UUID那些事
UUID那些事
UUID 是一个全局唯一的通用识别码。它使用某种规则,而不是某种中心化的自增方式,来保证这个识别码的全局唯一性。UUID 有非常多的使用场景,比如在分布式系统中,需要生成全局唯一 ID 来进行日志记录。UUID 的生成规则由 rfc4122 来进行定义。
UUID 和 GUID 的区别
其实是没有区别的,GUID 是微软按照 UUID 的规则实现的一套方法。它本质的目的也是为了保证全局唯一性。微软已经使用 GUID 在 Windows 的 COM,ActiveX 等技术上了。但是这里注意的一点是,UUID 本质是有多种版本的,GUID 也是在不同的使用场景实现的是不同的 UUID 版本,比如 COM 是使用 UUID 版本1 进行实现的。所以,在聊 UUID 和 GUID 是不是一样的时候,附带的信息应该了解清楚版本信息。
版本
UUID 是有不同的版本的,每个版本有不同的适用场景,比如,版本4 建议使用随机方式生成所有的可变因子。在很多场景下,这个其实是一个非常方便的实现方式。版本1 使用的是 时间戳+时钟序列+节点信息(机器信息)在一些分布式系统场景下是能严格保证全局唯一的。twitter 的 snowflake 可以看作是是 UUID 版本1 的简化版。
到现在为止,UUID 一共有5个实现版本:
- 版本1: 严格按照 UUID 定义的每个字段的意义来实现,使用的变量因子是时间戳+时钟序列+节点信息(Mac地址)
- 版本2: 基本和版本1一致,但是它主要是和 DCE( IBM 的一套分布式计算环境)。但是这个版本在 ietf 中也没有具体描述,反而在DCE 1.1: Authentication and Security Services这篇文档中说到了具体实现。所以这个版本现在很少使用到,并且很多地方的实现也都忽略了它。
- 版本3: 基于 name 和 namespace 的 hash 实现变量因子,版本3使用的是 md5 进行 hash 算法。
- 版本4: 使用随机或者伪随机实现变量因子。
- 版本5: 基于 name 和 namespace 的 hash 实现变量因子,版本5使用的是 sha1 进行 hash 算法。
不管是 UUID 的哪个版本,它的结构都是一样的,这个结构是按照版本1进行定义的,只是在其他版本中,版本1中的几个变量因子都进行了变化。
UUID 基本结构
UUID 长度是128bit,换算为16进制数值(每4位代表一个数值)就是有32个16进制数值组成,中间使用4个-进行分隔,按照8-4-4-4-12的顺序进行分隔。加上中间的横杆,UUID有36个字符。
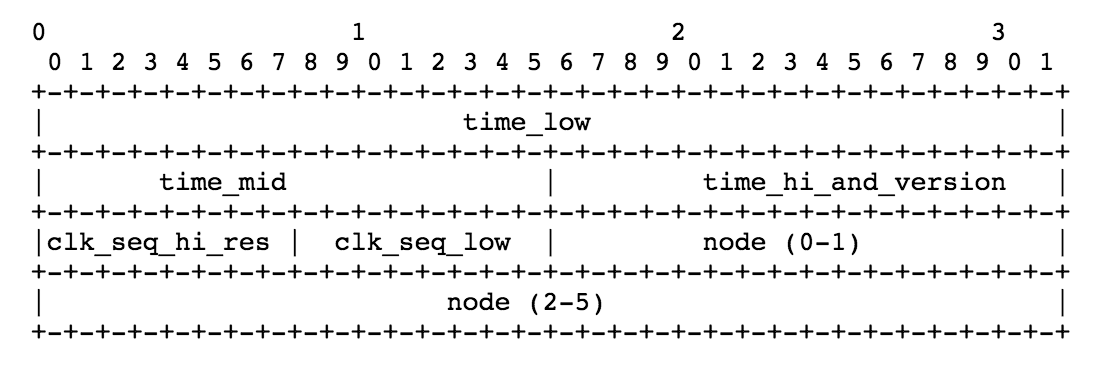
这个图是 UUID 的具体结构。它的可变因子有三个,Timestamp 时间戳,Clock Sequence时钟序列,node节点信息。然后由他们的不同部分组成这个 UUID。
Timestamp
时间戳是其中一个可变因子。时间戳有长度为 60bit。它代表现在当前UTC时间(必须使用UTC时间,这样就统一了时区)和1582-10-15 00:00:000000000,每100纳米加一。对于无法获取UTC时间的系统,由于获取不到UTC,那么你可以统一采用 localtime。(实际上一个系统时区相同就可以了)。
有了时间戳之后,结构图中的time_low,time_mid,time_hi就知道了
time_low
是 timestamp 60bit 中的 0~31bit,共32bit
time_mid
是 timestamp 60bit 中的 32~47bit,共16bit
