Python2.x的编码问题
1. 计算机编码历史
ASCII
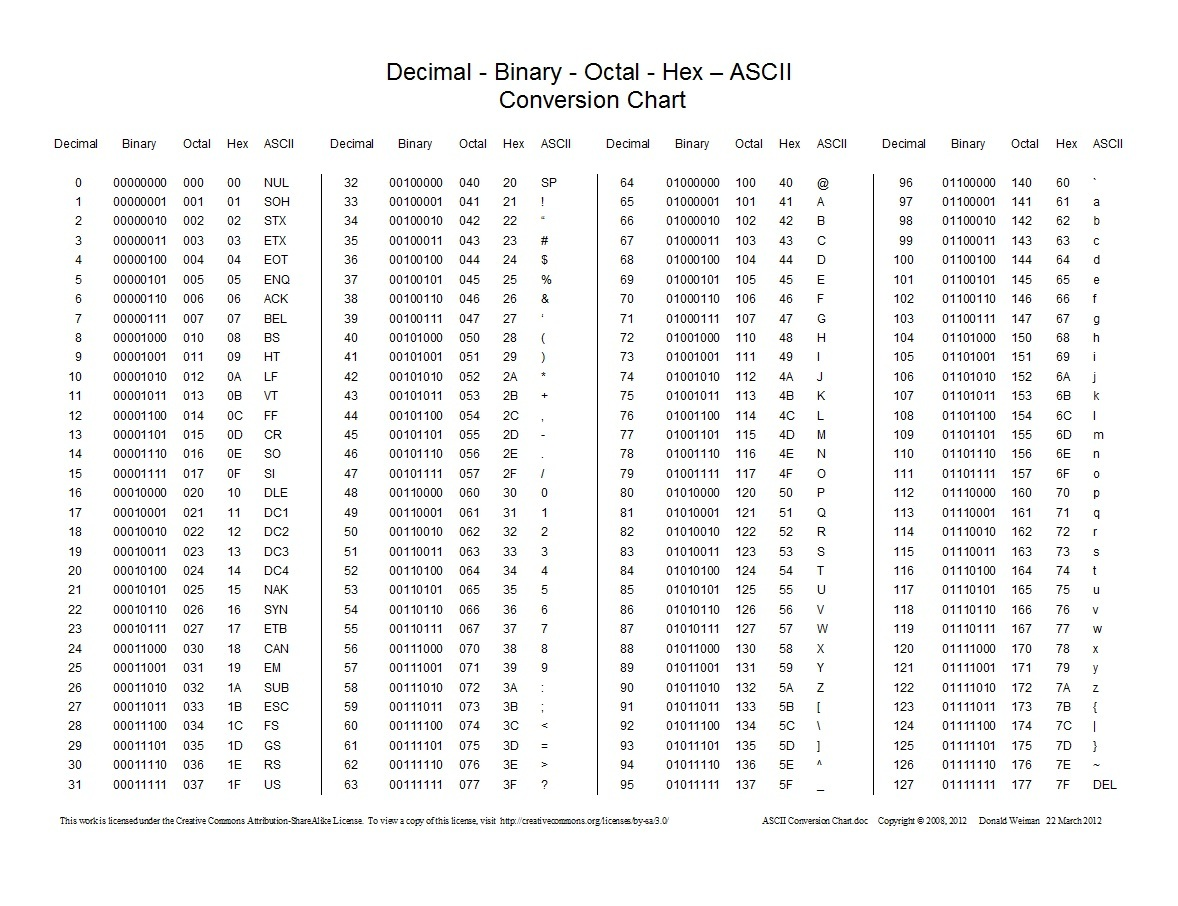
Python的默认编码,其是一种单字节的编码。刚开始计算机世界里只有英文,而单字节可以表示256个不同的字符。最开始ASCII只定义了128个字符编码,包括96个文字和32个控制符号,因此ASCII只使用了一个字节的后7位,最高位都为0。每个字符和ASCII码的对应关系可以查看下图:
EASCII
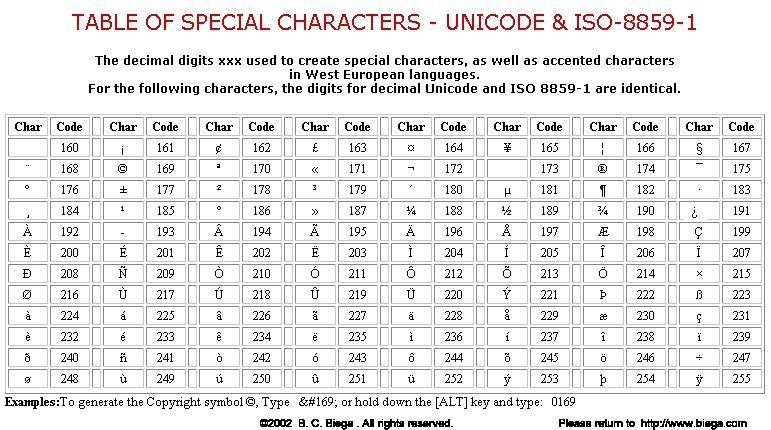
随着计算机的发展,发现有很多西欧的字符中原ASCII中并没有涵盖,于是出现了可扩展的ASCII叫做EASCII,包含了表格符号、计算符号、希腊字母和特殊的拉丁符号,如下图(CP437标准):

除却CP437标准外,还有ISO/8859-1(Latin-1)标准,它继承了CP437的128-159之间的字符,所以它是从160开始定义的,如下:
GBK
后来,为了兼容中文,我们自己弄了一套编码叫做GB2312,又叫做GB0。其一共收录了6763个汉字,同时还兼容ASCII。虽然说GB2312已经涵盖了中国大陆99.75%的汉字使用频率,但是仍未达到100%。于是在此基础上创建了一种叫做GBK的编码,其不仅收录了27484个汉字,同时还收录了藏文、蒙文、维吾尔文等主要的少数民族文字。而且它也是兼容ASCII编码的。在GBK中,英文字符用一个字节表示,汉字用两个字节表示。
Unicode
随着计算机的普及,别的国家的文字诸如日文、韩文等也需要制定一套编码规范。于是统一联盟国际组织提出了Unicode编码,简称为UCS。Unicode有两种格式:UCS-2和UCS-4。UCS-2就是用两个字节编码,一共16个比特位,这样理论上可以表示65536个字符,不过这还远远不够。所以UCS-4则是用4个字节来表示(最高位为0,所以其实是31位)。
值得注意的是,UCS-2和UCS-4只是规定了代码点和文字之间的关系,即所有文字都有一个代码点。但是并没有规定代码点如何在计算机中存储。规定存储方式的称为UTF,其中应用较多的是UTF-16和UTF-8。
UTF-16
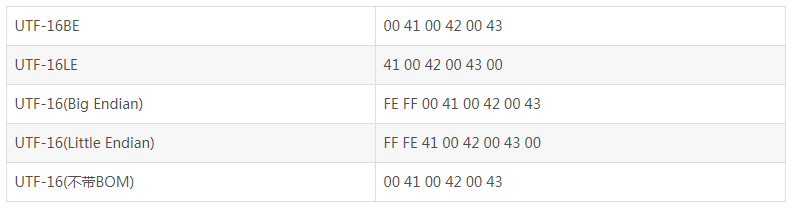
不难猜到,UTF-16是完全对应于UCS-2的,即把UCS-2规定代码点通过大端模式或者小端模式保存下来。UTF-16包括三种:UTF-16,UTF-16BE,UTF-16LE。
区分是UTF-16BE还是UTF-16LE,需要在文件开头以名为BOM的字符来表明是大端存储还是小端存储,FEFF为大端,FFFE为小端,如下(ABC的存储):
