Tesseract-OCR字符识别简介
OCR(Optical Character Recognition):光学字符识别,是指对图片文件中的文字进行分析识别,获取的过程。
Tesseract:开源的OCR识别引擎,初期Tesseract引擎由HP实验室研发,后来贡献给了开源软件业,后经由Google进行改进,消除bug,优化,重新发布。
项目地址:https://github.com/tesseract-ocr
该项目最新版本是3.04,本人试验用的版本是3.02。
1 安装并设置环境
运行tesseract-ocr-setup-3.02.02.exe程序安装tesseract,如图所示,图中的jTessBoxEditor相关内容用于其他测试与本文无关。
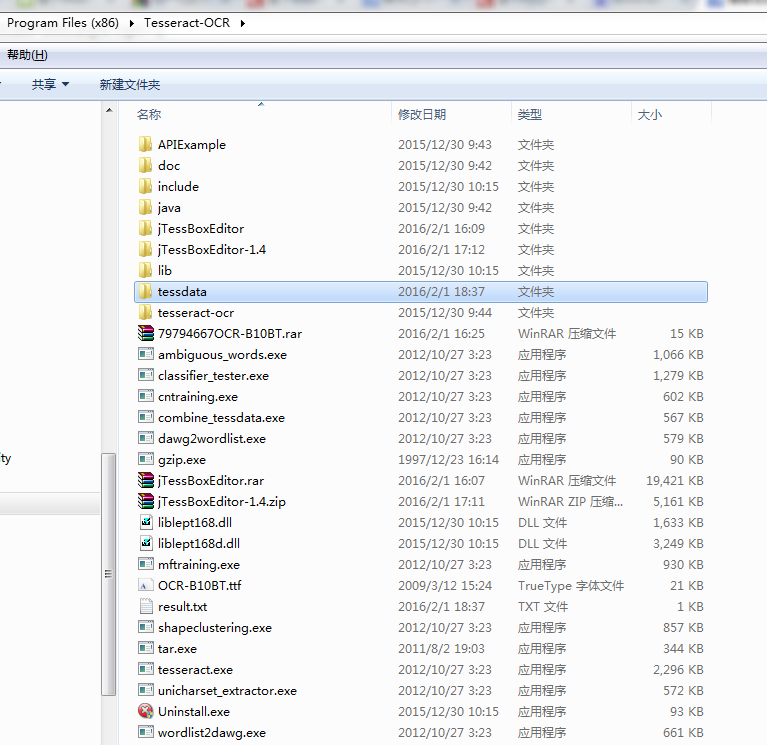
安装完成后为了能在cmd命令行直接使用tesseract.exe,向path环境变量中增加tesseract安装目录,同时添加环境变量TESSDATA_PREFIX,其值是训练数据tessdata所在的目录,例如图中为:F:\Program Files (x86)\Tesseract-OCR,该目录也可以由参数
--tessdata-dir指明,详细见第2节参数介绍。
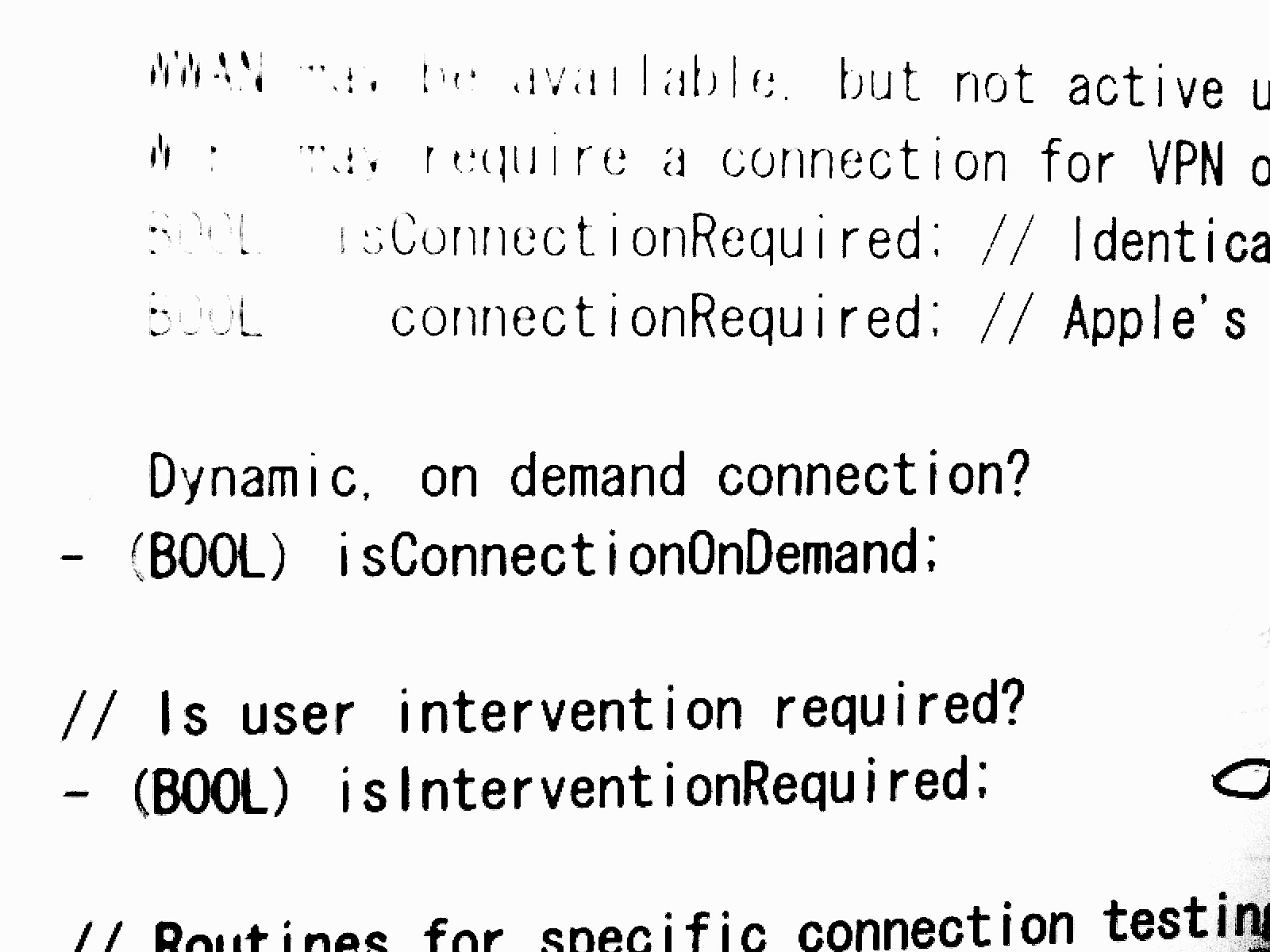
2 参数介绍
