Storm 对 0.10.x 版 Kafka之commit offsets
由于 0.10.x 版 Kafka 与 0.8.x 版有很大的变化,这种变化对下游 Storm 有非常大的影响,0.10.x 版的 Kafka 不但增加了权限管理的功能,而且还将 simple 和 high consumer 的 offsets 进行统一管理,也就意味着在 0.8.x 中 Storm 需要去负责管理 offsets,而在 0.10.x 中,Storm 不需要关心 consumer 的 offsets 的问题,这对 KafkaSpout 的设计有很大的影响,本文就是对 Storm 对 0.10.x 版 Kafka 支持的实现部分的解析。
0.10.x 版 KafkaSpout 的实现
社区对新版 Kafka 的支持,总体分为两种情况:
- 一种是选择自动 commit 机制;
- 另一种是非自动 commit,就是将 commit 的权利交与 Storm 来控制。
下面分别对这两种情况进行分析。
Kafka Consumer 的一些配置会对 Storm 的性能很大影响,下面的三个参数的设置对其性能的影响最大(默认值是根据MICROBENCHMARKING APACHE STORM 1.0 PERFORMANCE测试得到):
fetch.min.bytes:默认值 1;fetch.max.wait.ms:默认值 500(ms);Kafka Consumer instance poll timeout, 它可以在通过 KafkaSpoutConfig 的方法 setPollTimeoutMs 来配置,默认值是 200ms;
自动 commit 模式
自动 commit 模式就是 commit 的时机由 Consumer 来控制,本质上是异步 commit,当定时达到时,就进行 commit。而 Storm 端并没有进行任何记录,也就是这部分的容错完全由 Consumer 端来控制,而 Consumer 并不会关心数据的处理成功与否,只关心数据是否 commit,如果未 commit,就会重新发送数据,那么就有可能导致下面这个后果:
造成那些已经 commit、但 Storm 端处理失败的数据丢失
丢失的原因
一些数据发送到 Spout 之后,恰好 commit 的定时到达,进行了 commit,但是这中间有某条或者几条数据处理失败,这就是说,这几条处理失败的数据已经进行 commit 了,Kafka 端也就不会重新进行发送。
可能出现的这种后果也确定了自动 commit 模式不能满足我们的需求,为了保证数据不丢,需要数据在 Storm 中 ack 之后才能被 commit,因此,commit 还是应该由 Storm 端来进行控制,才能保证数据被正确处理。
非自动 commit 模式
当选用非自动的 commit 机制(实际上就是使用 Consumer 的同步 commit 机制)时,需要手动去设置 commit 的参数,有以下两项需要设置:
offset.commit.period.ms:设置 spout 多久向 Kafka commit一次,在 KafkaSpoutConfig 的 setOffsetCommitPeriodMs 中配置;max.uncommitted.offsets:控制在下一次拉取数据之前最多可以有多少数据在等待 commit,在 KafkaSpoutConfig 的 setMaxUncommittedOffsets 中配置;
spout 的处理过程
关于 Kafka 的几个 offset 的概念,可以参考offset的一些相关概念
KafkaSpout 的处理过程主要是在 nextTuple() 方法,其处理过程如下:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
|
public void nextTuple() {
if (initialized) {
if (commit()) {// Step1 非自动 commit,并且定时达到
commitOffsetsForAckedTuples();// 对所有已经 ack 的 msgs 进行 commit
}
if (poll()) {//Step2 拉取的数据都已经发送,并且未 commit 的消息数小于设置的最大 uncommit 数
setWaitingToEmit(pollKafkaBroker());
//将拉取的所有 record 都放到 waitingToEmit 集合中,可能会重复拉取数据(由于一些 msg 需要重试,通过修改 Last Committed Offset 的值来实现的)
}
if (waitingToEmit()) {//Step3 waitingToEmit 中还有数据
emit();//发送数据,但会跳过已经 ack 或者已经发送的消息
}
} else {
LOG.debug("Spout not initialized. Not sending tuples until initialization completes");
}
}
|
上面主要分为三步:
- 如果是非自动 commit,并且 commit 定时达到,那么就将所有已经 ack 的数据(这些数据的 offset 必须是连续的,不连续的数据不会进行 commit)进行 commit;
- 如果拉取的数据都已经发送,并且未 commit 的消息数(记录在
numUncommittedOffsets中)小于设置的最大 uncommit 数,那么就根据更新后的 offset (将 offset 重置到需要重试的 msg 的最小 offset,这样该 offset 后面的 msg 还是会被重新拉取)拉取数据,并将拉取到的数据存储到waitingToEmit集合中; - 如果
waitingToEmit集合中还有数据,就发送数据,但在发送数据的过程中,会进行判断,只发送没有 ack 的数据。
KafkaSpout 如何进行容错
举个示例,如下图所示
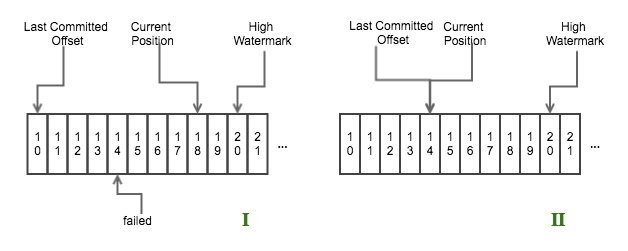
consumer offset
- 图1表示一个
nextTuple()循环结束之后,offset 为14那条数据处理失败,而offset 为15-18的数据处理成功; - 图2表示在下次循环 Step 1 结束之后、Step 2 开始之前,Consumer 会将 the last committed offset 重置到 offset 为14的位置。
也就是说从 offset 为14开始,后面的数据会重新发送。
有人可能会问,那样的话会不会造成数据重复发送?
