反向传播算法-损失函数&激活函数
在监督学习中,传统的机器学习算法优化过程是采用一个合适的损失函数度量训练样本输出损失,对损失函数进行优化求最小化的极值,相应一系列线性系数矩阵W,偏置向量b即为我们的最终结果。在DNN中,损失函数优化极值求解的过程一般采用梯度下降法、牛顿法或拟牛顿法等迭代方法来迭代完成。对DNN的损失函数用梯度下降法进行迭代优化求极小值的过程即为反向传播算法,可以使用多种损失函数和激活函数。
1. 均方差损失函数+Sigmoid激活函数
Sigmoid激活函数的表达式为:
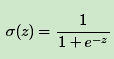
σ(z)的函数图像如下:
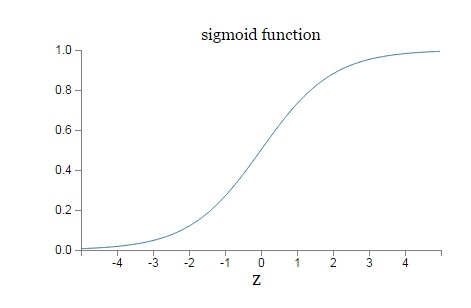
对于Sigmoid,当z的取值越来越大后,函数曲线变得越来越平缓,意味着此时的导数σ′(z)也越来越小。同样的,当z的取值越来越小时,也有这个问题。仅仅在z取值为0附近时,导数σ′(z)的取值较大。
缺点:反向传播算法中,每一层向前递推都要乘以σ′(z),得到梯度变化值。Sigmoid的这个曲线意味着在大多数时候,我们的梯度变化值很小,导致我们的W、b更新到极值的速度较慢,也就是我们的算法收敛速度较慢。
2. 交叉熵损失函数+Sigmoid激活函数
Sigmoid的函数特性导致反向传播算法收敛速度慢的问题,有两种改进策略:1)换激活函数;2)使用交叉熵损失函数来代替均方差损失函数:使用交叉熵得到的的δl梯度表达式没有σ′(z),梯度为预测值和真实值的差距,这样求得的Wl,bl也不包含σ′(z),因此避免了反向传播收敛速度慢的问题。
3. 对数似然损失函数和softmax激活函数
上述输出是连续可导的值,但如果是分类问题,输出是一个个的类别时,假设对三个类别进行分类,输出层应该有三个神经元,假设第一个神经元对应类别一,第二个对应类别二,第三个对应类别三,这样我们期望的输出应该是(1,0,0)、(0,1,0)和(0,0,1)这三种。即样本真实类别对应的神经元输出应该无限接近或者等于1,而非改样本真实输出对应的神经元的输出应该无限接近或者等于0。或者输出层的神经元对应的输出是若干个概率值,这若干个概率值即DNN模型对于输入值对于各类别的输出预测,同时满足概率模型,这若干个概率值之和应该等于1。分类模型要求是输出层神经元输出的值在0到1之间,同时所有输出值之和为1。
Softmax激活函数的表达式为:
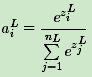
其中,nL是输出层第L层的神经元个数,或者说我们的分类问题的类别数。
Softmax激活函数在前向传播算法时:
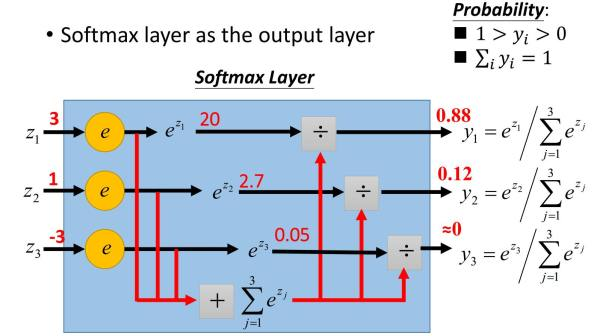
反向传播:假设真实类别是第i类,则其他不属于第i类序号对应的神经元的梯度导数直接为0。对于真实类别第i类,它的WiL对应的梯度为(aiL−1)aiL−1,biL的梯度为aiL−1。举个例子,假如我们对于第2类的训练样本,通过前向算法计算的未激活输出为(1,5,3),则我们得到softmax激活后的概率输出为:(0.015,0.866,0.117)。由于我们的类别是第二类,则反向传播的梯度应该为:(0.015,0.866-1,0.117)。
梯度消失&梯度爆炸:在反向传播算法过程中,由于使用矩阵求导的链式法则,有一大串连乘,如果连乘的数字在每层都是小于1的,则梯度越往前乘越小,导致梯度消失;连乘的数字在每层都是大于1的,则梯度越往前乘越大,导致梯度爆炸。

1)对于梯度爆炸,一般可以通过调整DNN模型中的初始化参数来解决;
2)对于梯度消失,可部分解决梯度消失问题的办法是使用ReLU(Rectified Linear Unit)激活函数,ReLU在卷积神经网络CNN中已得到广泛应用。
ReLU激活函数表达式为:
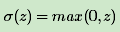
大于等于0则不变,小于0则激活后为0。
反向传播算法-损失函数&激活函数的更多相关文章
- 稀疏自动编码之反向传播算法(BP)
假设给定m个训练样本的训练集,用梯度下降法训练一个神经网络,对于单个训练样本(x,y),定义该样本的损失函数: 那么整个训练集的损失函数定义如下: 第一项是所有样本的方差的均值.第二项是一个归一化项( ...
