为this is row value 400000为例. 1: 到zookeeper中去读取/hbase/root-regio ...
- HDFS读写过程
HDFS的读写过程: 读过程: Client收到用户的读请求——client拿着path向namenode请求文件或者block的datanode列表——client从返回的datanode列表中选择 ...
- Netty源码解析 -- ChannelPipeline机制与读写过程
本文继续阅读Netty源码,解析ChannelPipeline事件传播原理,以及Netty读写过程. 源码分析基于Netty 4.1 ChannelPipeline Netty中的ChannelPip ...
- hbase架构和读写过程
转载自:https://www.cnblogs.com/itboys/p/7603634.html 在HBase读写时,相同Cell(RowKey/ColumnFamily/Column相同)并不保证 ...
随机推荐
- 前端接受base64的excel,点击立即下载
由于使用框架的特殊性,后台返回的文件流进行了base64加密,所以返回的是base64格式,所以需要将其转变为blob,上代码
- Wpf自动滚动效果
一.思路 1.使用ScrollView的Scroll.ScrollToVerticalOffset(offset)方法进行滚动 2.ScrollView中放置2个ListView,第一个滚动出边界后, ...
- uniapp动态改变底部tabBar和导航标题navigationBarTitleText
在开发中,我们会遇到需求国际化,那么底部tabBar和导航标题navigationBarTitleText就要动态切换: 1.改变底部tabBar: uni.setTabBarItem({ index ...
- 【杂题】[CodeForces 1172E] Nauuo and ODT【LCT】【口胡】
Description 给出一棵n个节点的树,每个点有一个1~n的颜色 有m次操作,每次操作修改一个点的颜色 需要在每次操作后回答树上\(n^2\)条路径每条路径经过的颜色种类数和. \(n,m< ...
- git远程相关
git remote add origin git仓库地址 // 添加了远程仓库 git remote remove origin // 移除远程仓库 git push -u origin maste ...
- JS框架_(JQuery.js)带阴影贴纸标签按钮
百度云盘 传送门 密码:azo6 纯CSS带阴影贴纸标签按钮效果: <!doctype html> <html> <head> <meta charset=& ...
- C++入门经典-例3.13-不加break的switch判断语句
1:不加break,会依次运行下面的语句,代码如下: // 3.13.cpp : 定义控制台应用程序的入口点. // #include "stdafx.h" #include &l ...
- VUE生命周期demo
<!DOCTYPE html> <html> <head> <title></title> <script typ ...
- 【flask】使用配置类管理app测试环境-demo版
如果对app.config是什么还心有疑惑,或者对于这种配置方式很陌生,参考:flask项目配置 app.config classConfig.py: class BaseConfig(object) ...
- Ant Design使用方法
1.antd官网: https://ant.design/docs/react/introduce-cn 2.React中使用Antd 1.安装antd npm install antd --save ...