Storm 是如何解决这个问题的呢?答案就是 Storm 会用一个 map 记录已经 ack 的数据(acked),Storm 在进行 commit 的时候也是根据这个 map 的数据进行 commit 的,不过 commit 数据的 offset 必须是连续的,如上图所示,只能将 offset 为11-13的数据 commit,而15-18的数据由于 offset 为14的数据未处理成功而不能 commit。offset 为11-13的数据在 commit 成功后会从 map 中移除,而 offset 为15-18的数据依然在 map 中,Storm 在将从 Kafka 拉取的数据加入到 waitingToEmit 集合时后,进行 emit 数据时,会先检测该数据是否存在 acked 中,如果存在的话,就证明该条数据已经处理过了,不会在进行发送。
这里有几点需要注意的:
- 对已经 ack 的 msg 进行 commit 时,所 commit 的 msg 的 offset 必须是连续的(该 msg 存储在一个 TreeMap 中,按 offset 排序),断续的数据会暂时接着保存在集合中,不会进行 commit,如果出现断续,那就证明中间有数据处理失败,需要重新处理;
- storm 处理 failed 的 msg,会保存到一个专门的集合中,在每次拉取数据时(是拉取数据,不是发送数据,发送数据时会检测该数据是否已经成功处理),会遍历该集合中包含的所有 TopicPartiion,获取该 partition 的 Last Committed Offset;
这样设计有一个副作用就是:如果有一个 msg 一直不成功,就会导致 KafkaSpout 因为这一条数据的影响而不断地重复拉取这批数据,造成整个拓扑卡在这里。
Kafka Rebalance 的影响
Kafka Rebalance 可以参考Consumer Rebalance.
KafkaSpout 实现了一个内部类用来监控 Group Rebalance 的情况,实现了两个回调函数,一旦发现 group 的状态变为 preparingRabalance 之后
onPartitionsRevoked这个方法会在 Consumer 停止拉取数据之后、group 进行 rebalance 操作之前调用,作用是对已经 ack 的 msg 进行 commit;onPartitionsAssigned这个方法 group 已经进行 reassignment 之后,开始拉取数据之前调用,作用是清理内存中不属于这个线程的 msg、获取 partition 的 last committed offset。
潜在的风险点
这部分还是有可能导致数据重复发送的,设想下面一种情况:
如果之前由于一个条消息处理失败(Partition 1),造成部分数据没有 commit 成功,在进行 rebalance 后,恰好 Partition 1 被分配到其他 spout 线程时,那么当前的 spout 就会关于 Partition 1 的相关数据删除掉,导致部分已经 commit 成功的数据(记录在 acked 中)被删除,而另外的 spout 就会重新拉取这部分数据进行处理,那么就会导致这部分已经成功处理的数据重复处理。
Storm 对 0.10.x 版 Kafka之commit offsets的更多相关文章
- Kafka 0.10.1版本源码 Idea编译
Kafka 0.10.1版本源码 Idea编译 1.环境准备 Jdk 1.8 Scala 2.11.12:下载scala-2.11.12.msi并配置环境变量 Gradle 5.6.4: 下载Grad ...
