漫谈可视化Prefuse(六)---改动源码定制边粗细
可视化一路走来,体会很多;博客一路写来,收获颇丰;代码一路码来,思路越来越清晰。终究还是明白了一句古话:纸上得来终觉浅,绝知此事要躬行。
跌跌撞撞整合了个可视化小tool,零零碎碎结交了众多的志同道合之人,迷迷糊糊创建了我"可视化/Prefuse"的QQ群,详情可查看左侧的公告部分。此群旨在结实更多的可视化领域的同仁,也希望可以成为一个开源项目分享与阅读的平台。源于开源,开源为我们提供了助我们快速成长的养分,开源的每一行代码都是前辈们心血的结晶,开源是智慧的浓缩。
在博客园写博客也是如此,从起初只是一味的平铺直叙,直抒胸臆,从来没有估计到还要格式调整,也没有想到要布局美观,更不用提什么言简意赅、一针见血。总之,看看优秀的博客,就如同接触到一个开源项目,其开篇布局、文章内容、文本样式都是学习的教材。最近体会比较深的就是:写博客也体现出博客的特性,博客,不是论文,过多或者过于复杂的理论阐述(除非必不可少)会让大部分读者两眼昏花、四肢无力;博客,也不是小学造句子,过短或过少缺乏整体的连贯性,刚读起来有点感觉,好吧,还没高潮就结束了,让人摸不着头脑。所以,我发现,但凡获得点赞多的文章除了内容含金量高以外,还赢在表述以及篇幅的控制,真正站在Reader的角度去阐述问题、解决问题,Reader就会控制不住要点个赞。In a Word,路很长,要学的东西很多,慢慢体味。
上期回顾:《漫谈可视化Prefuse(五)---一款属于我自己的可视化工具》主要介绍了自己开发的一款可视化工具,包含了可视化工具中一些必不可少的功能,有些网友反应期待web版,其实Prefuse是支持applet版本的,这里没有走web的原因可能还是根据我们的需求走。要知道在以js为坚实后盾的各种可视化库大行其道的情况下,类似于Gephi、IBM i2等产品仍然具有不可撼动的地位的原因,在于需求催生产品,不同的需求就会对应着不同的产品形态。还有些网友反映披露工具相关细节,下面正文将会有所体现。
本篇主要立足于Prefuse框架讲述:1.可视化工具如何根据需求调整边的粗细;2.try...catch的巧用
1.如何通过边的粗细来反映边的权重
Prefuse框架默认边的粗细是统一的,都为1。但是我们往往面临的需求是给出数据格式如下
| Source | Target | Weight |
| 1 | 2 | 0.5 |
那么我们就可以通过边的粗细来体现这个Weight属性,用来表明节点1和节点2之间的亲密程度。
所以,我们针对Prefuse的源码做一下改动,在此之前,我们先了解有关类的继承关系:
类LabelRenderer:
public class LabelRenderer extends AbstractShapeRenderer {
......
public void render(Graphics2D g, VisualItem item) {
RectangularShape shape = (RectangularShape) getShape(item);
if (shape == null)
return;
......
}
......
}
类EdgeRenderer:
public class EdgeRenderer extends AbstractShapeRenderer {
......
public void render(Graphics2D g, VisualItem item) {
// render the edge line
super.render(g, item);
......
}
......
}
抽象类AbstractShapeRenderer:
public abstract class AbstractShapeRenderer implements Renderer {
......
public void render(Graphics2D g, VisualItem item) {
Shape shape = getShape(item);
......
}
......
