[区块链] 密码学——Merkle 树
在计算机领域,Merkle树大多用来进行完整性验证处理。在处理完整性验证的应用场景中,特别是在分布式环境下进行这样的验证时,Merkle树会大大减少数据的传输量以及计算的复杂度。
Merkle哈希树是一类基于哈希值的二叉树或多叉树,其叶子节点上的值通常为数据块的哈希值,而非叶子节点上的值是将该节点的所有子节点的组合结果的哈希值。
如下图所示为一个Merkle哈希树,节点A的值必须通过节点C、D上的值计算而得到。叶子节点C、D分别存储数据块001和002的哈希值,而非叶子节点A存储的是其子节点C、D的组合的哈希值,这类非叶子节点的哈希值被称作路径哈希值,而叶子节点的哈希值是实际数据的哈希值。
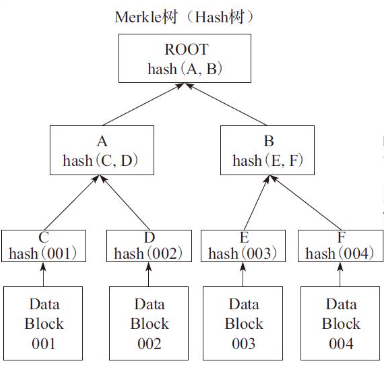
当数据从A端传到B端时,为了检验数据的完整性,只需要验证A、B端上所构造的Merkle树的根节点是否一致即可。若一致,表示数据在传输过程中没有发生改变。若不一致,说明数据在传输过程中被修改。而且通过Merkle树很容易定位找到被篡改的节点。定位的时间复杂度为O(log(n))。
比特币的轻量级节点所采用的SPV验证就是利用Merkle树这一优点。
区块链中的Merkle树是二叉树,用于存储交易信息。每个交易两两配对,构成Merkle树的叶子节点,进而生成整个Merkle树。Merkle树使得用户可以通过从区块头得到的Merkle树根和别的用户所提供的中间哈希值列表去验证某个交易是否包含在区块中。提供中间哈希值的用户并不需要是可信的,因为伪造区块头的代价很高,而中间哈希值如果伪造的话会导致验证失败。
通常,加密的hash方法像SHA-2和MD5用来做Hash。但如果仅仅防止数据不是蓄意的损坏或篡改,可以改用一些安全性低但效率高的校验和算法,如CRC。
Second Preimage Attack: Merkle tree的树根并不表示树的深度,这可能会导致second-preimage attack,即攻击者创建一个具有相同Merkle树根的虚假文档。一个简单的解决方法在Certificate Transparency中定义:当计算叶节点的hash时,在hash数据前加0x00。当计算内部节点是,在前面加0x01。另外一些实现限制hash tree的根,通过在hash值前面加深度前缀。因此,前缀每一步会减少,只有当到达叶子时前缀依然为正,提取的hash链才被定义为有效。
