[Kaggle] dogs-vs-cats之模型训练
上一步建立好模型之后,现在就可以训练模型了。
主要代码如下:
import sys
#将当期路径加入系统path中
sys.path.append("E:\\CODE\\Anaconda\\tensorflow\\Kaggle\\My-TensorFlow-tutorials-master\\01 cats vs dogs\\") import os
import numpy as np
import tensorflow as tf
import input_data
import model #%% N_CLASSES = 2 #类别数
IMG_W = 208 # resize the image, if the input image is too large, training will be very slow.
IMG_H = 208
BATCH_SIZE = 16
CAPACITY = 2000 #队列中元素个数
MAX_STEP = 10000 #最大迭代次数 with current parameters, it is suggested to use MAX_STEP>10k
learning_rate = 0.0001 # with current parameters, it is suggested to use learning rate<0.0001 #%%
def run_training(): # you need to change the directories to yours.
#train_dir = '/home/kevin/tensorflow/cats_vs_dogs/data/train/'#数据存放路径
train_dir = 'E:\\data\\Dog_Cat\\train\\'
#logs_train_dir = '/home/kevin/tensorflow/cats_vs_dogs/logs/train/'#存放训练参数,模型等
logs_train_dir = "E:\\CODE\\Anaconda\\tensorflow\\Kaggle\\My-TensorFlow-tutorials-master\\01 cats vs dogs\\" train, train_label = input_data.get_files(train_dir) train_batch, train_label_batch = input_data.get_batch(train,
train_label,
IMG_W,
IMG_H,
BATCH_SIZE,
CAPACITY)
train_logits = model.inference(train_batch, BATCH_SIZE, N_CLASSES)#获得模型的输出
train_loss = model.losses(train_logits, train_label_batch)#获取loss
train_op = model.trainning(train_loss, learning_rate)#训练模型
train__acc = model.evaluation(train_logits, train_label_batch)#模型评估 summary_op = tf.summary.merge_all()
sess = tf.Session()
train_writer = tf.summary.FileWriter(logs_train_dir, sess.graph)#把summary保存到路径中
saver = tf.train.Saver() sess.run(tf.global_variables_initializer())
coord = tf.train.Coordinator()
threads = tf.train.start_queue_runners(sess=sess, coord=coord) try:
for step in np.arange(MAX_STEP):
if coord.should_stop():
break
_, tra_loss, tra_acc = sess.run([train_op, train_loss, train__acc]) if step % 50 == 0:
print('Step %d, train loss = %.2f, train accuracy = %.2f%%' %(step, tra_loss, tra_acc*100.0))
summary_str = sess.run(summary_op)
train_writer.add_summary(summary_str, step) if step % 2000 == 0 or (step + 1) == MAX_STEP:
checkpoint_path = os.path.join(logs_train_dir, 'model.ckpt')
saver.save(sess, checkpoint_path, global_step=step)#保存模型及参数 except tf.errors.OutOfRangeError:
print('Done training -- epoch limit reached')
finally:
coord.request_stop() coord.join(threads)
sess.close() run_training()
一些函数说明如下:
1)tf.summary.merge_all
作用:Merges all summaries collected in the default graph.
2)tf.summary.FileWriter
作用:Writes Summary protocol buffers to event files.
3)tf.train.Saver
作用:保存和恢复变量。
举例:
saver.save(sess, 'my-model', global_step=0) ==> filename: 'my-model-0'
...
saver.save(sess, 'my-model', global_step=1000) ==> filename: 'my-model-1000'
4)add_summary
作用:Writes Summary protocol buffers to event files.