}
从以上三个类可以发现,类LabelRenderer和EdgeRenderer都是继承自抽象类AbstractShapeRenderer,并且LabelRenderer和EdgeRenderer类都覆写了父类 render方法。
两个类的render方法的最大不同之处在于,EdgeRenderer类显式调用了抽象父类AbstractShapeRenderer的render方法,并且通过在AbstractShapeRenderer类的render方法中加入:
System.out.println("该item属于:" + item.getGroup())
得到的打印信息都是"该item属于:graph.edges",即表明都是对于边的渲染。
了解了类的继承关系,下面给出修改源码的步骤以实现通过配置文件实现边粗细的赋值:
(1)在PrefuseConfig类中添加:
setProperty("data.edge.weight", "weight");
用于xml文件中确定边粗细的标示,这里是weight;
(2)在Graph类中添加:
public static final String WEIGHT = PrefuseConfig.get("data.edge.weight");
用于在GraphMLReader获取常量;
(3)在GraphMLReader中添加:
public static final String WEIGHT = Graph.WEIGHT;
public static final String WEIGHTID = WEIGHT + '_' + ID;
方法startDocument()中添加:
m_esch.addColumn(WEIGHT, String.class);//边粗细相关
m_esch.addColumn(WEIGHTID, String.class);
方法startElement()中添加:
m_edges.setString(m_row, WEIGHT, atts.getValue(WEIGHT));
m_edges.setString(m_row, WEIGHTID, atts.getValue(WEIGHTID));
(4)在AbstractShapeRenderer中添加:
EdgeItem edge = (EdgeItem)item;
VisualItem vi = (VisualItem)edge.getSourceNode();
item.setStrokeColor(vi.getFillColor());
String weight = null;
try {
weight = item.get(GraphMLHandler.WEIGHT).toString();
} catch (Exception e) {
weight = "1";
}
item.setSize(Double.parseDouble(weight)*10);
使用的配置文件为xml格式,内容为:
<?xml version="1.0" encoding="UTF-8"?>
<!-- An excerpt of an egocentric social network -->
<graphml xmlns="http://graphml.graphdrawing.org/xmlns">
<graph edgedefault="undirected"> <!-- data schema -->
<key id="name" for="node" attr.name="name" attr.type="string"/>
<key id="gender" for="node" attr.name="gender" attr.type="string"/>
<key id="id" for="node" attr.name="id" attr.type="string"/> <!-- nodes -->
<node id="1">
<data key="name">Jeff</data>
<data key="gender">M</data>
<data key="id">1</data>
</node>
<node id="2">
<data key="name">Ed</data>
<data key="gender">M</data>
<data key="id">2</data>
</node>
<node id="3">
<data key="name">Christiaan</data>
<data key="gender">M</data>
<data key="id">3</data>
</node>
<node id="4">
<data key="name">Emily</data>
<data key="gender">F</data>
<data key="id">4</data>
</node>
<node id="5">
<data key="name">Adam</data>
<data key="gender">M</data>
<data key="id">5</data>
</node>
<node id="6">
<data key="name">Cynthia</data>
<data key="gender">F</data>
<data key="id">6</data>
</node>
<node id="7">
<data key="name">Joylette</data>
<data key="gender">F</data>
<data key="id">7</data>
</node>
<node id="8">