- 深度神经网络(DNN)反向传播算法(BP)
在深度神经网络(DNN)模型与前向传播算法中,我们对DNN的模型和前向传播算法做了总结,这里我们更进一步,对DNN的反向传播算法(Back Propagation,BP)做一个总结. 1. DNN反向 ...
- 卷积神经网络(CNN)反向传播算法
在卷积神经网络(CNN)前向传播算法中,我们对CNN的前向传播算法做了总结,基于CNN前向传播算法的基础,我们下面就对CNN的反向传播算法做一个总结.在阅读本文前,建议先研究DNN的反向传播算法:深度 ...
- 循环神经网络(RNN)模型与前向反向传播算法
在前面我们讲到了DNN,以及DNN的特例CNN的模型和前向反向传播算法,这些算法都是前向反馈的,模型的输出和模型本身没有关联关系.今天我们就讨论另一类输出和模型间有反馈的神经网络:循环神经网络(Rec ...
- LSTM模型与前向反向传播算法
在循环神经网络(RNN)模型与前向反向传播算法中,我们总结了对RNN模型做了总结.由于RNN也有梯度消失的问题,因此很难处理长序列的数据,大牛们对RNN做了改进,得到了RNN的特例LSTM(Long ...
- 机器学习 —— 基础整理(七)前馈神经网络的BP反向传播算法步骤整理
这里把按 [1] 推导的BP算法(Backpropagation)步骤整理一下.突然想整理这个的原因是知乎上看到了一个帅呆了的求矩阵微分的方法(也就是 [2]),不得不感叹作者的功力.[1] 中直接使 ...
- 人工神经网络反向传播算法(BP算法)证明推导
为了搞明白这个没少在网上搜,但是结果不尽人意,最后找到了一篇很好很详细的证明过程,摘抄整理为 latex 如下. (原文:https://blog.csdn.net/weixin_41718085/a ...
- 神经网络之反向传播算法(BP)公式推导(超详细)
反向传播算法详细推导 反向传播(英语:Backpropagation,缩写为BP)是"误差反向传播"的简称,是一种与最优化方法(如梯度下降法)结合使用的,用来训练人工神经网络的常见 ...
- TensorFlow从0到1之TensorFlow实现反向传播算法(21)
反向传播(BPN)算法是神经网络中研究最多.使用最多的算法之一,它用于将输出层中的误差传播到隐藏层的神经元,然后用于更新权重. 学习 BPN 算法可以分成以下两个过程: 正向传播:输入被馈送到网络,信 ...
随机推荐
- 使用keil生成bin文件
相关文件 下载http://pan.baidu.com/share/link?shareid=478269&uk=1107426113 使用kei自带的工具的话是 打开Options f ...
- php的switch函数
PHP Switch 语句 PHP If...Else PHP While 循环 switch 语句用于基于不同条件执行不同动作. Switch 语句 如果您希望有选择地执行若干代码块之一,请使用 S ...
- IDM非补丁破解方法
参考 http://tieba.baidu.com/p/3878377959 备份文章 在网络和共享中心中打开防火墙 高级设置->出站规则->新建规则 打开新建规则向导. 程序-> ...
- JS利用XMLHttpRequest拦截ajax请求
function XMLHttpRequestBreak(fun=()=>false){ let f = XMLHttpRequest.prototype.open; let add = fun ...
- python利器之切片
切片 切片的语法表达式为:[start_index : end_index : step],其中: start_index表示起始索引 end_index表示结束索引 step表示步长,步长不能为0 ...
- Scala学习(三)——集合
基本数据结构 Scala提供了一些不错的集合. 数组 Array 数组是有序的,可以包含重复项,并且可变. val numbers = Array(1, 2, 3, 4, 5, 1, 2, 3, 4, ...
- LeetCode 300. 最长上升子序列(Longest Increasing Subsequence)
题目描述 给出一个无序的整形数组,找到最长上升子序列的长度. 例如, 给出 [10, 9, 2, 5, 3, 7, 101, 18], 最长的上升子序列是 [2, 3, 7, 101],因此它的长度是 ...
- AOP 代理类的创建
AOP 代理类的创建 入口:AnnotationAwareAspectJAutoProxyCreator#postProcessAfterInitialization 和 AnnotationAwar ...
- flutter tabbar创建与显示
效果图 main.dart import 'package:flutter/material.dart'; import 'pages/index_page.dart'; void main() =& ...
- Dart学习笔记-运算符-条件表达式-类型转换
Dart学习笔记-运算符-条件表达式-类型转换 一.运算符 1.算术运算符 + (加)- (减)* (乘)/ (除)~/ (取整) %(取余) 2.关系运算符 == (等等) != (不等) > ...