hadoop2.7.3+spark2.1.0+scala2.12.1环境搭建(4)SPARK 安装
hadoop2.7.3+spark2.1.0+scala2.12.1环境搭建(4)SPARK 安装
一、依赖文件安装
1.1 JDK
参见博文:http://www.cnblogs.com/liugh/p/6623530.html
1.2 Hadoop
参见博文:http://www.cnblogs.com/liugh/p/6624872.html
1.3 Scala
参见博文:http://www.cnblogs.com/liugh/p/6624491.html
二、文件准备
spark-2.1.0-bin-hadoop2.7.tgz
下载地址:http://spark.apache.org/downloads.html
三、工具准备
3.1 Xshell
3.2 Xftp
四、部署图
master:192.168.136.128
slave:192.168.136.129
slave:192.168.136.130
五、Spark安装
以下操作,均使用root用户
5.1 通过Xftp将下载下来的Spark安装文件上传到Master及两个Slave的/usr目录下
5.2 通过Xshell连接到虚拟机,在Master及两个Slave上,执行如下命令,解压文件:
# tar zxvf spark-2.1.0-bin-hadoop2.7.tgz
5.3 在Master上,使用Vi编辑器,设置环境变量
# vi /etc/profile
在文件最后,添加如下内容:
#Spark Env
export SPARK_HOME=/usr/spark-2.1.0
export PATH=PATH:PATH:SPARK_HOME/bin:$SPARK_HOME/sbin
5.4 退出vi编辑器,使环境变量设置立即生效
# source /etc/profile
通过scp命令,将/etc/profile拷贝到两个Slave节点:
#scp /etc/profile root@DEV-SH-MAP-02:/etc
#scp /etc/profile root@DEV-SH-MAP-03:/etc
分别在两个Salve节点上执行# source /etc/profile使其立即生效
六、Spark配置
以下操作均在Master节点,配置完后,使用scp命令,将配置文件拷贝到两个Worker节点即可。
切换到/usr/spark-2.1.0/conf/目录下,修改如下文件:
6.1 spark-env.sh
将spark-env.sh.template重命名为spark-env.sh
#mv spark-env.sh.template spark-env.sh
使用vi编辑器,打开spark-env.sh,在文件最后,添加如下内容:
export JAVA_HOME=/usr/jdk1.8.0_121
export SCALA_HOME=/usr/scala-2.12.1
export SPARK_MASTER_IP=10.10.0.1
export SPARK_WORKER_MEMORY=1g
export HADOOP_CONF_DIR=/usr/hadoop-2.7.3/etc/hadoop
6.2 slaves
将slaves.template重命名为slaves
#mv slaves.template slaves
使用vi编辑器,打开slaves,在文件最后,添加如下内容:
DEV-SH-MAP-01
DEV-SH-MAP-02
DEV-SH-MAP-03
6.3 拷贝配置文件到两个Worker节点
在Master节点,执行如下命令:
# scp -r /usr/spark-2.1.0/conf/ root@DEV-SH-MAP-02:/usr/spark-2.1.0/
# scp -r /usr/spark-2.1.0/conf/ root@DEV-SH-MAP-03:/usr/spark-2.1.0/
七、Spark使用
7.1 启动Hadoop集群
参见博文:http://www.cnblogs.com/liugh/p/6624872.html
7.2 启动Master节点
Master节点上,执行如下命令:
#start-master.sh
使用jps命令,查看Java进程:
34225 SecondaryNameNode
33922 NameNode49702 Jps
34632 NodeManager
34523 ResourceManager
34028 DataNode
36415 Master
7.3 启动Worker节点
Master节点上,执行如下命令:
#start-slaves.sh
使用jps命令,查看Java进程:

34225 SecondaryNameNode
33922 NameNode
36562 Worker
49702 Jps
34632 NodeManager
34523 ResourceManager
34028 DataNode
36415 Master
7.4 通过浏览器查看Spark信息
浏览器中,输入http://10.10.0.1:8080
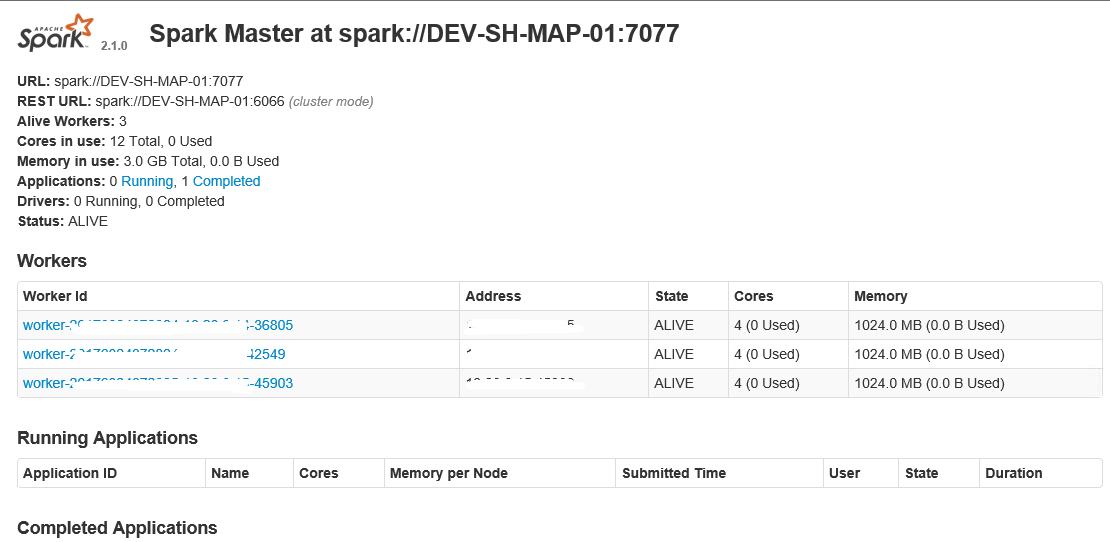
7.5 停止Master及Workder节点
#stop-master.sh
#stop-slaves.sh
hadoop2.7.3+spark2.1.0+scala2.12.1环境搭建(4)SPARK 安装的更多相关文章
- hadoop2.7.3+spark2.1.0+scala2.12.1环境搭建(3)http://www.cnblogs.com/liugh/p/6624491.html
一.文件准备 scala-2.12.1.tgz 下载地址: http://www.scala-lang.org/download/2.12.1.html 二.工具准备 2.1 Xshell 2.2 X ...