程序运行后,控制台输出如下:
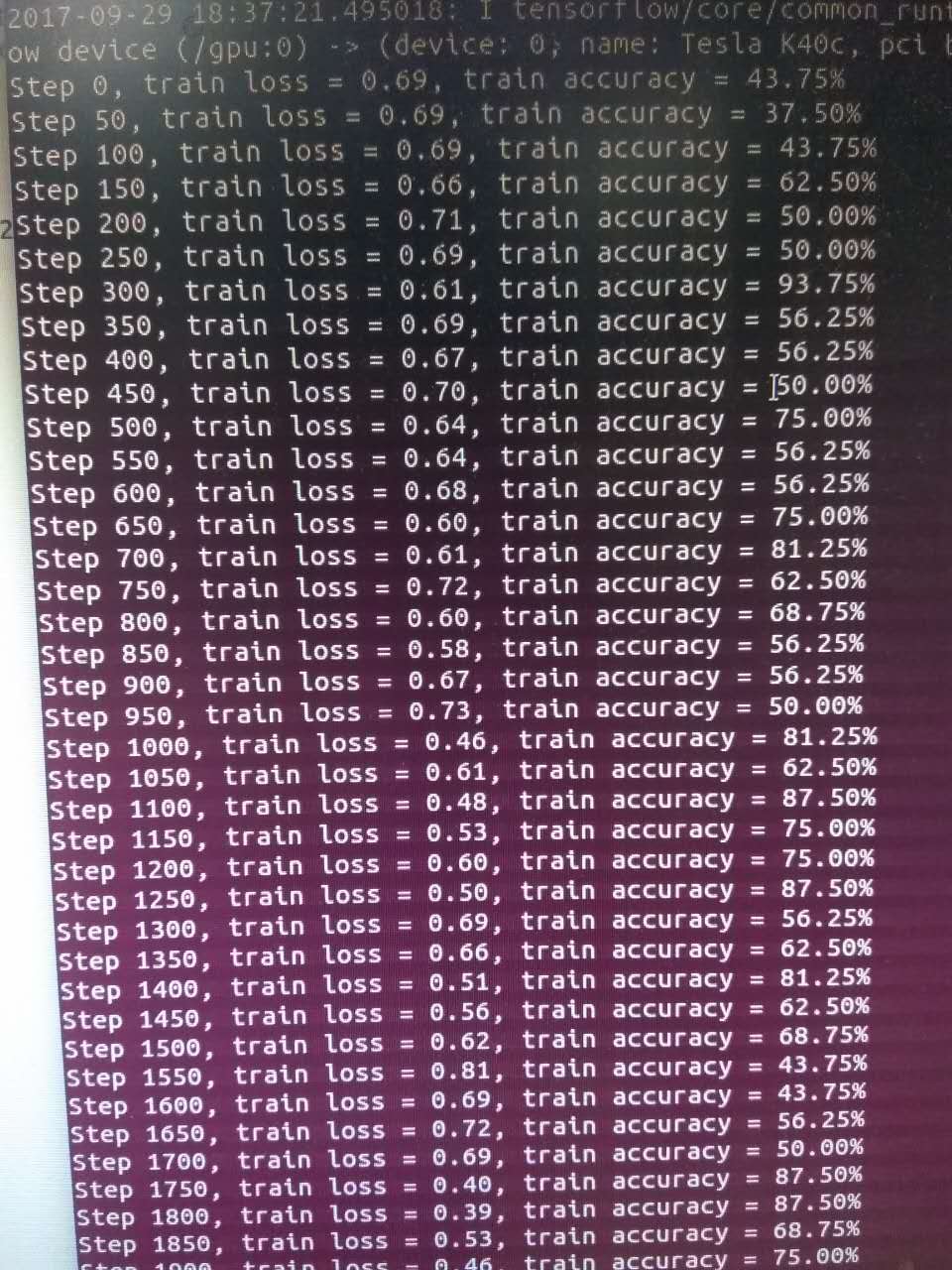
训练期间,也可以使用tensorboard查看模型训练情况。
可以使用如下命令打开tensorboard。
tensorboard --logdir=log文件路径
log文件路径即为程序中设置的logs_train_dir。
启动tensorboard之后,打开浏览器,输入对应网址,即可查看训练情况。
整体解码如下图:
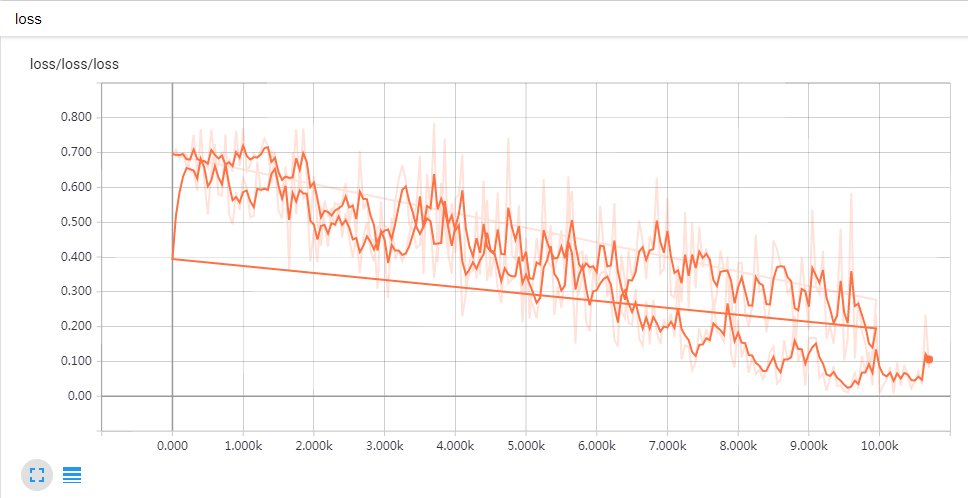
loss与step的关系如下(两条曲线的原因是训练了两次,一次迭代了10000步,另一次迭代了15000步):
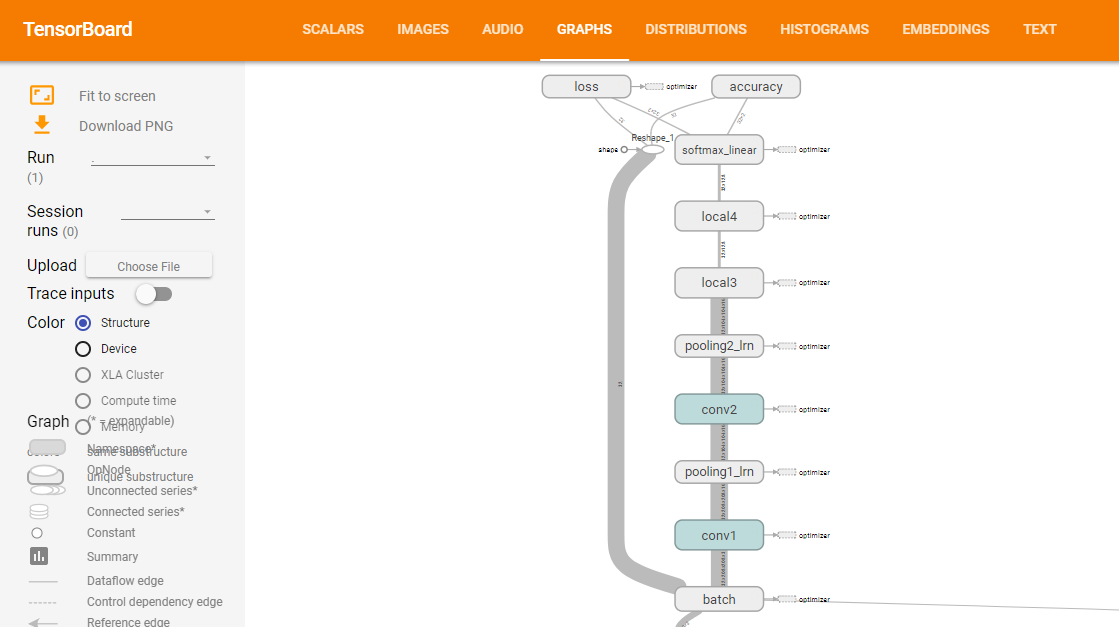
也可以选择查看模型:
说明:
代码来自:https://github.com/kevin28520/My-TensorFlow-tutorials,略有修改
函数作用主要参考tensorflow官网。https://www.tensorflow.org/versions/master/api_docs/
[Kaggle] dogs-vs-cats之模型训练的更多相关文章
- A TensorBoard plugin for visualizing arbitrary tensors in a video as your network trains.Beholder是一个TensorBoard插件,用于在模型训练时查看视频帧。
Beholder is a TensorBoard plugin for viewing frames of a video while your model trains. It comes wit ...
- AI佳作解读系列(一)——深度学习模型训练痛点及解决方法
1 模型训练基本步骤 进入了AI领域,学习了手写字识别等几个demo后,就会发现深度学习模型训练是十分关键和有挑战性的.选定了网络结构后,深度学习训练过程基本大同小异,一般分为如下几个步骤 定义算法公 ...
