详解k8s原生的集群监控方案(Heapster+InfluxDB+Grafana) - kubernetes
1、浅析监控方案
heapster是一个监控计算、存储、网络等集群资源的工具,以k8s内置的cAdvisor作为数据源收集集群信息,并汇总出有价值的性能数据(Metrics):cpu、内存、network、filesystem等,然后将这些数据输出到外部存储(backend),如InfluxDB,最后再通过相应的UI界面进行可视化展示,如grafana。 另外heapster的数据源和外部存储都是可插拔的,所以可以很灵活的组建出很多监控方案,如:Heapster+ElasticSearch+Kibana等等。
Heapster的整体架构图:
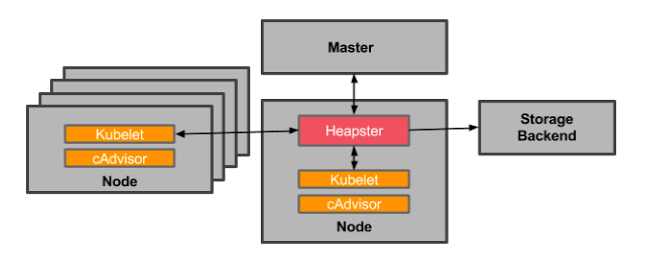
2、部署
本篇我们将实践 Heapster + InfluxDB + Grafana 的监控方案。使用官方提供的yml文件有一些小问题,请参考以下改动和说明:
2.1、创建InfluxDB资源对象
apiVersion: apps/v1
kind: Deployment
metadata:
name: monitoring-influxdb
namespace: kube-system
spec:
replicas: 1
selector:
matchLabels:
task: monitoring
k8s-app: influxdb
template:
metadata:
labels:
task: monitoring
k8s-app: influxdb
spec:
containers:
- name: influxdb
image: k8s.gcr.io/heapster-influxdb-amd64:v1.3.3
volumeMounts:
- mountPath: /data
name: influxdb-storage
volumes:
- name: influxdb-storage
emptyDir: {}
---
apiVersion: v1
kind: Service
metadata:
labels:
task: monitoring
kubernetes.io/cluster-service: 'true'
kubernetes.io/name: monitoring-influxdb
name: monitoring-influxdb
namespace: kube-system
spec:
type: NodePort
ports:
- nodePort: 31001
port: 8086
targetPort: 8086
selector:
k8s-app: influxdb
注意:这里我们使用NotePort暴露monitoring-influxdb服务在主机的31001端口上,那么InfluxDB服务端的地址:http://[host-ip]:31001 ,记下这个地址,以便创建heapster和为grafana配置数据源时,可以直接使用。,
2.1、创建Grafana资源对象
apiVersion: apps/v1
kind: Deployment
metadata:
name: monitoring-grafana
namespace: kube-system
spec:
replicas: 1
selector:
matchLabels:
task: monitoring
k8s-app: grafana
template:
metadata:
labels:
task: monitoring
k8s-app: grafana
spec:
containers:
- name: grafana
image: k8s.gcr.io/heapster-grafana-amd64:v4.4.3
ports:
- containerPort: 3000
protocol: TCP
volumeMounts:
- mountPath: /etc/ssl/certs
name: ca-certificates
readOnly: true
- mountPath: /var
name: grafana-storage
env:
- name: INFLUXDB_HOST
value: monitoring-influxdb
- name: GF_SERVER_HTTP_PORT
value: "3000"
# The following env variables are required to make Grafana accessible via
# the kubernetes api-server proxy. On production clusters, we recommend
# removing these env variables, setup auth for grafana, and expose the grafana
# service using a LoadBalancer or a public IP.
- name: GF_AUTH_BASIC_ENABLED
value: "false"
- name: GF_AUTH_ANONYMOUS_ENABLED
value: "true"
- name: GF_AUTH_ANONYMOUS_ORG_ROLE
value: Admin
- name: GF_SERVER_ROOT_URL
# If you're only using the API Server proxy, set this value instead:
# value: /api/v1/namespaces/kube-system/services/monitoring-grafana/proxy
value: /
volumes:
- name: ca-certificates
hostPath:
path: /etc/ssl/certs
- name: grafana-storage
emptyDir: {}
---
apiVersion: v1
kind: Service
metadata:
labels:
# For use as a Cluster add-on (https://github.com/kubernetes/kubernetes/tree/master/cluster/addons)
# If you are NOT using this as an addon, you should comment out this line.
kubernetes.io/cluster-service: 'true'
kubernetes.io/name: monitoring-grafana
name: monitoring-grafana
namespace: kube-system
spec:
# In a production setup, we recommend accessing Grafana through an external Loadbalancer
# or through a public IP.
# type: LoadBalancer
# You could also use NodePort to expose the service at a randomly-generated port
type: NodePort
ports:
- nodePort: 30108
port: 80
targetPort: 3000
selector:
k8s-app: grafana
虽然Heapster已经预先配置好了Grafana的Datasource和Dashboard,但是为了方便访问,这里我们使用NotePort暴露monitoring-grafana服务在主机的30108上,那么Grafana服务端的地址:http://registry.wuling.com:30108 ,通过浏览器访问,为Grafana修改数据源,如下:
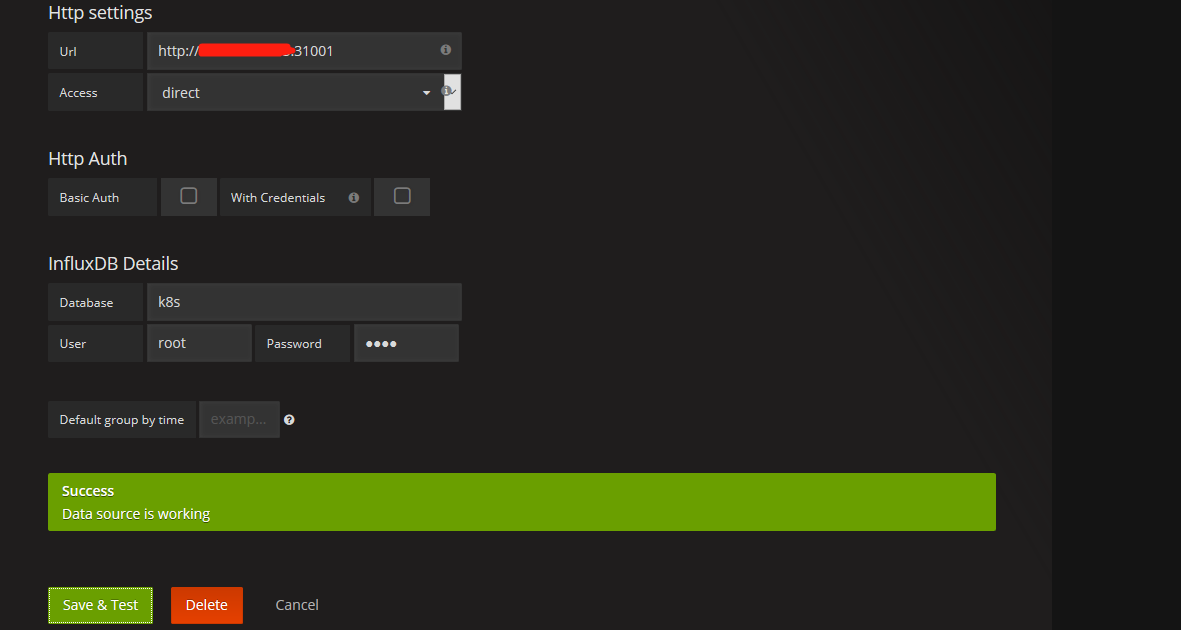
标红的地方,为上一步记录下的InfluxDB服务端的地址。
2.2、创建Heapster资源对象
apiVersion: v1
kind: ServiceAccount
metadata:
name: heapster
namespace: kube-system
---
apiVersion: extensions/v1beta1
kind: Deployment
metadata:
name: heapster
namespace: kube-system
spec:
replicas: 1
selector:
matchLabels:
task: monitoring
k8s-app: heapster
template:
metadata:
labels:
task: monitoring
k8s-app: heapster
spec:
serviceAccountName: heapster
containers:
- name: heapster
image: k8s.gcr.io/heapster-amd64:v1.4.2
imagePullPolicy: IfNotPresent
command:
- /heapster
- --source=kubernetes:https://kubernetes.default
- --sink=influxdb:http://150.109.39.33:31001 # 这里填写刚刚记录下的InfluxDB服务端的地址。
---
apiVersion: v1
kind: Service
metadata:
labels:
task: monitoring
# For use as a Cluster add-on (https://github.com/kubernetes/kubernetes/tree/master/cluster/addons)
# If you are NOT using this as an addon, you should comment out this line.
kubernetes.io/cluster-service: 'true'
kubernetes.io/name: Heapster
name: heapster
namespace: kube-system
spec:
ports:
- port: 80
targetPort: 8082
selector:
k8s-app: heapster
--source 为heapster指定获取集群信息的数据源。参考:https://github.com/kubernetes/heapster/blob/master/docs/source-configuration.md
--sink 为heaster指定后端存储,这里我们使用InfluxDB,其他的,请参考:https://github.com/kubernetes/heapster/blob/master/docs/sink-owners.md
这里heapster留下了一个的坑,请继续往下看,当我部署完heapster,查看Heapster容器组的标准输出:
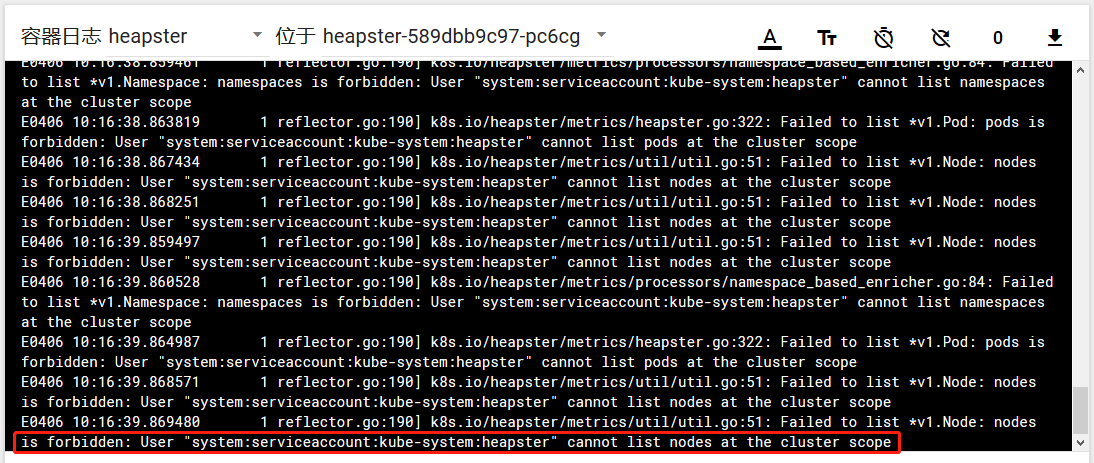
很多人都以为是https或者k8s配置的问题,于是去就慌忙的去配置InSecure http方式,导致坑越来越深,透明度越来越低,更是无从下手,我也是这样弄了很久,都较上劲了,此处省略一万字。。。,当这些路子都走遍了,再次品读下面的原文:

才发现是权限的问题,heaster默认使用一个令牌(Token)与ApiServer进行认证,通过查看heapster.yml发现 serviceAccountName: heapster ,现在明白了吧,就是heaster没有权限,那么如何授权呢-----给heaster绑定一个有权限的角色就行了,如下:
apiVersion: rbac.authorization.k8s.io/v1beta1
kind: ClusterRoleBinding
metadata:
name: heapster
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: ClusterRole