time_hi_and_version
这个字段的意思很明确,就是包含两个部分,version 和 time_hi。version 占用 bit 数为4. 代表它最多可以支持31个版本。time_hi就是timestamp剩余的12bit,一共是16bit。
Clock Sequence
如果计算 UUID 的机器进行了时间调整,或者是 nodeId 变化了(主机更换网卡),和其他的机器冲突了。那么这个时候,就需要有个变量因子进行变化来保证再次生成的 UUID 的唯一性。
其实Clock Sequence的变化算法很简单,当时间调整,或者 nodeId 变化的时候,直接使用一个随机数,或者,在原先的Clock Sequence值上面自增加一也是可以的。
Clock Sequence 一共是14bit
clock_seq_low
是 Clock Sequence 中的 0~7 bit 共8bit
clock_seq_hi_and_reserved
包含两个部分,reserved 和 clock_seq_hi。其中 clock_seq_hi 为 Clock Sequence 中的 8~13 bit 共6个bit,reserved是2bit,reserved 一般设置为10。
node
node 这个变量因子由MAC地址组成,通常是IP地址。它有48bit大小。其中的 0-15填入node(0-1)的位置,16-47填入node(2-5)的位置。
不同版本
基本上,按照上节说的已经把 UUID 的结构构成说明清楚了。基本上这个结构构成是 UUID version1 的定义。我们可以看到,它有的变量因子是 timestamp, clock sequence, node。
在不同版本中,这几个变量因子的含义是不同的。
version4
在version4 中,timestamp,clock sequence, node都是随机或者伪随机的。
version3&5
version3和5 叫做基于 name 和 namesapce 的 hash 结构生成。其中的name 和namespace 基本上和我们很多语言的命名空间,类名一样,它的基本要求就是,name + namespace 才是唯一确定hash串的标准。换句话说,一样的namespace + name 使用的hash算法(比如version3的md5)计算出来的结果必须是一样的,但是不同的 namespace 中的同样的 name 生成的结果是不一样的。
version3 和 version5 中的三个变量因子都是由hash 算法保证的,version3是 md5, version5是sha1。
参考文档
wiki
理解UUID
分布式UniqueID的生成方法一览
关于UUID的二三事
UUID那些事的更多相关文章
- JAVA UUID 生成
UUID是指在一台机器上生成的数字,它保证对在同一时空中的所有机器都是唯一的.通常平台会提供生成UUID的API.UUID按照开放软件基金会(OSF)制定的标准计算,用到了以太网卡地址.纳秒级时间.芯 ...
- java生成随机字符串uuid
GUID是一个128位长的数字,一般用16进制表示.算法的核心思想是结合机器的网卡.当地时间.一个随即数来生成GUID.从理论上讲,如果一台机器每秒产生10000000个GUID,则可以保证(概率意义 ...
- iOS 证书那些事
关于开发证书配置(Certificates & Identifiers & Provisioning Profiles),相信做iOS开发的同学没少被折腾.对于一个iOS开发小白.半吊 ...