Merkle tree操作:
1.创建Merckle Tree
加入最底层有9个数据块。
step1:(红色线)对数据块做hash运算,Node0i = hash(Data0i), i=1,2,…,9
step2: (橙色线)相邻两个hash块串联,然后做hash运算,Node1((i+1)/2) = hash(Node0i+Node0(i+1)), i=1,3,5,7;对于i=9, Node1((i+1)/2) = hash(Node0i)
step3: (黄色线)重复step2
step4:(绿色线)重复step2
step5:(蓝色线)重复step2,生成Merkle Tree Root
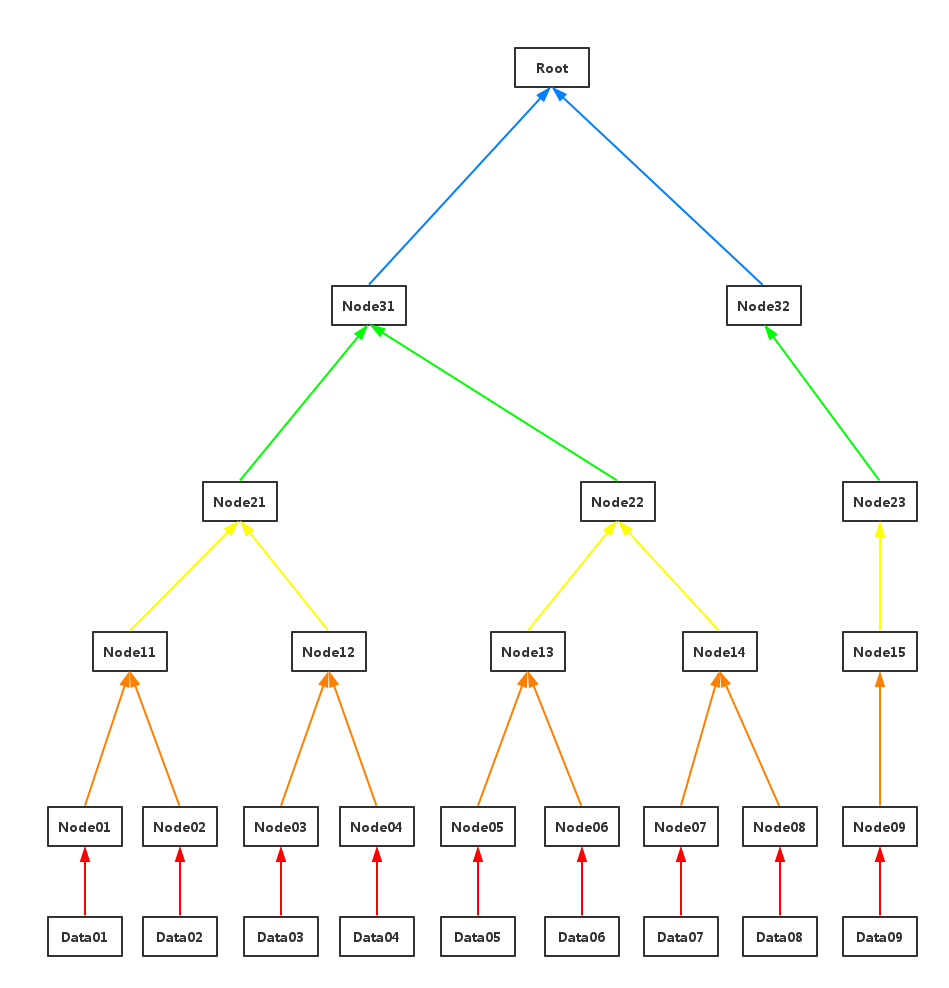
易得,创建Merkle Tree是O(n)复杂度(这里指O(n)次hash运算),n是数据块的大小。得到Merkle Tree的树高是log(n)+1。
2.检索数据块
为了更好理解,我们假设有A和B两台机器,A需要与B相同目录下有8个文件,文件分别是f1 f2 f3 ....f8。这个时候我们就可以通过Merkle Tree来进行快速比较。假设我们在文件创建的时候每个机器都构建了一个Merkle Tree。具体如下图:

从上图可得知,叶子节点node7的value = hash(f1),是f1文件的HASH;而其父亲节点node3的value = hash(v7, v8),也就是其子节点node7 node8的值得HASH。就是这样表示一个层级运算关系。root节点的value其实是所有叶子节点的value的唯一特征。
假如A上的文件5与B上的不一样。我们怎么通过两个机器的merkle treee信息找到不相同的文件? 这个比较检索过程如下:
Step1. 首先比较v0是否相同,如果不同,检索其孩子node1和node2.
