python_面试题_DB相关问题
1.mysql部分
问题
问题1:mysql的存储引擎
问题2:mysql的索引机制
问题3:mysql的事务以及事务隔离级别
问题4:mvcc/GAP lock是做什么的
问题5:mysql的悲观锁与乐观锁
回答
问题1:mysql的存储引擎
mysql的存储引擎
- 在mysql中的查询语句为:mysql> show engines,
- 查看当前mysql的默认存储引擎为:mysql> show variables like '%storage_engine%',
- 查看某个表用了什么引擎则是:mysql> show create table 表名;
mysql的常用存储引擎
- MyISAM:不支持事务,不支持外键,访问速度快,对事务完整性没有要求,设计之初主要为了查询操作。使用场景有:非事务型应用,只读类应用,空间类应用
- InnoDB(MySQL 5.5后默认引擎):支持完整事务,支持外键约束,行级锁,设计之初处理大容量数据库操作,容易有IO瓶颈。使用场景:适用绝大多数场景
- MEMORY:只存储表,数据放在内存中,掉电后数据不保留,访问速度快。使用场景:内容变化不频繁的代码表,或者是作为统计
问题2:mysql的索引机制
mysql的索引机制有如下几种
- 聚集索引:就是按照每张表的主键构造一颗B+树,叶子节点村完整的行记录数据,未定义主键,则取第一个唯一索引,每张表只能拥有一个聚集索引。在多数情况下,查询优化器倾向于采用聚集索引。因为聚集索引能够在B+树索引的叶子节点上直接找到数据,并且可以快速查找数据。
- 非聚集索引:是对聚集索引的一种补充,每张表可以有多个辅助索引,辅助索引与聚集索引区别为叶子节点不包含行记录的全部数据,除此之外还包含一个书签,可以指向对应的行数据。
- 普通索引:普通的索引,index只是为了加速查找
- 唯一索引:主键索引:加速查找+约束(不为空,不能重复) 唯一索引:加速查找+约束(不能重复)
- 组合索引:多个索引联合查找,查找顺序从左到右查询。
备注:举例说明索引机制的使用场景(商城的会员卡系统,会员编号作为主键,会员编号就是唯一索引,用来创建B+树;会员姓名如果要创建索引,则就是普通索引;会员身份证信息如果要创建索引,则就是唯一索引)
补充知识:B+树与B树
(1.)B树
所谓的B树就是多路搜索树,任意一个非叶子节点最多有M个儿子,关键字分布在整颗树中,任何一个关键字出现且只出现一个节点中,搜索有可能在非叶子节点中结束,性能等价于二分查找,时间复杂度为O(lgN)
如:(M=3)
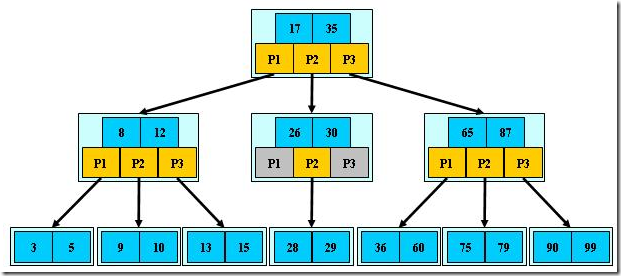
(2.)B+树
所谓的B+树,就是B树的变体,也是多路搜索树,非叶子节点的字数指针与关键字个数相同,非叶子节点子树指针指向子树,所有的叶子节点都增加一个链指针,所有的关键字都在叶子节点中出现,不可能在非叶子结点命中,非叶子结点相当于是叶子结点的索引(稀疏索引),叶子结点相当于是存储(关键字)数据的数据层,比较适合文件索引系统
如:(M=3)
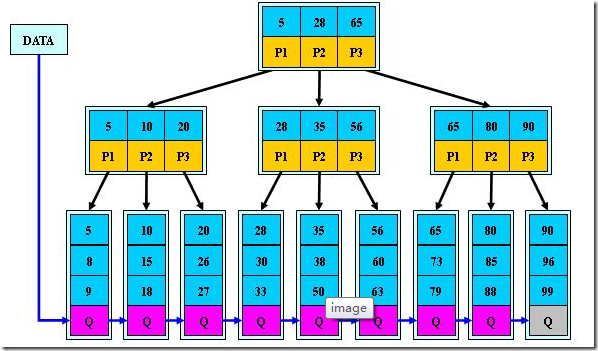
问题3:mysql的事务以及事务隔离级别
mysql的事务遵循4个条件(ACID),有原子性:不可分割性;一致性;隔离性;持久性;在实际使用中,使用事务保证一个事务中的操作,要么全部完成,要么全部不完成,保证数据的安全性
其中事务隔离级别分为以下几种
- RU:既未提交读,容易出现脏读情况,既事务A读到了事务B没有提交的数据;
- RC:既提交读,为解决脏读问题,容易出现提交重复的情况,既事务A在执行的过程中,有可能事务B提交了数据,事务读取的数据和之前不一致;
- RR:既可重复读,为解决上一级的数据不一致问题,该级别采用MVCC(多版本并发操作)解决重复读,一般RR级别会产生幻读的问题,既同一个事务多次执行同一个select,读取到的数据行发生了改变,这是因为数据行发生了行数减少或者新增;所谓幻读就是同一个事务里,查询的结果都是事务开始时的状态(一致性)。但是,如果另一个事务同时提交了新数据,本事务再更新时,就会“惊奇的”发现了这些新数据,貌似之前读到的数据是“鬼影”一样的幻觉。搞笑的比喻就是,假如,中午去食堂打饭吃,看到一个座位是空的,便屁颠屁颠的去打饭,回来后,发现这些座位都还是空的(重复读),窃喜。走到跟前刚准备坐下时,却惊现一个恐龙妹,严重影响食欲。仿佛之前看到的空座位是“幻影”一样。但是mySQL中RR级别引入了GAP LOCK(间隙锁)的概念,可在RR级别即可解决幻读的问题;另外一个特性是mysql里的MVCC只解决读-写的阻塞问题,写-写依然还是阻塞的。
