hadoop2.7.3+spark2.1.0+scala2.12.1环境搭建(4)SPARK 安装
hadoop2.7.3+spark2.1.0+scala2.12.1环境搭建(4)SPARK 安装
一、依赖文件安装
1.1 JDK
参见博文:http://www.cnblogs.com/liugh/p/6623530.html
1.2 Hadoop
参见博文:http://www.cnblogs.com/liugh/p/6624872.html
1.3 Scala
参见博文:http://www.cnblogs.com/liugh/p/6624491.html
二、文件准备
spark-2.1.0-bin-hadoop2.7.tgz
下载地址:http://spark.apache.org/downloads.html
三、工具准备
3.1 Xshell
3.2 Xftp
四、部署图
master:192.168.136.128
slave:192.168.136.129
slave:192.168.136.130
五、Spark安装
以下操作,均使用root用户
5.1 通过Xftp将下载下来的Spark安装文件上传到Master及两个Slave的/usr目录下
5.2 通过Xshell连接到虚拟机,在Master及两个Slave上,执行如下命令,解压文件:
# tar zxvf spark-2.1.0-bin-hadoop2.7.tgz
5.3 在Master上,使用Vi编辑器,设置环境变量
# vi /etc/profile
在文件最后,添加如下内容:
#Spark Env
export SPARK_HOME=/usr/spark-2.1.0
export PATH=PATH:PATH:SPARK_HOME/bin:$SPARK_HOME/sbin
5.4 退出vi编辑器,使环境变量设置立即生效
# source /etc/profile
通过scp命令,将/etc/profile拷贝到两个Slave节点:
#scp /etc/profile root@DEV-SH-MAP-02:/etc
#scp /etc/profile root@DEV-SH-MAP-03:/etc
分别在两个Salve节点上执行# source /etc/profile使其立即生效
六、Spark配置
以下操作均在Master节点,配置完后,使用scp命令,将配置文件拷贝到两个Worker节点即可。
切换到/usr/spark-2.1.0/conf/目录下,修改如下文件:
6.1 spark-env.sh
将spark-env.sh.template重命名为spark-env.sh
#mv spark-env.sh.template spark-env.sh
使用vi编辑器,打开spark-env.sh,在文件最后,添加如下内容:
export JAVA_HOME=/usr/jdk1.8.0_121
export SCALA_HOME=/usr/scala-2.12.1
export SPARK_MASTER_IP=10.10.0.1
export SPARK_WORKER_MEMORY=1g
export HADOOP_CONF_DIR=/usr/hadoop-2.7.3/etc/hadoop
6.2 slaves
将slaves.template重命名为slaves
#mv slaves.template slaves
使用vi编辑器,打开slaves,在文件最后,添加如下内容:
DEV-SH-MAP-01
DEV-SH-MAP-02
DEV-SH-MAP-03
6.3 拷贝配置文件到两个Worker节点
在Master节点,执行如下命令:
# scp -r /usr/spark-2.1.0/conf/ root@DEV-SH-MAP-02:/usr/spark-2.1.0/
# scp -r /usr/spark-2.1.0/conf/ root@DEV-SH-MAP-03:/usr/spark-2.1.0/
七、Spark使用
7.1 启动Hadoop集群
参见博文:http://www.cnblogs.com/liugh/p/6624872.html
7.2 启动Master节点
Master节点上,执行如下命令:
#start-master.sh
使用jps命令,查看Java进程:
34225 SecondaryNameNode
33922 NameNode49702 Jps
34632 NodeManager
34523 ResourceManager
34028 DataNode
36415 Master
7.3 启动Worker节点
Master节点上,执行如下命令:
#start-slaves.sh
使用jps命令,查看Java进程:

34225 SecondaryNameNode
33922 NameNode
36562 Worker
49702 Jps
34632 NodeManager
34523 ResourceManager
34028 DataNode
36415 Master
7.4 通过浏览器查看Spark信息
浏览器中,输入http://10.10.0.1:8080
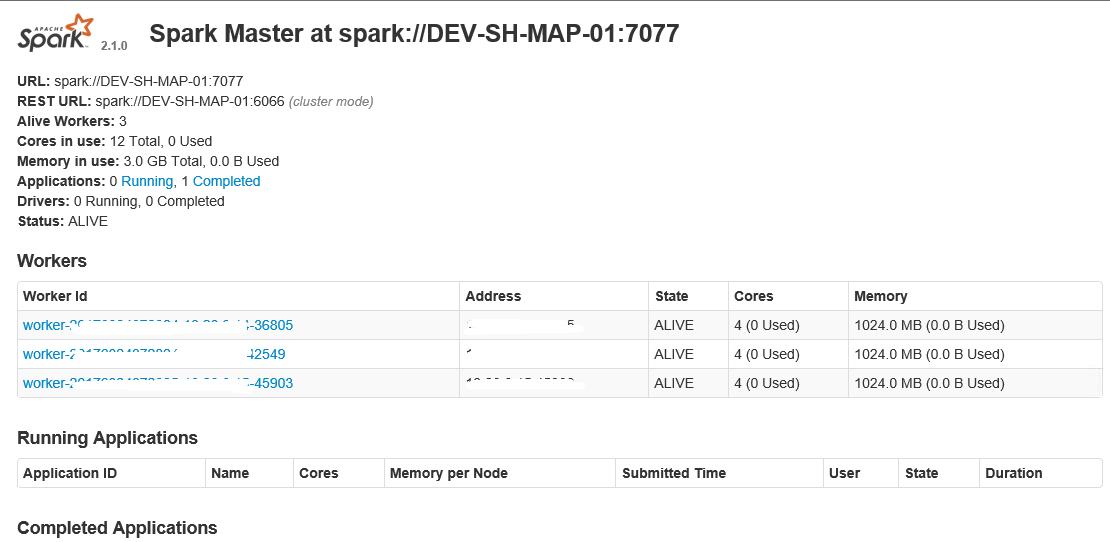
7.5 停止Master及Workder节点
#stop-master.sh
#stop-slaves.sh
hadoop2.7.3+spark2.1.0+scala2.12.1环境搭建(4)SPARK 安装的更多相关文章
- hadoop2.7.3+spark2.1.0+scala2.12.1环境搭建(3)http://www.cnblogs.com/liugh/p/6624491.html
一.文件准备 scala-2.12.1.tgz 下载地址: http://www.scala-lang.org/download/2.12.1.html 二.工具准备 2.1 Xshell 2.2 X ...