同理,UTF-32则是对应UCS-4,不再赘述。
UTF-8
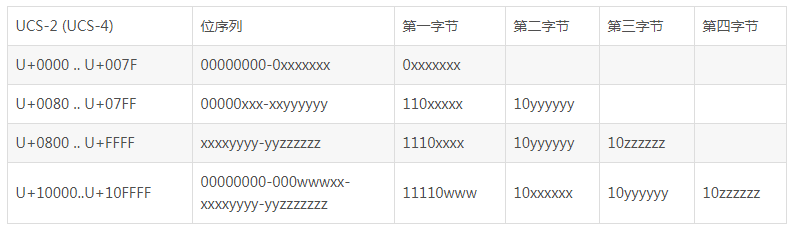
UTF-16和UTF-32的一个缺点就是它们固定使用两个或四个字节,这样在表示纯ASCII文件时会有很多00字节,造成浪费。于是UTF-8应运而生。
UTF-8用1-4个字节来表示代码点,如下:
Unicode相对来说只是一个字符集,而UTF-8和UTF-16则是编码规则。
Python字符编码
前面也提到过,Python的默认编码为ASCII码。在Python2.x中,有两种字符串,分别是str和unicode。比如,对一个汉字“好”,用str表示,则是对应的utf-8编码(假设是utf-8)的"\xe5\xa5\xbd",而用unicode来表示,则是u"\u597d"。str类型的字符具体编码,跟环境有关。
在Python中,unicode常常作为中介,字符要先解码成unicode,才能再编码成字符。有两个和编码息息相关的函数:decode()和encode()。它们的关系如下:

2. 文件头编码声明的作用
对于文件头部# coding: utf-8,一般来说,有三个作用:
- 声明代码中会存在中文
- 在高级的IDE中,会将文件的编码格式保存为这行注释指定的编码格式
- 当Python中出现unicode字符串时,用注释指定的编码格式进行解码
前面两条都很好理解,我们来看最后一个作用,如下(文件编码为utf-8):
# -*- coding: utf-8 -*-
str = u'好好'
# 这里其实Python内部进行了如下操作:
# 先是得到“好好”的文件编码(utf-8)形式,即'\xe5\xa5\xbd\xe5\xa5\xbd'
# 接着由于是unicode字符串,则用注释中格式(utf-8)进行解码为unicode,即u'\u597d\u597d'
print repr(str) #将得到u'\u597d\u597d'
print str.encode('utf-8') #将得到“好好”
print str.encode('gbk') #将得到乱码,因为以gbk编码后得到的是'\xba\xc3\xba\xc3',但是print将会根据环境编码(utf-8)来展示,则是乱码
# -*- coding: gbk -*-
str = u'好好'
# 同理,先得到“好好”的文件编码(utf-8)形式(utf-8中汉字占3字节,共6个字节),然后用gbk(注意)来将其解码成unicode,由于gbk中两个字节为一个汉字,所以得到的unicode为u'\u6fc2\u85c9\u30bd'
print str.encode('utf-8') #得到“濂藉ソ”