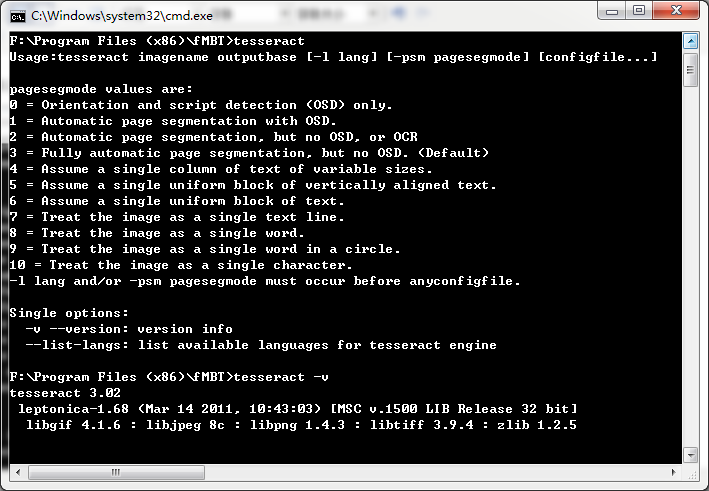
在命令行直接输入tesseract回车后可看到它的帮助信息,如图所示:
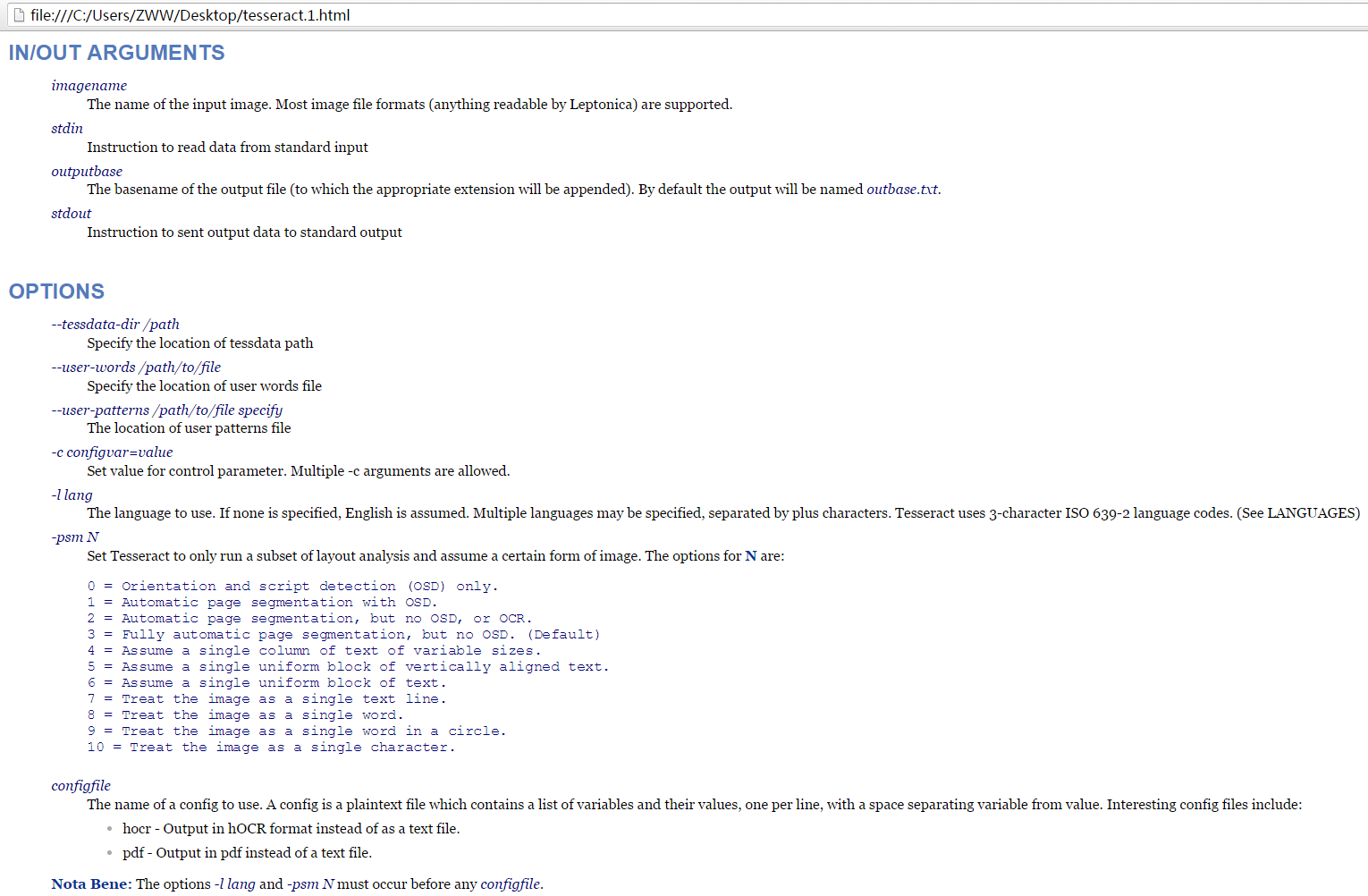
更详细的参数说明请参考:https://github.com/tesseract-ocr/tesseract/blob/master/doc/tesseract.1.html,部分内容如下图:
一般来说,可以使用如下的格式来使用tesseract:
tesseract imagename outputbase [-l lang] [-psm pagesegmode] [configfile...]