- SE:既可序列化,事务相当于串行操作,解决了脏读、不可重复读、幻读等问题,但对性能和效率的影响很大
问题4:mvcc/GAP lock是做什么的
MVCC:既多版本并发操作,基本原理就是某个时间点的快照,每行数据都存在一个版本,每次数据更新时都更新该版本,修改是copy出当前版本随意修改,各个事务之间无干扰,保存时则比较版本号,如果成功,则覆盖原纪录,失败则放弃并回滚。需要注意的是mysql里的MVCC只解决读-写的阻塞问题,写-写依然还是阻塞的
GAP lock:间隙锁,用于解决mySQL中RR级别的幻读问题,如果一个事务操作的是一个区间的数据,会锁住这个区间所有的记录,即使这个记录不存在,这个时候另一个会话去插入这个区间的数据,就必须等待上一个结束。需要注意的是在此有可能会产生GAP死锁,例如下图

问题5:mysql的悲观锁与乐观锁
无论悲观锁和乐观锁都是并发控制主要采用的技术手段,都是为了保证数据库中的数据的完整性与一致性
悲观锁:对数据被外界修改持保守态度 (悲观),因此,在整个数据处理过程中,将数据处于锁定状态。 悲观锁的实现,往往依靠数据库提供的锁机制,而悲观锁一般流程如下
- 在对任意记录进行修改前,先尝试为该记录加上排他锁(exclusive locking)
- 如果加锁失败,说明该记录正在被修改,那么当前查询可能要等待或者抛出异常。 具体响应方式由开发者根据实际需要决定。
- 如果成功加锁,那么就可以对记录做修改,事务完成后就会解锁了。
悲观锁主要用于数据争用激烈的环境,以及发生并发冲突时使用锁保护数据的成本要低于回滚事务的成本的环境中。在效率方面,处理加锁的机制会让数据库产生额外的开销,还有增加产生死锁的机会;另外,在只读型事务处理中由于不会产生冲突,也没必要使用锁,这样做只能增加系统负载,还有会降低了并行性。
悲观锁的应用
乐观锁:假设认为数据一般情况下不会造成冲突,所以在数据进行提交更新的时候,才会正式对数据的冲突与否进行检测,如果发现冲突了,则让返回用户错误的信息,让用户决定如何去做。在对数据库进行处理的时候,乐观锁并不会使用数据库提供的锁机制。一般的实现乐观锁的方式就是记录数据版本。
- 当读取数据时,将版本标识的值一同读出,数据每更新一次,同时对版本标识进行更新。
- 当我们提交更新的时候,判断数据库表对应记录的当前版本信息与第一次取出来的版本标识进行比对
- 如果数据库表当前版本号与第一次取出来的版本标识值相等,则予以更新,否则认为是过期数据。
乐观锁的应用
2.MongoDB部分
问题:
问题1:MongoDB的存储引擎以及底层存储机制
问题2:MongoDB的版本变迁既特性
回答:
问题1:
存储引擎如下:
- MMAP:
- WiredTiger:3.2版本默认存储引擎都改为了wiredtiger,特性为:文档级别锁,解决了锁粒度过大的问题,磁盘数据压缩,删除数据时,数据会立即删除,MongoDB3.0在多线程、批量插入场景下较之于MongoDB2.6有大约4-7倍的增长
- RocksDB:特性:顺序写入:LSM Tree结构,随机写入转换为顺序写入;速度稳定:和WiredTiger相比,写速度稳定
- Memory
底层存储机制:空间局部性原理,B树
问题2:
MongoDB 3.0特性(2015年):顺序写入:LSM Tree结构,随机写入转换为顺序写入,速度稳定:和WiredTiger相比,写速度稳定
MongoDB 4.0特性(2018年6月):多文档事务支持,4.2版本开始支持分片集群分布式事务
3.Redis部分
问题:
问题1:redis支持的数据类型常用使用场景
问题2:redis的存储机制以及常用集群
回答
问题1:
redis支持的数据类型主要有string,list,set,zset,hash
redis的常用使用场景
- 作为热数据的缓存数据库,缓存高频次访问的数据,降低数据库的IO
- 分布式架构,做session共享
- 利用zset类型可以做存储排行榜
- 利用list做简易MQ或存储最新的n个数据
问题2:
redis的存储机制有
- list键:双向链表
- hash键:字典dict
- zset键:跳跃表zskiplist
- ziplist:节省内存空间
常用集群方式有
- Twitter开发的twemproxy
- 豌豆荚开发的codis
- redis官方的redis-cluster
ok
python_面试题_DB相关问题的更多相关文章
- 剑指offer编程题Java实现——面试题12相关题大数的加法、减法、乘法问题的实现
用字符串或者数组表示大数是一种很简单有效的表示方式.在打印1到最大的n为数的问题上采用的是使用数组表示大数的方式.在相关题实现任意两个整数的加法.减法.乘法的实现中,采用字符串对大数进行表示,不过在具 ...