<data key="name">Amanda</data>
<data key="gender">F</data>
<data key="id">8</data>
</node>
<node id="9">
<data key="name">Nathaniel</data>
<data key="gender">M</data>
<data key="id">9</data>
</node> <!-- edges -->
<edge source="1" target="2" directed="true" weight="0.1"></edge>
<edge source="2" target="3" weight="0.2"></edge>
<edge source="3" target="1" weight="0.5"></edge>
<edge source="4" target="5" weight="0.2"></edge>
<edge source="5" target="6" weight="0.1"></edge>
<edge source="6" target="4" weight="0.2"></edge>
<edge source="7" target="8" weight="0.3"></edge>
<edge source="8" target="9" weight="0.1"></edge>
<edge source="9" target="7" weight="0.4"></edge>
<edge source="1" target="4" weight="0.1"></edge>
<edge source="4" target="7" weight="0.2"></edge>
<edge source="7" target="1" weight="0.1"></edge>
</graph>
</graphml>
最终的图形显示为:
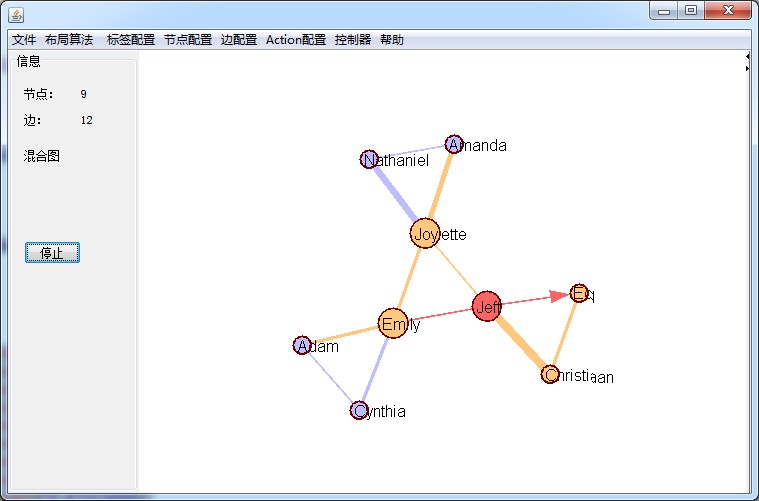
2.try....catch的巧用
巧用之处见1(4)中所写:
EdgeItem edge = (EdgeItem)item;
VisualItem vi = (VisualItem)edge.getSourceNode();
item.setStrokeColor(vi.getFillColor());
String weight = null;
try {
weight = item.get(GraphMLHandler.WEIGHT).toString();
} catch (Exception e) {
weight = "1";
}
item.setSize(Double.parseDouble(weight)*10);
因为在实际情况中,会遇到有些xml文件中没有weight属性,或者xml部分边有部分没有的情况,这时就会面临在AbstractShapeRenderer中无法获取weight值的情形,即
item.get(GraphMLHandler.WEIGHT)
此值不存在或为空,起初通过添加语句:
if(item.get(GraphMLHandler.WEIGHT).toString().equals("") || item.get(GraphMLHandler.WEIGHT).toString() == null){
weight = "1";
}else{
weight = item.get(GraphMLHandler.WEIGHT).toString();
}
等类似手段还是无法捕获item.get()取不到值的所有情况,后面转而想到,鉴于要捕获的是为空异常,索性使用try...catch直接进行捕获,捕获后在进行处理。从而有了上面的处理,即当item.get()函数获取不到值时就捕获异常,转入catch部分执行,在这里我们编写我们想要实现的功能,也就是获取为空时就将weight设置默认值为1,从而巧妙的解决了考虑所有为空的情况。
从该源码的经历发现,需要明确自己想要的功能,明确需要触及哪些类,明确如何保证修改后的源码运行的完整性,不能因为修改一处而到处报错;另外,还需要经常思考,灵活运行一些语句的特性为自己所用。今天就到这吧,如果觉得有用,记得点赞^_^,对可视化(gephi、prefuse、分布式计算、开源)感兴趣的可以加群讨论。
本文链接:《漫谈可视化Prefuse(六)---改动源码定制边粗细》
友情赞助
如果你觉得博主的文章对你那么一点小帮助,恰巧你又有想打赏博主的小冲动,那么事不宜迟,赶紧扫一扫,小额地赞助下,攒个奶粉钱,也是让博主有动力继续努力,写出更好的文章^^。
1. 支付宝 2. 微信


漫谈可视化Prefuse(六)---改动源码定制边粗细的更多相关文章
- 漫谈可视化Prefuse(六)
可视化一路走来,体会很多:博客一路写来,收获颇丰:代码一路码来,思路越来越清晰.终究还是明白了一句古话:纸上得来终觉浅,绝知此事要躬行. 跌跌撞撞整合了个可视化小tool,零零碎碎结交了众多的志同道合 ...
- 漫谈可视化Prefuse(五)---一款属于我自己的可视化工具
伴随着前期的基础积累,翻过API,读过一些Demo,总觉得自己已经摸透了Prefuse,小打小闹似乎已经无法满足内心膨胀的自己.还记得儿时看的<武状元苏乞儿>中降龙十八掌最后一张居然是空白 ...
- 漫谈可视化Prefuse(五)
伴随着前期的基础积累,翻过API,读过一些Demo,总觉得自己已经摸透了Prefuse,小打小闹似乎已经无法满足内心膨胀的自己.还记得儿时看的<武状元苏乞儿>中降龙十八掌最后一张居然是空白 ...