- hadoop2.7.3+spark2.1.0+scala2.12.1环境搭建(2)安装hadoop
一.依赖安装 安装JDK 二.文件准备 hadoop-2.7.3.tar.gz 2.2 下载地址 http://hadoop.apache.org/releases.html 三.工具准备 3.1 X ...
- hadoop2.7.3+spark2.1.0+scala2.12.1环境搭建(1)安装jdk
一.文件准备 下载jdk-8u131-linux-x64.tar.gz 二.工具准备 2.1 Xshell 2.2 Xftp 三.操作步骤 3.1 解压文件: $ tar zxvf jdk-8u131 ...
- Hadoop2.7.3+Spark2.1.0完全分布式集群搭建过程
1.选取三台服务器(CentOS系统64位) 114.55.246.88 主节点 114.55.246.77 从节点 114.55.246.93 从节点 之后的操作如果是用普通用户操作的话也必须知道r ...
- Hadoop2.7.3+Spark2.1.0 完全分布式环境 搭建全过程
一.修改hosts文件 在主节点,就是第一台主机的命令行下; vim /etc/hosts 我的是三台云主机: 在原文件的基础上加上; ip1 master worker0 namenode ip2 ...
- Apache Spark1.1.0部署与开发环境搭建
Spark是Apache公司推出的一种基于Hadoop Distributed File System(HDFS)的并行计算架构.与MapReduce不同,Spark并不局限于编写map和reduce ...
- Windows Server 2003 IIS6.0+PHP5(FastCGI)+MySQL5环境搭建教程
准备篇 一.环境说明: 操作系统:Windows Server 2003 SP2 32位 PHP版本:php 5.3.14(我用的php 5.3.10安装版) MySQL版本:MySQL5.5.25 ...
- Cocos2dx-3.0版本 从开发环境搭建(Win32)到项目移植Android平台过程详解
作为重量级的跨平台开发的游戏引擎,Cocos2d-x在现今的手游开发领域占有重要地位.那么问题来了,作为Cocos2dx的学习者,它的可移植特性我们就需要掌握,要不然总觉得少一门技能.然而这个时候各种 ...
- SDL2.0的VS开发环境搭建
SDL2.0的VS开发环境搭建 [前言] 我是用的是VS2012,VS的版本应该大致一样. [开发环境搭建] >>>SDL2.0开发环境配置:1.从www.libsdl.org 下载 ...
随机推荐
- 【Unity3D与23种设计模式】桥接模式(Bridge)
GoF定义: "将抽象与实现分离,使二者可以独立的变化" 游戏中,经常有这么一种情况 基类角色类(ICharacter),下面有子类士兵类(ISoldier).敌军类(IEnemy ...
- mySQL的安装和基础使用及语法教程
mySQL的安装和基础使用及语法指南 一.MySQL的安装.配置及卸载 1.安装 2.配置 3.mySQL5.1的完全卸载 4.MYSQL环境变量的配置 二.MySQL控制台doc窗口的操作命令 1. ...
- 数据段、代码段、堆栈段、BSS段的区别
进程(执行的程序)会占用一定数量的内存,它或是用来存放从磁盘载入的程序代码,或是存放取自用户输入的数据等等.不过进程对这些内存的管理方式因内存用 途 不一而不尽相同,有些内存是事先静态分配和统一回收的 ...
- 二分查找(binary search)java实现及时间复杂度
概述 在一个已排序的数组seq中,使用二分查找v,假如这个数组的范围是[low...high],我们要的v就在这个范围里.查找的方法是拿low到high的正中间的值,我们假设是m,来跟v相比,如果m& ...
- poj-1028 -网页导航
Description Standard web browsers contain features to move backward and forward among the pages rece ...
- 用Canvas写一个简单的游戏--别踩白块儿
第一次写博客也不知怎么写,反正就按照我自己的想法来吧!怎么说呢?还是不要扯那些多余的话了,直接上正题吧! 第一次用canvas写游戏,所以挑个简单实现点的来干:别踩白块儿,其他那些怎么操作的那些就不用 ...
- Algorithm --> 字符串中最长不重合子串长度
例子 "abmadsefadd" 最长长度为7 "avoaid" 最长长度为3 思路 空间换时间hashTable,起始位置设为beg.初 ...
- IDEA2017注册码
1. 到网站 http://idea.lanyus.com/ 获取注册码. 2.填入下面的license server: http://intellij.mandroid.cn/ http://ide ...
- Linux下进程间通信的六种机制详解
linux下进程间通信的几种主要手段: 1.管道(Pipe)及有名管道(named pipe):管道可用于具有亲缘关系进程间的通信,有名管道克服了管道没有名字的限制,因此,除具有管道所具 ...
- 在深度linux下安装pip3与jupyter
前言 以下安装说明基于已经正确安装python3 文件下载 https://pypi.python.org/pypi/pip 下载pip-9.0.1.tar.gz (md5, pgp)文件 安装准备工 ...