- 剑指offer编程题Java实现——面试题7相关题用两个队列实现一个栈
剑指offer面试题7相关题目:用两个队列实现一个栈 解题思路:根据栈的先入后出和队列的先入先出的特点1.在push的时候,把元素向非空的队列内添加2.在pop的时候,把不为空的队列中的size()- ...
- python_面试题_HTTP基础相关问题
1.相关问题 问题1: 客户端访问url到服务器,整个过程会经历哪些 问题2: 描述HTTPS和HTTP的区别 问题3: HTTP协议的请求报文和响应报文格式 问题4: HTTP的状态码有哪些? 2. ...
- 京东面试题 Java相关
1.JVM的内存结构和管理机制: JVM实例:一个独立运行的java程序,是进程级别 JVM执行引擎:用户运行程序的线程,是JVM实例的一部分 JVM实例的诞生 当启动一个java程序时.一个JVM实 ...
- python_面试题_TCP的三次握手与四次挥手问题
1.相关问题 问题1: 请详细描述三次握手和四次挥手的过程,并画出状态图 问题2: 四次挥手中TIME_WAIT状态存在的目的是什么? 问题3: TCP是通过什么机制保障可靠性的? 2.问题回答 问题 ...
- Python_面试题_更新中
Python-面试题 线上操作系统 centos py2和py3的区别 每种数据类型,列举你了解的方法 3 or 9 and 8 字符串的反转 is 和 == 的区别? git流程 v = (1) / ...
- python面试题-python相关
1. __new__.__init__区别,如何实现单例模式,有什么优点 __new__是一个静态方法,__init__是一个实例方法 __new__返回一个创建的实例,__init__什么都不返回 ...
- Python面试题-数据库相关
1.mysql如何做分页 mysql数据库做分页用limit关键字,它后面跟两个参数startIndex和pageSize 2.mysql引擎有哪些 innodb和myisam两个引擎,两者区别是 i ...
- js 面试题正则相关
正则相关[i不区分大小写,g匹配全部数据] var str = "Hello word! I think word is good."; 1.替换str中的word为javascr ...
随机推荐
- 关于css阴影和浮动
盒子阴影box-shadow box-shadow:0 0 1px #000 inset; 水平 垂直 模糊 颜色 : [1] inset代表框内阴影,不加inset代表框外阴影 [2]第1个 ...
- 处理并解决mysql8.0 caching-sha2-password问题,开启远程访问
原文:https://blog.csdn.net/u010026255/article/details/80062153 启动mysql服务:service mysqld start ALTER US ...
- 2019年11月18日 JAVA期中考试 增删改查
一.题目 石家庄铁道大学 青年志愿者服务网(20分) 1.项目需求: 为了适应社会主义市场经济发展的需要,推动青年志愿服务体系和多层次社会保障体系的建立和完善,促进青年健康成长,石家庄铁道大学急需 ...
- SQL server 大量数据导入和系统运行慢的问题
1.日常排查语句 --当前正在执行的语句 SELECT der.[session_id],der.[blocking_session_id], sp.lastwaittype,sp.hostname, ...
- ELK——集中式日志系统
https://www.ibm.com/developerworks/cn/opensource/os-cn-elk/index.html 基本流程是 Shipper 负责从各种数据源里采集数据,然后 ...
- 对JS继承的研究--------------引用
问:类继承和原型继承不是同一回事儿吗,只是风格选择而已? 答:不是! 类继承和原型继承不论从本质上还是从语法上来说,都是两个截然不同的概念. 二者之间有着区分彼此的本质性特征.要完全看懂本文,你必须牢 ...
- layui的数据表格加上操作
数据表格加上操作. <script type="text/html" id="barDemo"> <a class="layui-b ...
- shiro之缓存
1 细说shiro之七:缓存:https://www.cnblogs.com/nuccch/p/8044226.html 2 Shiro缓存使用Redis.Ehcache.自带的MpCache实现的三 ...
- 暑假集训 #2 div1 I - Lada Priora 精度处理
I - Lada Priora Time Limit:1000MS Memory Limit:65536KB 64bit IO Format:%I64d & %I64u Sub ...
- phpstorm 设置ftp自动保存服务器 (原)
打开PHPstorm,依次 tools - deployment -- configuration 配置ftp或者sftp地址用户名密码等 端口号 要不就是 21 要不就是 22 , 22不行 ...