- 漫谈可视化Prefuse(二)---一分钟学会Prefuse
前篇<漫谈可视化Prefuse(一)---从SQL Server数据库读取数据>主要介绍了prefuse如何连接数据库sql server并读取数据进行可视化展现. 回头想想还是应该好好捋 ...
- 漫谈可视化Prefuse(四)---被玩坏的Prefuse API
这个双12,别人都在抢红包.逛淘宝.上京东,我选择再续我的“漫谈可视化”系列(好了,不装了,其实是郎中羞涩...) 上篇<漫谈可视化Prefuse(三)---Prefuse API数据结构阅读有 ...
- 漫谈可视化Prefuse(三)---Prefuse API数据结构阅读有感
前篇回顾:上篇<漫谈可视化Prefuse(二)---一分钟学会Prefuse>主要通过一个Prefuse的具体实例了解了构建一个Prefuse application的具体步骤.一个Pre ...
- 38 网络相关函数(六)——live555源码阅读(四)网络
38 网络相关函数(六)——live555源码阅读(四)网络 38 网络相关函数(六)——live555源码阅读(四)网络 简介 12)makeSocketNonBlocking和makeSocket ...
- 安卓图表引擎AChartEngine(六) - 框架源码结构图
包结构: org.achartengine: org.achartengine.model: org.achartengine.renderer: org.achartengine.tools: 安卓 ...
- 用Scratch2.0源码定制一个自己的编辑器
用Scratch2.0源码定制一个自己的编辑器,换成自己的软件名称和图标,添加中文字体,修复汉化错误等等1.准备:下载Scratch2.0源码.安装开发工具Adobe Flash Builder4.7 ...
随机推荐
- 【C++】DDX_Control、SubclassWindow和SubclassDlgItem的区别
在自绘窗口的时候,子类化是MFC最常用的窗体技术之一.什么是子类化?窗口子类化就是创建一个新的窗口函数代替原来的窗口函数. Subclass(子类化)是MFC中最常用的窗体技术之一.子类化完成两个工作 ...
- samba server install
要求: create vnc service for win7 access it via vnc viewer. 1TB disk for this Centos PC is used as Sam ...
- iPhone的Push(推送通知)功能原理浅析
第一部分:Push原理(以下绝大多数内容参考自.图片来自iPhone OS Reference Library)机制简介Push 的工作机制可以简单的概括为下图图中,Provider是指某个iPhon ...
- distinct order by 排序问题
使用类似“SELECT DISTINCT `col` FROM `tb_name` ORDER BY `time` DESC”这样的sql语句时,会遇到排序问题. 以上面的sql语句分析:order ...
- Hibernate自动创建表
只要在hibernate.cfg.xml添加这句话,就可以自动生成数据表 <property name="hibernate.hbm2ddl.auto">update& ...
- 开始VS 2012中LightSwitch系列的第5部分:我可以使用用户权限来控制访问权吗?
[原文发表地址] Beginning LightSwitch in VS 2012 Part 5: May I? Controlling Access with User Permissions [ ...
- WPF快速入门系列(7)——深入解析WPF模板
一.引言 模板从字面意思理解是“具有一定规格的样板".在现实生活中,砖块都是方方正正的,那是因为制作砖块的模板是方方正正的,如果我们使模板为圆形的话,则制作出来的砖块就是圆形的,此时我们并不 ...
- 分享一个简单程序(webApi+castle+Automapper+Ef+angular)
前段时间在周末给朋友做了一个小程序,用来记录他们单位的一些调度信息(免费,无版权问题).把代码分享出来.整个程序没有做任何架构.但是麻雀虽小,用到的技术也没少.WebApi+Castle+AutoMa ...
- Java语法糖4:内部类
内部类 最后一个语法糖,讲讲内部类,内部类指的就是在一个类的内部再定义一个类. 内部类之所以也是语法糖,是因为它仅仅是一个编译时的概念,outer.java里面定义了一个内部类inner,一旦编译成功 ...
- 浏览器兼容性小记-DOM篇(一)
1.childNodes引入空白节点问题:使用childElementCount或children 2.innerText: FF中不支持该属性,使用textContent代替 3.变量名与某HTML ...