- Microsoft.Bcl.Build 1.0.10 稳定版发布
Microsoft.Bcl.Build 1.0.10 稳定版发布 解决了之前 1.0.8 在未下载相应的Nuget Package 的情况下项目无法加载的情况 但由于 Microsoft.Net.Ht ...
- VisualSVN 4.0.10 破解版 附上破解过程
VisualSVN一般情况下使用不需要破解,可以直接使用社区授权.但是社区授权不支持域用户. 如果要再域下面使用就需要破解了. 原版的VisualSVN和破解后的DLL已打包上传(仅供学习使用) 破解 ...
- 数据库 Navicat_Premium_11.0.10 破解版下载安装
下载地址:http://www.liangchan.net/soft/download.asp?softid=4785&downid=8&id=4804 破解说明:安装之后不要立即启动 ...
- UltraEdit for mac 3.2.0.10免费破解版下载!!
http://www.mactech.cn/a/108.html UltraEdit for mac 3.2.0.10破解版下载地址 看很多朋友不知道算号器的使用方法,分享如下: 1. 解压Ultra ...
- 【Navicat_Premium_11.0.10】破解版
数据库管理的超级工具 Navicat_Premium_11.0.10破解版: Navicat_Premium_11.0.10 ,功能全开,支持多种数据库,爽~ 下载地址请拖到本文最后: 在没和谐前永久 ...
- Kafka实践、升级和新版本(0.10)特性预研
本文来自于网易云社区 一.消息总线MQ和Kafka (挡在请求的第一线) 1. 几个应用场景 case a:上游系统往下游系统推送消息,而不关心处理结果: case b:一份新数据生成,需要实时保存到 ...
- 基于Web的Kafka管理器工具之Kafka-manager的编译部署详细安装 (支持kafka0.8、0.9和0.10以后版本)(图文详解)(默认端口或任意自定义端口)
不多说,直接上干货! 至于为什么,要写这篇博客以及安装Kafka-manager? 问题详情 无奈于,在kafka里没有一个较好自带的web ui.启动后无法观看,并且不友好.所以,需安装一个第三方的 ...
- Kafka 0.10.0
2.1 Producer API We encourage all new development to use the new Java producer. This client is produ ...
随机推荐
- ubuntu下查看-卸载软件(卸载.net core sdk的方法)
查看已安装的包:dpkg --list 查看正则匹配的包:dpkg --list 'dotnet-*' //查看以dotnet-开头的包 卸载匹配的包:sudo apt-get --purge rem ...
- FWT模板
代码来自51nod1570 #include<cstdio> #include<cstring> #include<algorithm> #define MN 50 ...
- hdu_1251统计难题(字典树Trie)
统计难题 Time Limit: 4000/2000 MS (Java/Others) Memory Limit: 131070/65535 K (Java/Others)Total Submi ...
- android文件管理器源码、斗鱼直播源码、企业级erp源码等
Android精选源码 文件清理管理器 自定义水平带数字的进度条以及自定义圆形带数字的进度条 利用sectionedRecyclerViewAdapter实现分组列表的recyclerView源码 流 ...
- 手把手教你撸一个 Webpack Loader
文:小 boy(沪江网校Web前端工程师) 本文原创,转载请注明作者及出处 经常逛 webpack 官网的同学应该会很眼熟上面的图.正如它宣传的一样,webpack 能把左侧各种类型的文件(webpa ...
- spring cloud-zuul的Filter详解
在前面我们使用zuul搭建了网关http://blog.csdn.net/liuchuanhong1/article/details/59056278 关于网关的作用,这里就不再次赘述了,我们今天的重 ...
- mysql之repair table 修复表札记
REPAIR [LOCAL | NO_WRITE_TO_BINLOG] TABLE tbl_name[,tbl_name] ... [QUICK] [EXTENDED] [USE_FRM] REP ...
- WIN2016安装织梦没写入权限怎么办听语音
配置好了WINSERVER2016环境,一切看起来都弄得差不多了,可是安装织梦的时候提示我没有写入权限,不能继续安装,于是我很郁闷,开始寻求解决办法. 工具/原料 WINSERVER2016 织梦5. ...
- dede 提交表单 发送邮件
第一步:要到dede后台设置好邮箱的资料,并且确定所用的邮箱开启了smtp 第二步:找到/plus/diy.php在 [cce]$query = "INSERT INTO `{$diy-&g ...
- iOS的相对路径和绝对路径
iOS程序有固定的文件访问限制,只能在自己的沙盒内. UIImage *img=[UIImage imageNamed:@"cellicon.png"]; 这段代码从相对路径加载了 ...