tesseract 图片名 输出文件名 -l 字库文件 -psm pagesegmode 配置文件
3 实例
如要识别如下图片,可以直接使用简单的命令:tesseract test.png result,即可将识别结果输出到result.txt文件中

识别结果如下:
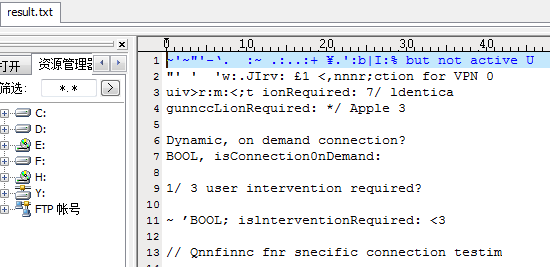
可以看出识别效果不是特别理想,所以识别前可对识别的图像进行预处理,典型处理如:增加对比度、二值化等,如对上一幅图进行预处理后如下图所示:
生成识别结果时,可以使用hocr参数来让tesseract生成html格式的结果文件,如:tesseract binary.png result hocr,识别结果如下:

对比可以看出预处理后的识别效果要明显优于之前的识别效果,生成html格式的识别文件还有另外一个好处,即可以获得识别字符在原图片上面的坐标信息,用文本编辑器打开上面的rusult.html文件,内容如图:

从图中红色方框内可以看出识别出的字符串user在原图片中的坐标信息(306,884)左上角,(445,926)右下角。此外之前版本还支持识别信心值,但从3.02版本以后该特性被去掉了,相关内容请参考:http://blog.csdn.net/sosoben/article/details/13768895
4 结语
以上只是简单介绍了tesseract的英文字符识别功能,其实它支持很多语言的识别,另外它还支持样本训练等,更深入的应用请查找其他文献。
Tesseract-OCR字符识别简介的更多相关文章
- 应用OpenCV进行OCR字符识别
opencv自带一个字符识别的例子,它的重点不是OCR字符识别,而主要是演示机器学习的应用.它应用的是UCI提供的字符数据(特征数据). DAMILES在网上发布了一个应用OpenCV进行OCR的例子 ...
- tesseract ocr文字识别Android实例程序和训练工具全部源代码
tesseract ocr是一个开源的文字识别引擎,Android系统中也可以使用.可以识别50多种语言,通过自己训练识别库的方式,可以大大提高识别的准确率. 为了节省大家的学习时间,现将自己近期的学 ...
- Tesseract——OCR图像识别 入门篇
Tesseract——OCR图像识别 入门篇 最近给了我一个任务,让我研究图像识别,从我们项目的screenshot中识别文字信息,so我开始了学习,与大家分享下. 我看到目前OCR技术有很多,最主要 ...
- Tesseract Ocr引擎
Tesseract Ocr引擎 1.Tesseract介绍 tesseract 是一个google支持的开源ocr项目,其项目地址:https://github.com/tesseract-ocr/t ...
- 开源图片文字识别引擎——Tesseract OCR
Tessseract为一款开源.免费的OCR引擎,能够支持中文十分难得.虽然其识别效果不是很理想,但是对于要求不高的中小型项目来说,已经足够用了. 文字识别可应用于许多领域,如阅读.翻译.文献资料的检 ...