name: cluster-admin
subjects:
- kind: ServiceAccount
name: heapster
namespace: kube-system
当创建heapster资源的时候,直接把这段代码加上,就行了。
3、从不同维度查看应用程序性能指标
在k8s集群中,应用程序的性能指标,需要从不同的维度(containers, pods, services, and whole clusters)进行统计。以便于使用户深入了解他们的应用程序是如何执行的以及可能出现的应用程序瓶颈。
3.1、通过dashboard查看集群概况
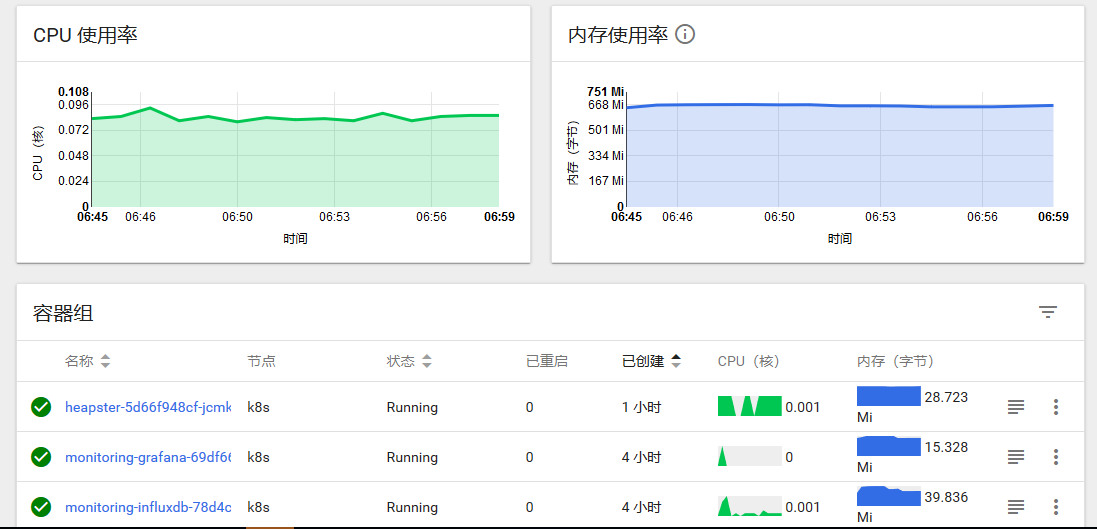
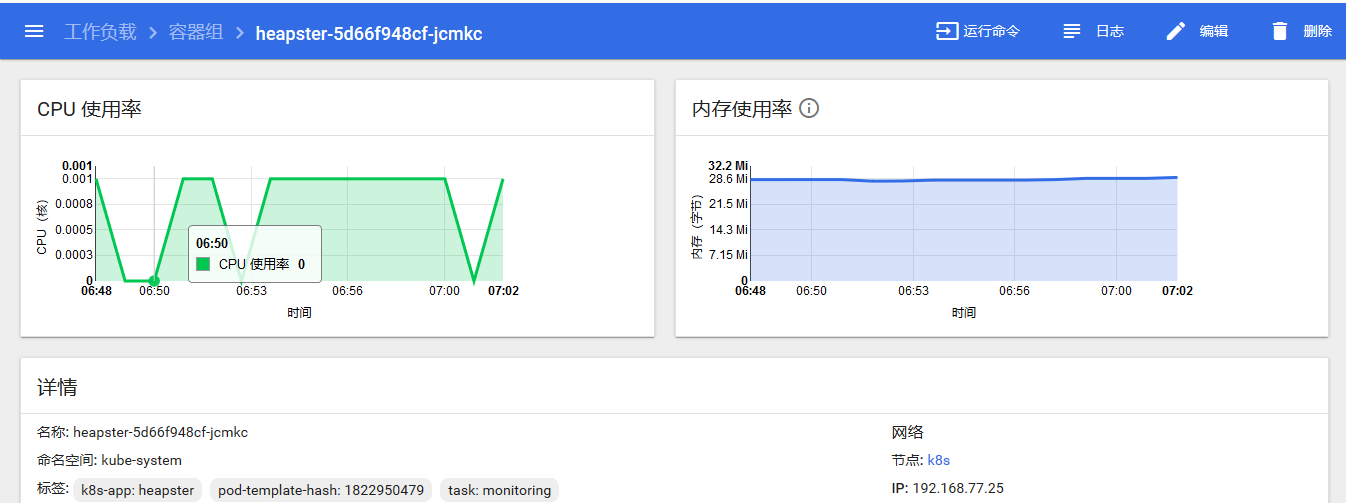
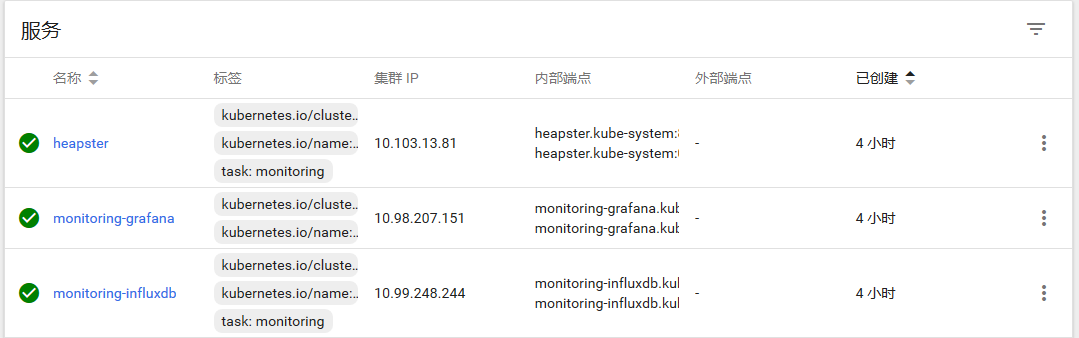
整个监控方案部署成功后,从上图可以看到,在不同粒度/维度下,dashboard上可以呈现对象的具体CPU和内存使用率。
3.2、通过Grafana查看集群详情(cpu、memory、filesystem、network)