print str.encode('gbk') #得到“好好”,因为经过gbk编码后得到'\xe5\xa5\xbd\xe5\xa5\xbd',print将其以环境编码(utf-8)展示
str1 = '好' #其实str1以'\xe5\xa5\xbd'(即文件编码)的形式存储,但是Python会用注释中的编码形式对其进行检查,发现这3个字节在gbk中不存在,则会报错
3. setdefaultencoding的作用
前面说到,Python的默认编码为ASCII,通过这个函数这可以修改默认编码,一般形式为:
import sys
reload(sys)
sys.setdefaultencoding('编码格式') #默认是ASCII
设置这个编码格式主要应用是在以下场景中:
# -*- coding: utf-8 -*-
str = '好好'
print repr(str.encode('utf-8'))
# 其实这里Python是这样执行:str.decode('ascii').encode('utf-8')
# 先解码成unicode,由于ascii不支持中文,故会报错
print repr(str.decode('utf-8').encode('gbk'))
# 先用utf-8解码为unicode,得到u'\u597d\u597d'
# 然后用gbk格式编码,得到'\xba\xc3\xba\xc3'
# print以utf-8(环境编码)展示,得到乱码
所以说,默认编码的优先顺序为:decode显式设置 > setdefaultencoding设置 > ascii编码
4. 建议
为了减少Python编程中的编码出错,我总结了一下几个建议:
注意系统环境编码,尽量让文件编码和系统环境编码一致;
注释的编码格式最好和文件编码格式一样;
decode采取的编码和encode采取的编码需一致,不然一般会出错。
Python2.x的编码问题的更多相关文章
- Python2.7字符编码详解
目录 Python2.7字符编码详解 声明 一. 字符编码基础 1.1 抽象字符清单(ACR) 1.2 已编码字符集(CCS) 1.3 字符编码格式(CEF) 1.3.1 ASCII(初创) 1.3. ...
- 一篇文章助你理解Python2中字符串编码问题
前几天给大家介绍了unicode编码和utf-8编码的理论知识,没来得及上车的小伙伴们可以戳这篇文章:浅谈unicode编码和utf-8编码的关系.下面在Python2环境中进行代码演示,分别Wind ...