- Python下Tesseract Ocr引擎及安装介绍
1.Tesseract介绍 tesseract 是一个google支持的开源ocr项目,其项目地址:https://github.com/tesseract-ocr/tesseract,目前最新的源码 ...
- Tesseract OCR使用介绍
#Tesseract OCR使用介绍 ##目录[TOC] ##下载地址及介绍 官网介绍:http://code.google.com/p/tesseract-ocr/wiki/TrainingTess ...
- selenium使用笔记(二)——Tesseract OCR
在自动化测试过程中我们经常会遇到需要输入验证码的情况,而现在一般以图片验证码居多.通常我们处理这种情况应该用最简单的方式,让开发给个万能验证码或者直接将验证码这个环节跳过.之前在技术交流群里也跟朋友讨 ...
- Tesseract ocr 3.02学习记录一
光学字符识别(OCR,Optical Character Recognition)是指对文本资料进行扫描,然后对图像文件进行分析处理,获取文字及版面信息的过程.OCR技术非常专业,一般多是印刷.打印行 ...
随机推荐
- JAVA回调机制(CallBack)详解
序言 最近学习java,接触到了回调机制(CallBack).初识时感觉比较混乱,而且在网上搜索到的相关的讲解,要么一言带过,要么说的比较单纯的像是给CallBack做了一个定义.当然了,我在理解了回 ...
- JavaScript性能优化
如今主流浏览器都在比拼JavaScript引擎的执行速度,但最终都会达到一个理论极限,即无限接近编译后程序执行速度. 这种情况下决定程序速度的另一个重要因素就是代码本身. 在这里我们会分门别类的介绍J ...
- 【Web动画】SVG 实现复杂线条动画
在上一篇文章中,我们初步实现了一些利用基本图形就能完成的线条动画: [Web动画]SVG 线条动画入门 当然,事物都是朝着熵增焓减的方向发展的,复杂线条也肯定比有序线条要多. 很多时候,我们无法人工去 ...
- .net 分布式架构之业务消息队列
开源QQ群: .net 开源基础服务 238543768 开源地址: http://git.oschina.net/chejiangyi/Dyd.BusinessMQ ## 业务消息队列 ##业务消 ...
- ASP.NET MVC开发日常一:SessionID合理清除
在MVC Web开发中临时存储数据一般会用到Session,Cookie,ViewBag,ViewData,TempData.每个的使用场景是不同,具体区别有空再补上. Session数据最敏感,最需 ...
- jQuery可自动播放动画焦点图插件Koala
Koala是一款简单而实用的jQuery焦点图幻灯片插件,焦点图不仅可以在播放图片的时候让图片有淡入淡出的动画效果,而且图片可以自动播放.该jQuery焦点图的每一张图片都可以设置文字描述,并浮动在图 ...
- arcgis api for js入门开发系列六地图分屏对比(含源代码)
上一篇实现了demo的地图标绘模块,本篇新增地图地图分屏对比模块,截图如下(源代码见文章底部): 对效果图的简单介绍一下,在demo只采用了两分屏对比,感兴趣的话,可以在两分屏的基础上拓展,修改css ...
- 信息安全-2:python之hill密码算法[原创]
转发注明出处:http://www.cnblogs.com/0zcl/p/6106513.html 前言: hill密码算法我打算简要介绍就好,加密矩阵我用教材上的3*3矩阵,只做了加密,解密没有做, ...
- (整理)MyBatis入门教程(一)
本文转载: http://www.cnblogs.com/hellokitty1/p/5216025.html#3591383 本人文笔不行,根据上面博客内容引导,自己整理了一些东西 首先给大家推荐几 ...
- Jquery EasyUI 开发实录
有好几年没有用过EasyUI了,最近在外包做的一个项目中新增功能时,又用到了,本以为和按照以前那样用就可以了,可当我真正用的时候,发现许多地方不一样了,就连官网的文档都更新了,最突出的就是不知道什么时 ...