Step2. v1 相同,v2不同。检索node2的孩子node5 node6;
Step3. v5不同,v6相同,检索比较node5的孩子node 11 和node 12
Step4. v11不同,v12相同。node 11为叶子节点,获取其目录信息。
Step5. 检索比较完毕。
以上过程的理论复杂度是Log(N)。
3. 更新,插入和删除
虽然网上有很多关于Merkle Tree的资料,但大部分没有涉及Merkle Tree的更新、插入和删除操作,讨论Merkle Tree的检索和遍历的比较多。显然,一种树结构的操作肯定不仅包括查找,也包括更新、插入和删除的啊。后来查到风之舞555的总结的文章,少有感悟,下面引用风之舞555对该部分讲述:
对于Merkle Tree数据块的更新操作其实是很简单的,更新完数据块,然后接着更新其到树根路径上的Hash值就可以了,这样不会改变Merkle Tree的结构。但是,插入和删除操作肯定会改变Merkle Tree的结构,如下图,一种插入操作是这样的:

插入数据块0后(考虑数据块的位置),Merkle Tree的结构是这样的:

而有的同学在考虑一种插入的算法,满足下面条件:
- re-hashing操作的次数控制在log(n)以内
- 数据块的校验在log(n)+1以内
- 除非原始树的n是偶数,插入数据后的树没有孤儿,并且如果有孤儿,那么孤儿是最后一个数据块
- 数据块的顺序保持一致
- 插入后的Merkle Tree保持平衡
然后上面的插入结果就会变成这样:

所以,Merkle Tree的插入和删除操作其实是一个工程上的问题,不同问题会有不同的插入方法。如果要确保树是平衡的或者是树高是log(n)的,可以用任何的标准的平衡二叉树的模式,如AVL树,红黑树,伸展树,2-3树等。这些平衡二叉树的更新模式可以在O(lgn)时间内完成插入操作,并且能保证树高是O(lgn)的。那么很容易可以看出更新所有的Merkle Hash可以在O((lgn)2)时间内完成(对于每个节点如要更新从它到树根O(lgn)个节点,而为了满足树高的要求需要更新O(lgn)个节点)。如果仔细分析的话,更新所有的hash实际上可以在O(lgn)时间内完成,因为要改变的所有节点都是相关联的,即他们要不是都在从某个叶节点到树根的一条路径上,或者这种情况相近。
实际上Merkle Tree的结构(是否平衡,树高限制多少)在大多数应用中并不重要,而且保持数据块的顺序也在大多数应用中也不需要。因此,可以根据具体应用的情况,设计自己的插入和删除操作。一个通用的Merkle Tree插入删除操作是没有意义的。
拓展知识:
Hash List 与 Merkle tree 有什么异同?
娓娓道来~~~~~~~
网络传输数据的时候,A收到B的传过来的文件,需要确认收到的文件有没有损坏。如何解决?
:有一种方法是B在传文件之前先把文件的hash结果给A,A收到文件再计算一次哈希然后和收到的哈希比较就知道文件有无损坏。
但是当文件很大的时候,往往需要把文件拆分很多的数据块各自传输,这个时候就需要知道每个数据块的哈希值。怎么办呢?
:这种情况,可以在下载数据之前先下载一份哈希列表(hash list),这个列表每一项对应一个数据块的哈希值。对这个hash list拼接后可以计算一个根hash。实际应用中,我们只要确保从一个可信的渠道获取正确的根hash,就可以确保下载正确的文件。
但是基于hash list的方案这样一个问题: 数据块很多的时候,往往遍历所有数据块的Hash List代价比较大。
有没有一种方法可以通过部分Hash就能校验整个文件的完整性呢?
:答案是肯定的!Merkle Tree 就能做到!
Merkle Tree和Hash List的主要区别是,可以直接下载并立即验证Merkle Tree的一个分支。因为可以将文件切分成小的数据块,这样如果有一块数据损坏,仅仅重新下载这个数据块就行了。如果文件非常大,那么Merkle tree和Hash list都很大,但是Merkle tree可以一次下载一个分支,然后立即验证这个分支,如果分支验证通过,就可以下载数据了。而Hash list只有下载整个hash list才能验证。
【时间仓促,如有错误,欢迎指正! || 欢迎留下您的评语! 大家一起探讨、学习区块链!】
【转载请注明出处!http://www.cnblogs.com/X-knight/】
REFERENCE
1.Merkle Tree 学习 http://www.cnblogs.com/fengzhiwu/p/5524324.html
2. Merkle Tree 增删数据http://crypto.stackexchange.com/questions/22669/merkle-hash-tree-updates
3.Merkle Tree、Hash List https://blog.csdn.net/pony_maggie/article/details/74538902
[区块链] 密码学——Merkle 树的更多相关文章
- [区块链] 密码学中Hash算法(基础)
在介绍Hash算法之前,先给大家来个数据结构中对hash表(散列表)的简单解释,然后我再逐步深入,讲解一下hash算法. 一.Hash原理——基础篇 1.1 概念 哈希表就是一种以 键-值(key-i ...
- [区块链] 密码学——椭圆曲线密码算法(ECC)
今天在学椭圆曲线密码(Elliptic Curve Cryptography,ECC)算法,自己手里缺少介绍该算法的专业书籍,故在网上查了很多博文与书籍,但是大多数博客写的真的是...你懂的...真不 ...
- cpp 区块链模拟示例(七) 补充 Merkle树
Merkle 树 完整的比特币数据库(也就是区块链)需要超过 140 Gb 的磁盘空间.因为比特币的去中心化特性,网络中的每个节点必须是独立,自给自足的,也就是每个节点必须存储一个区块链的完整副本.随 ...