- Java日志性能那些事(转)
在任何系统中,日志都是非常重要的组成部分,它是反映系统运行情况的重要依据,也是排查问题时的必要线索.绝大多数人都认可日志的重要性,但是又有多少人仔细想过该怎么打日志,日志对性能的影响究竟有多大呢?今天 ...
- 如何在高并发的分布式系统中产生UUID
一.数据库发号器 每一次都请求数据库,通过数据库的自增ID来获取全局唯一ID 对于小系统来说,这是一个简单有效的方案,不过也就不符合讨论情形中的高并发的场景. 首先,数据库自增ID需要锁表 而且,UU ...
- 刚安装Fedora 23工作站后,你必须要做的24件事
[51CTO.com快译]Fedora 23工作站版本已发布,此后我们就一直在密切关注它.我们已经为新来读者介绍了一篇安装指南:<Fedora 23工作站版本安装指南> 还有一篇介绍如何从 ...
- spring data jpa、Hibernate开启全球唯一UUID设置
spring data jpa.Hibernate开启全球唯一UUID设置 原文链接:https://www.cnblogs.com/blog5277/p/10662079.html 原文作者:博客园 ...
- Linux系统启动那些事—基于Linux 3.10内核【转】
转自:https://blog.csdn.net/shichaog/article/details/40218763 Linux系统启动那些事—基于Linux 3.10内核 csdn 我的空间的下载地 ...
- 文件上传中UUID的解读
UUID简介如下:1.简介UUID含义是通用唯一识别码 (Universally Unique Identifier),这 是一个软件建构的标准,也是被开源软件基金会 (Open Software F ...
随机推荐
- 【一天一道LeetCode】#49. Group Anagrams
一天一道LeetCode系列 (一)题目 Given an array of strings, group anagrams together. For example, given: [" ...
- (二十七)QQ好友列表的实现
QQ好友列表通过plist读取,plist的结构为一组字典,每个字典内有本组的信息和另外一组字典代表好友. 要读取plist,选择合适的数据结构,例如NSArray,然后调用initWithConte ...
- Mahout 模糊kmeans
Mahout 模糊KMeans 一.算法流程 模糊 C 均值聚类(FCM),即众所周知的模糊 ISODATA,是用隶属度确定每个数据点属于某个聚类的程度的一种聚类算法.1973 年,Bezdek 提 ...
- Android Studio 1.2.2设置显示行号
Android Studio设置显示行号的方法与Eclipse有少许差别,直接在代码中右键,弹出右键菜单是没有显示行号功能的. 在Android Studio中设置方法有二: 1.临时显示行号 在单个 ...
- Linux用户管理命令(第二版)
添加用户 1.useradd -设置选项 用户名 [-D 查看缺省参数 ] 选项: u: UID [必须是系统中没有的] g:缺省所属用户组GID[最好有] G: 指定用户所属多个组[可以指定这个用户 ...
- Unity UGUI
超详细的基础教程传送门:(持续更新中) Unity UGUI之Canvas&EventSystem:http://blog.csdn.net/qq992817263/article/detai ...
- ZooKeeper客户端事件串行化处理
为了提升系统的性能,进一步提高系统的吞吐能力,最近公司很多系统都在进行异步化改造.在异步化改造的过程中,肯定会比以前碰到更多的多线程问题,上周就碰到ZooKeeper客户端异步化过程中的一个死锁问题, ...
- 面试之路(27)-链表中倒数第K个结点
代码的鲁棒性: 所谓的鲁棒性是指能够判断输入是否合乎规范,能对不和规范的程序进行处理. 容错性是鲁棒性的一个重要体现. 防御性编程有助于提高鲁棒性. 切入正题,我可不是标题党: 链表倒数第k个节点 列 ...
- Leetcode(59)-Count Primes
题目: Description: Count the number of prime numbers less than a non-negative number, n. 思路: 题意:求小于给定非 ...
- opencv基本图像操作
// Basic_OpenCV_2.cpp : 定义控制台应用程序的入口点. // #include "stdafx.h" #include <iostream> #i ...