- hadoop2.7.3+spark2.1.0+scala2.12.1环境搭建(2)安装hadoop
一.依赖安装 安装JDK 二.文件准备 hadoop-2.7.3.tar.gz 2.2 下载地址 http://hadoop.apache.org/releases.html 三.工具准备 3.1 X ...
- hadoop2.7.3+spark2.1.0+scala2.12.1环境搭建(1)安装jdk
一.文件准备 下载jdk-8u131-linux-x64.tar.gz 二.工具准备 2.1 Xshell 2.2 Xftp 三.操作步骤 3.1 解压文件: $ tar zxvf jdk-8u131 ...
- Hadoop2.7.3+Spark2.1.0完全分布式集群搭建过程
1.选取三台服务器(CentOS系统64位) 114.55.246.88 主节点 114.55.246.77 从节点 114.55.246.93 从节点 之后的操作如果是用普通用户操作的话也必须知道r ...
- Hadoop2.7.3+Spark2.1.0 完全分布式环境 搭建全过程
一.修改hosts文件 在主节点,就是第一台主机的命令行下; vim /etc/hosts 我的是三台云主机: 在原文件的基础上加上; ip1 master worker0 namenode ip2 ...
- Apache Spark1.1.0部署与开发环境搭建
Spark是Apache公司推出的一种基于Hadoop Distributed File System(HDFS)的并行计算架构.与MapReduce不同,Spark并不局限于编写map和reduce ...
- Windows Server 2003 IIS6.0+PHP5(FastCGI)+MySQL5环境搭建教程
准备篇 一.环境说明: 操作系统:Windows Server 2003 SP2 32位 PHP版本:php 5.3.14(我用的php 5.3.10安装版) MySQL版本:MySQL5.5.25 ...
- Cocos2dx-3.0版本 从开发环境搭建(Win32)到项目移植Android平台过程详解
作为重量级的跨平台开发的游戏引擎,Cocos2d-x在现今的手游开发领域占有重要地位.那么问题来了,作为Cocos2dx的学习者,它的可移植特性我们就需要掌握,要不然总觉得少一门技能.然而这个时候各种 ...
- SDL2.0的VS开发环境搭建
SDL2.0的VS开发环境搭建 [前言] 我是用的是VS2012,VS的版本应该大致一样. [开发环境搭建] >>>SDL2.0开发环境配置:1.从www.libsdl.org 下载 ...
随机推荐
- es6学习笔记--新数据类型Symbol
学习了es6语法的symbol类型,整理笔记,闲时复习. Symbol 是es6新增的第七种原始数据类型(null,string,number,undefined,boolean,object),是为 ...
- MySQL异步、同步、半同步复制
异步复制 MySQL复制默认是异步复制,Master将事件写入binlog,提交事务,自身并不知道slave是否接收是否处理: 缺点:不能保证所有事务都被所有slave接收. 同步复制 Master提 ...
- Eclipse 基础操作与设置
1.快捷键 ctrl+F 在某个文档里搜索对应字段 ctrl+H 全文件查询对应字段 ctrl +shift +R 快速查找某个java类 ctrl +shift +O 自动导入需要的包,删除没用过的 ...
- Linux(CentOS 7)环境下安装MySQL
在CentOS中默认安装有MariaDB,但是我们需要的是MySQL,安装MySQL可以覆盖MariaDB MariaDB数据库管理系统是MySQL的一个分支,主要由开源社区在维护,采用GPL授权许可 ...
- [POJ 2226] Muddy Fields
题目 Description 如何放木板保证只覆盖到 '*' 而没有覆盖到 '.' Solution (我太废了竟然想这题想了一个小时)考虑当前需要被覆盖的点 (x,y),假设有一块横着铺的木板 i ...
- 详细分析SQL语句逻辑执行过程和相关语法
本文目录: 1.SQL语句的逻辑处理顺序 1.2 各数据库系统的语句逻辑处理顺序 1.2.1 SQL Server和Oracle的逻辑执行顺序 1.2.2 MariaDB的逻辑执行顺序 1.2.3 M ...
- 移动web开发之rem的使用
为什么要使用rem 移动端设备尺寸五花八门,单纯使用px这个单位无法轻易适配,rem就可以为我们解决这个问题! 如何使用rem 1rem默认等于16px,这是因为页面的默认字体大小就是16px.r 代 ...
- MySQL_执行计划详细说明
1 简要说明 id 表格查询的顺序编号. 降序查看,id相同的从上到下查查看. id可以为null ,当table为( union ,m,n )类型的时候,id为null,这个时候,id的 ...
- python scrapy框架爬虫遇到301
1.什么是状态码301 301 Moved Permanently(永久重定向) 被请求的资源已永久移动到新位置,并且将来任何对此资源的引用都应该使用本响应返回的若干个URI之一.如果可能,拥有链接编 ...
- Windows下Apache的下载安装启动停止
一:下载 打开任意浏览器,输入网址:http://httpd.apache.org/ 进入如下界面: 我们选择最新版Apache httpd 2.4.12Released,点击Download,进入如 ...