- 区块链中的密码学(四)- Merkle树和SPV节点
什么是Merkle Tree? Merkle Tree 的命名来自于美国密码学家Ralph C. Merkle ,关于他的个人资料:传送门https://en.wikipedia.org/wiki/R ...
- 区块链~Merkle Tree(默克尔树)算法解析~转载
转载~Merkle Tree(默克尔树)算法解析 /*最近在看Ethereum,其中一个重要的概念是Merkle Tree,以前从来没有听说过,所以查了些资料,学习了Merkle Tree的知识,因为 ...
- 区块链 - 默克尔树(Merkle Tree)
章节 区块链 – 介绍 区块链 – 发展历史 区块链 – 比特币 区块链 – 应用发展阶段 区块链 – 非对称加密 区块链 – 哈希(Hash) 区块链 – 挖矿 区块链 – 链接区块 区块链 – 工 ...
- 区块链学习1:Merkle树(默克尔树)和Merkle根
☞ ░ 前往老猿Python博文目录 ░ 一.简介 默克尔树(Merkle tree,MT)又翻译为梅克尔树,是一种哈希二叉树,树的根就是Merkle根. 关于Merkle树老猿推荐大家阅读<M ...
- 区块链入门到实战(12)之区块链 – 默克尔树(Merkle Tree)
目的:解决由于区块链过长,导致节点硬盘存不下的问题. 方法:只需保留交易的哈希值. 区块链作为分布式账本,原则上网络中的每个节点都应包含整个区块链中全部区块,随着区块链越来越长,节点的硬盘有可能放不下 ...
- 比特币区块结构Merkle树及简单支付验证分析
在比特币网络中,不是每个节点都有能力储存完整的区块链数据,受限于存储空间的的限制,很多节点是以SPV(Simplified Payment Verification简单支付验证)钱包接入比特币网络,通 ...
随机推荐
- Scala编程入门---数组操作之数组转换
使用yield和函数式编程转换数组 //对Array进行转换,获取的还是Aarry val a = Array(1,2,3,4,5) val a2 = for(ele <- a) yield e ...
- 基于Python的数据分析(2):字符串编码
在上一篇文章<基于Python的数据分析(1):配置安装环境>中的第四个步骤中我们在python的启动步骤中强制要求加载sitecustomize.py文件并设置其默认编码为"u ...
- ES入门笔一
ES6一共有6种声明变量的方法 --ES5只有var 和 function --ES6新增了let.const.import和class四种 ES6新增let和const,用来声明变量,是对var的扩 ...
- Cython入门Demo(Linux)
众所周知,Python语言是非常简单易用的,但是python程序在运行速度上还是有一些缺陷.于是,Cython就应运而生了,Cython作为Python的C扩展,保留了Python的语法特点,集成C语 ...
- Servlet知识点总结
一, ServletAPI中有4个Java包: 1.javax.servlet:其中包含定义Servlet和Servlet容器之间契约的类和接口 2.javax.servlet.http:其中包含定义 ...
- 《与C语言相恋》
第一章 <与C语言相恋> 目录: 1.1 C语言的诞生 1.2 相恋C语言的理由 1.3 相恋C语言的7个步骤 1.4 目标代码文件,可执行文件和库 1.5 本章小结 C语言的诞生 197 ...
- 接口调用(发送http请求)
// 向对应的url地址发送http请求, 并获取响应的json字符串 public String getHttpResponse(String url) { // result用 ...
- PAT1013: Battle Over Cities
1013. Battle Over Cities (25) 时间限制 400 ms 内存限制 65536 kB 代码长度限制 16000 B 判题程序 Standard 作者 CHEN, Yue It ...
- Spring Cloud Zuul 限流详解(附源码)(转)
在高并发的应用中,限流往往是一个绕不开的话题.本文详细探讨在Spring Cloud中如何实现限流. 在 Zuul 上实现限流是个不错的选择,只需要编写一个过滤器就可以了,关键在于如何实现限流的算法. ...
- MyBatis系列目录--5. MyBatis一级缓存和二级缓存(redis实现)
转载请注明出处哈:http://carlosfu.iteye.com/blog/2238662 0. 相关知识: 查询缓存:绝大数系统主要是读多写少. 缓存作用:减轻数据库压力,提供访问速度. 1. ...