通过Grafana可以查看某个Node或Pod的所有资源使用率,包括集群节点、不同NameSpace下的单个Pod等,一部分截图如下所示:
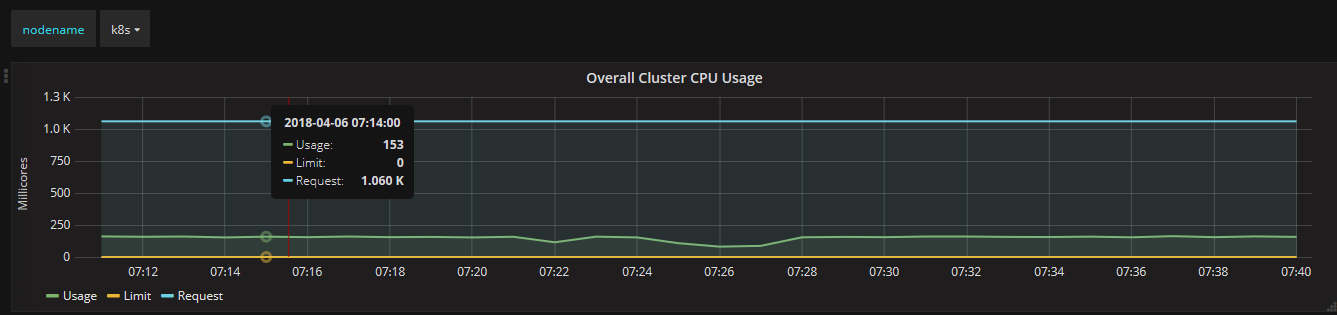
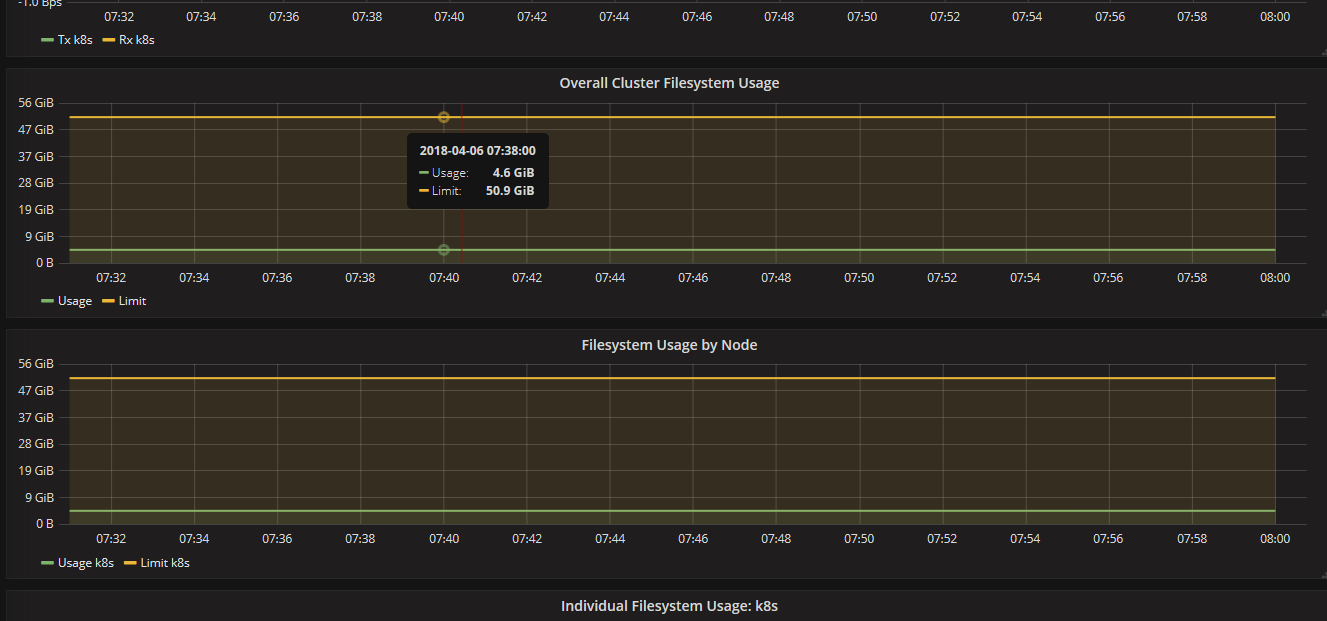
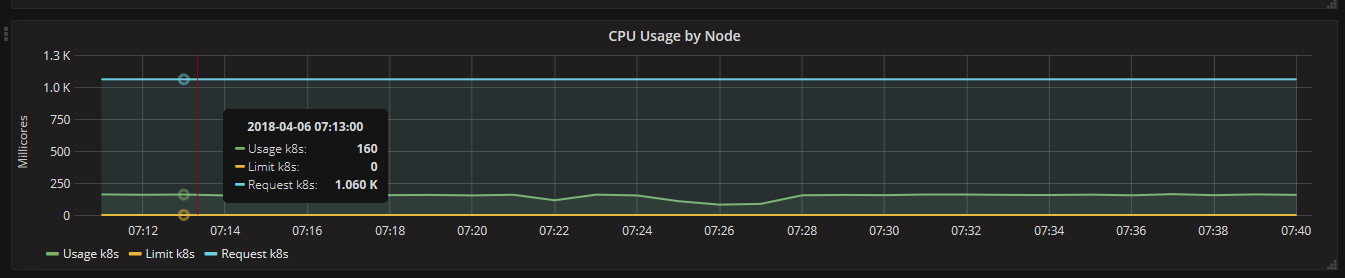
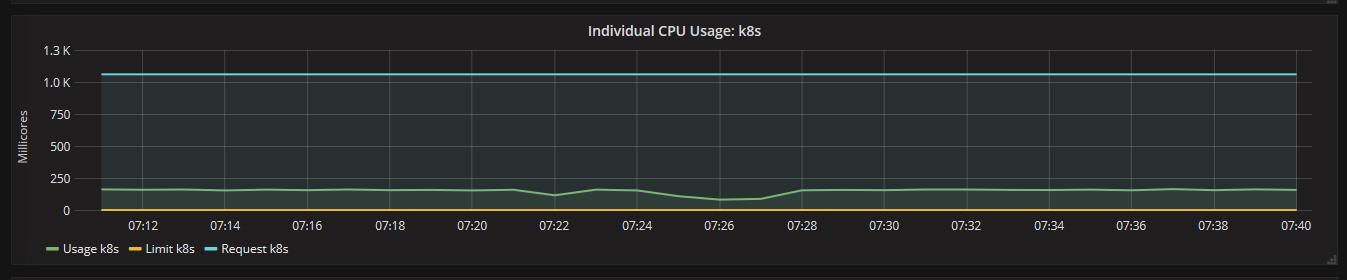

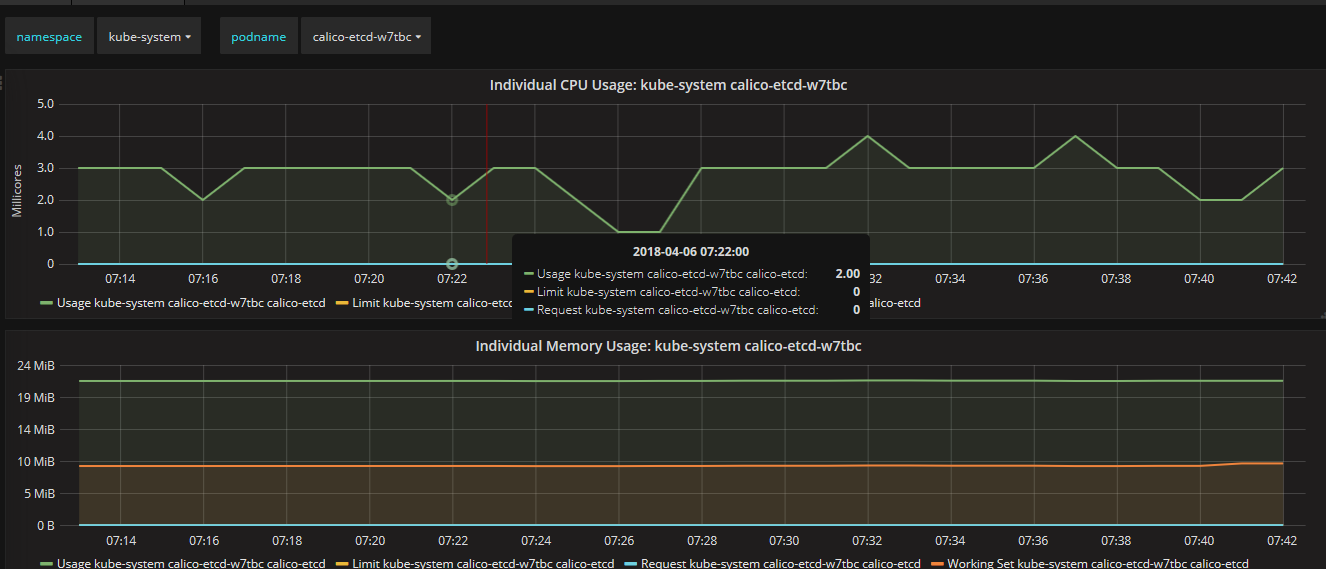
从上面可以看到,Heapster无缝衔接Grafana,提供了完美的数据展示,很直观、友好。我们也可以学习 Grafana 来自定制出更美观和满足特定业务需求的Dashboard。
4、总结
本篇我们详解了k8s原生的监控方案,它主要监控的是pod和node,对于kubernetes其他组件(API Server、Scheduler、Controller Manager等)的监控显得力不从心,而prometheus(一套开源的监控&报警&时间序列数据库的组合)功能更全面,后面有时间会进行实战。监控是一个非常大的话题,监控的目的是为预警,预警的目的是为了指导系统自愈。只有把 监控=》预警 =》自愈 三个环节都完成了,实现自动对应用程序性能和故障管理,才算得上是一个真正意义的应用程序性能管理系统(APM),所以这个系列会一直朝着这个目标努力下去,请大家继续关注。如果有什么好的想法,欢迎评论区交流。
延伸阅读
https://github.com/kubernetes/heapster
如果你觉得本篇文章对您有帮助的话,感谢您的【推荐】。
如果你对 kubernets 感兴趣的话可以关注我,我会定期的在博客分享我的学习心得。
详解k8s原生的集群监控方案(Heapster+InfluxDB+Grafana) - kubernetes的更多相关文章
- Redis详解(七)——集群
Redis详解(七)--集群 Redis3.0版本之前,可以通过Redis Sentinel(哨兵)来实现高可用 ( HA ),从3.0版本之后,官方推出了Redis Cluster,它的主要用途是 ...
- Solr系列二:solr-部署详解(solr两种部署模式介绍、独立服务器模式详解、SolrCloud分布式集群模式详解)
一.solr两种部署模式介绍 Standalone Server 独立服务器模式:适用于数据规模不大的场景 SolrCloud 分布式集群模式:适用于数据规模大,高可靠.高可用.高并发的场景 二.独 ...