- python2和python3编码问题
欢迎加入python学习交流群 667279387 一.什么是编解码 1.什么是unicode 2.编码方式 二.python中的编解码 1.python2 (1).encode() 和 .decod ...
- 字符编码、python2和python3编码的区别
目录 字符编码 文本编辑器存储信息的过程 python解释器解释python代码的流程 python解释器与文本编辑器的异同 不同编码格式存入与读取数据的过程 乱码的分析 python2和python ...
- 在python2中的编码
在python2中的编码 #_author:star#date:2019/10/29'''字符编码:ASCII:只能存英文和拉丁字符,gb2312:只能6700中文,1980年gbk1.0:存了200 ...
- 简介python2.x的编码
python2.x的中文编码真是令人头痛,简单写下自己的一点python编码转换的体会. windows平台用的默认编码格式为gbk >>> s = raw_input() #在wi ...
- python2.x 默认编码问题
python2.x中处理中文,是一件头疼的事情.网上写这方面的文章,测次不齐,而且都会有点错误,所以在这里打算自己总结一篇文章. 我也会在以后学习中,不断的修改此篇博客. 这里假设读者已有与编码相关的 ...
- 快速理解python2中的编码问题
# -*- coding:utf-8 -*- ''' python2 中的字符编码有str和unicode(字符串类型的名字) str类型字符串类型在内存中存储的是bytes数据 Unicode类型字 ...
- 一篇文章搞懂python2、3编码
说在前边: 编码问题一直困扰着每一个程序员的编程之路,如果不将它彻底搞清楚,那么你的的这条路一定会走的格外艰辛,尤其是针对使用python的程序员来说,这一问题更加显著, 因为python有两个版本, ...
随机推荐
- PyTorch官方中文文档:PyTorch中文文档
PyTorch中文文档 PyTorch是使用GPU和CPU优化的深度学习张量库. 说明 自动求导机制 CUDA语义 扩展PyTorch 多进程最佳实践 序列化语义 Package参考 torch to ...
- spring整合mybatis(hibernate)配置
一.Spring整合配置Mybatis spring整合mybatis可以不需要mybatis-config.xml配置文件,直接通过spring配置文件一步到位.一般需要具备如下几个基本配置. 1. ...
- 基于 HTML5 WebGL 的 3D 机房
前言 用 WebGL 渲染的 3D 机房现在也不是什么新鲜事儿了,这篇文章的主要目的是说明一下,3D 机房中的 eye 和 center 的问题,刚好在项目中用上了,好生思考了一番,最终觉得这个例子最 ...
- C++学习-8
1.注意:函数指针前面*,&都是一样的没啥实际意义,除了把实例化函数块的时候,需要指针或者引用修饰 cout << typeid(my1.show).name() <& ...
- 原生js获取left值和top值
在用js做动态效果时,通常需要获取元素绝对定位中的left和top属性值.比如做一个碰撞广告,就要不停的获取元素的top和left属性值. 需要注意的事:取值的元素必须要设置position:abso ...
- 【Unity3D与23种设计模式】外观模式(Facade)
GoF中定义: "为子系统定义一组统一的接口,这个高级的接口会让子系统更容易被使用" 其实这个模式虽然很少听过 但我们在敲代码的时候却是经常使用 比如: 在游戏初始化时 要初始化很 ...
- PPT分享 | 怎么在区块链上保护隐私?
艾伯特AI人工智能(公众号:aibbtcom)按: (编者按:在12月3日的亚太区以太坊社区培训和交流Meetup深圳站上,Vitalik作了<怎么在区块链上保护隐私>的演讲,谈到了区块链 ...
- Linux-CentOS7下安装mysql5.6常见问题解决!
第一次写博客,写的不好请大家多见谅!有遇到问题可以评论到下方,我会抽空帮大家解决!! 下载MySQL-5.6.tar安装包(包含server,client等) 首先用root用户将MySQL-5.6. ...
- 初探云服务器ECS(Linux系统)
PS: 购买的阿里云服务器(ECS,Linux系统),使用的弹性公网IP(EIP). 一.使用Xshell链接ECS 1.将公网IP填入主机即可 2.用户名一般为root,密码是自己设置的,填入即可. ...
- python作业03-文件操作&函数
一.文件处理相关 1.编码问题 (1)请说明python2 与python3中的默认编码是什么?答:Python2默认的字符编码是ASCII,默认的文件编码也是ASCII :python3默认的字符编 ...