- VGG19模型训练+读取
目录 VGG-19模型简单介绍 VGG-19模型文件介绍 分析模型文件 mean值查看 Weight和Bias查看 读取代码 读取模型 训练代码 参考资料 VGG-19的介绍和训练这里不做说明,网上资 ...
- 机器学习使用sklearn进行模型训练、预测和评价
cross_val_score(model_name, x_samples, y_labels, cv=k) 作用:验证某个模型在某个训练集上的稳定性,输出k个预测精度. K折交叉验证(k-fold) ...
- 谷歌大规模机器学习:模型训练、特征工程和算法选择 (32PPT下载)
本文转自:http://mp.weixin.qq.com/s/Xe3g2OSkE3BpIC2wdt5J-A 谷歌大规模机器学习:模型训练.特征工程和算法选择 (32PPT下载) 2017-01-26 ...
- facenet模型训练
做下记录,脚本如下: 对比 python3 src/compare.py ../models/-/ ../faces/pyimgs/dashenlin/ytwRkvSdG1000058.png ../ ...
- 人脸检测及识别python实现系列(3)——为模型训练准备人脸数据
人脸检测及识别python实现系列(3)——为模型训练准备人脸数据 机器学习最本质的地方就是基于海量数据统计的学习,说白了,机器学习其实就是在模拟人类儿童的学习行为.举一个简单的例子,成年人并没有主动 ...
- 【机器学习PAI实践十】深度学习Caffe框架实现图像分类的模型训练
背景 我们在之前的文章中介绍过如何通过PAI内置的TensorFlow框架实验基于Cifar10的图像分类,文章链接:https://yq.aliyun.com/articles/72841.使用Te ...
- kaldi基于GMM的单音素模型 训练部分
目录 1. gmm-init-mono 模型初始化 2. compile-train-graghs 训练图初始化 3. align-equal-compiled 特征文件均匀分割 4. gmm-acc ...
随机推荐
- gdb命令调试技巧
gdb命令调试技巧 一.信息显示1.显示gdb版本 (gdb) show version2.显示gdb版权 (gdb) show version or show warranty3.启动时不显示提示信 ...
- html-简单的简历表制作
代码如下: <!DOCTYOE html> <html> <head> <meta charset='UTF-8'/> <title>课后作 ...
- 源码实现 --> strcpy
拷贝字符串到目标字符串 函数 char *strcpy(char *strDestination, const char *strSource); 复制源串strSource到目标串strDestin ...
- 理解HDFS
综述 当数据集的大小超过一台独立的物理计算机的存储能力时,就有必要对它进行分区并存储到若干台单独的计算机上.HDFS是hadoop的主要分布式存储系统,一个HDFS集群主要包括NameNode用来管理 ...
- 使用MVC5+Entity Framework6的Code First模式创建数据库并实现增删改查功能
此处采用VS2017+SqlServer数据库 一.创建项目并引用dll: 1.创建一个MVC项目 2.采用Nuget安装EF6.1.3 二.创建Model 在models文件夹中,建立相应的mode ...
- alpha冲刺第四天
一.合照 二.项目燃尽图 三.项目进展 今天实现了登录界面和服务器的连接了,牵手成功. 一些具体的界面细化实现,一些button的响应实现 四.明日规划 登录界面和服务器的连接实现耗费了太多时间,接下 ...
- iOS极光推送SDK的使用流程
一.极光推送简介 极光推送是一个端到端的推送服务,使得服务器端消息能够及时地推送到终端用户手机上,整合了iOS.Android和WP平台的统一推送服务.使用起来方便简单,已于集成,解决了原生远程推送繁 ...
- Linux进程调度分析
原文:http://www.2cto.com/os/201112/113229.html 操作系统要实现多进程,进程调度必不可少. 有人说,进程调度是操作系统中最为重要的一个部分.我觉得这种说法说得太 ...
- 支付宝sdk集成,报系统繁忙 请稍后再试(ALI64)
移动快捷支付,往往需要集成支付宝的sdk,集成的过程相对简单,只要按照支付宝的文档,进行操作一般不会出问题. 下面主要说明一下,集成sdk后报"系统繁忙 请稍后再试(A ...
- Flask 学习 五 电子邮件
pip install mail from flask_mail import Mail # 邮件配置 app.config['MAIL_SERVER']='smtp.qq.com' app.conf ...