- Zookeeper详解-伪分布式和集群搭建(八)
说到分布式开发Zookeeper是必须了解和掌握的,分布式消息服务kafka .hbase 到hadoop等分布式大数据处理都会用到Zookeeper,所以在此将Zookeeper作为基础来讲解. Z ...
- Kafka 详解(二)------集群搭建
这里通过 VMware ,我们安装了三台虚拟机,用来搭建 kafka集群,虚拟机网络地址如下: hostname ipaddress ...
- Redis面试题详解:哨兵+复制+事务+集群+持久化等
Redis主要有哪些功能? 1.哨兵(Sentinel)和复制(Replication) Redis服务器毫无征兆的罢工是个麻烦事,如何保证备份的机器是原始服务器的完整备份呢?这时候就需要哨兵和复制. ...
- 大数据入门第十六天——流式计算之storm详解(三)集群相关进阶
一.集群提交任务流程分析 1.集群提交操作 参考:https://www.jianshu.com/p/6783f1ec2da0 2.任务分配与启动流程 参考:https://www.cnblogs.c ...
- 详解k8s组件Ingress边缘路由器并落地到微服务 - kubernetes
写在前面 Ingress 英文翻译 进入;进入权;进食,更准确的讲就是入口,即外部流量进入k8s集群必经之口.这到大门到底有什么作用?我们如何使用Ingress?k8s又是如何进行服务发现的呢?先看一 ...
- (转)详解k8s组件Ingress边缘路由器并落地到微服务 - kubernetes
转:https://www.cnblogs.com/justmine/p/8991379.html 写在前面 Ingress 英文翻译 进入;进入权;进食,更准确的讲就是入口,即外部流量进入k8s集群 ...
- k8s集群监控 cadvisor/exporter+prometheus+grafana
### k8s监控处理 ### 1.cadvisor/exporter+prometheus+grafana 安装#### 1.1 配置nfs安装```shellubuntu: nfs 服务器 apt ...
随机推荐
- Sublime text使用快捷键
作者:gyfnice链接:https://www.zhihu.com/question/24896283/answer/34327939来源:知乎著作权归作者所有,转载请联系作者获得授权. 代码片段 ...
- JavaScript prototype详解
用过JavaScript的同学们肯定都对prototype如雷贯耳,但是这究竟是个什么东西却让初学者莫衷一是,只知道函数都会有一个prototype属性,可以为其添加函数供实例访问,其它的就不清楚了, ...
- python基础autopep8__python代码规范
关于PEP 8 PEP 8,Style Guide for Python Code,是Python官方推出编码约定,主要是为了保证 Python 编码的风格一致,提高代码的可读性. 官网地址:http ...
- python:解析js中常见的 不带引号的key的 json
首先要明晰一点,json标准中,key是必须要带引号的,所以标准json模块解析不带引号的key的 json就会抛错 不过有一些lib可以帮我们解析 如:demjson(链接) >>> ...
- python中RabbitMQ的使用(安装和简单教程)
1,简介 RabbitMQ是一个由erlang开发的AMQP(Advanced Message Queue )的开源实现的产品,RabbitMQ是一个消息代理,从"生产者"接收消息 ...
- HTML5 & MUI 界面样式
垂直居中+自动换行 样式效果如下所示,当文字没有超出一行时,显示如“备注信息”,当文字超出一行时,显示如“维修地点” HTML代码如下: <div class="mui-input-r ...
- python 文件的写删改
# coding=utf-8 # !/usr/bin/python # -*- coding: UTF-8 -*- import io import os def file_chance(): #修改 ...
- testng增加失败重跑机制
注: 以下内容引自 http://www.yeetrack.com/?p=1015 testng增加失败重跑机制 Posted on 2014 年 10 月 31 日 使用Testng框架搭建自动测试 ...
- 安装Navicat for MySQL
注: 以下内容引自 https://www.cnblogs.com/da19951208/p/6403607.html Navicat for MySQL下载.安装与破解 一:下载Navicat ...
- linux相关命令及配置(四)
Linux第四章课堂笔记一.RPM包管理命令 1.RPM包是本地文件,存在于本地文件中 2.使用RPM命令管理.rpm包 3.挂载光驱 # mount /dev/cdrom /media/ 查看:rp ...