ZooKeeper 增加Observer部署模式提高性能
Observer:在不伤害写性能的情况下扩展ZooKeeper。
虽然通过Client直接连接到ZooKeeper集群的性能已经很好了,可是这样的架构假设要承受超大规模的Client,就必须添加ZooKeeper集群的Server数量,随着Server的添加,ZooKeeper集群的写性能必定下降。我们知道ZooKeeper的ZNode变更是要过半数投票通过,随着机器的添加,因为网络消耗等原因必定导致投票成本添加,从而导致写性能的下降。
Observer是一种新型的ZooKeeper节点。能够帮助解决上述问题,提供ZooKeeper的可扩展性。Observer不參与投票,仅仅是简单的接收投票结果。因此我们添加再多的Observer,也不会影响集群的写性能。除了这个区别,其它的和Follower基本上全然一样。比如:Client都能够连接到他们,而且都能够发送读写请求给他们,收到写请求都会上报到Leader。
Observer有另外一个优势,由于它不參与投票,所以他们不属于ZooKeeper集群的关键部位,即使他们Failed,或者从集群中断开,也不会影响集群的可用性。
Observer和Follower在一些方面是一样的。详细点来讲,他们都向Leader提交proposal(投票)。但与Follower不同,Observer不参与投票的过程。它简单的通过接收Leader发过来的INFORM(通知)消息来learn已经Commit的proposal。因为Leader都会给Follower和Observer发送INFORM消息,所以它们都被称为Learner。
INFORM消息背后的原理
因为Observer不会接收proposal并参与投票,Leader不会发送proposal给Observer。Leader发送给Follower的Commit消息只包含zxid,并没有proposal本身。所以,只发送Commit消息给Observer则不会让Observer得知已提交的proposal。这就是使用INFORM消息的原因,此消息本质上是一个包含了已被Commit的proposal的Commit消息。
简而言之,Follower会得到两个消息,而Observer只会得到一个。Follower通过广播得到proposal的内容,接下来获得一个简单Commit消息,此消息只包含了zxid。相反,Observer得到一个包含了已被Commit的proposal的INFORM消息。
参与了决定是否Commit一个proposal的投票的server就称为PARTICIPANT Server,Leader和Follower都属于这种Server。Observer则称为OBSERVER Server。
使用Observer模式的一个主要的理由就是对读请求进行扩展。通过增加更多的Observer,可以接收更多的请求的流量,却不会牺牲写操作的吞吐量。注意到写操作的吞吐量取决于quorum的Size。如果增加更多的Server进行投票,quorum会变大,这会降低写操作的吞吐量。然而增加Observer并不会完全没有损耗,每一个新的Observer在每提交一个事务后收到一条额外的消息,这就是前面提到的INFORM消息。这个损耗比起加入Follower来投票来说损耗更少。
使用Observer的另一个原因是跨数据中心部署。把participant分散到多个数据中心可能会极大拖慢系统,因为数据中心之间的网络的延迟。使用Observer的话,更新操作都在一个单独的数据中心来处理,并发送到其他数据中心,让其他数据中心的client消费数据。阿里开源的跨机房同步系统Otter就使用了Observer模式,可以参考。
注意Observer的使用并无法完全消除数据中心之间的网络延迟,因为Observer不得不把更新请求转发到另一个数据中心的Leader,并处理INFORM消息,网络速度极慢的话也会有影响,它的优势是为本地读请求提供快速响应。
场景应用:
依据Observer的特点。我们能够使用Observer做跨数据中心部署。假设把Leader和Follower分散到多个数据中心的话,由于数据中心之间的网络的延迟。势必会导致集群性能的大幅度下降。使用Observer的话,将Observer跨机房部署。而Leader和Follower部署在单独的数据中心,这样更新操作会在同一个数据中心来处理,并将数据发送的其它数据中心(包括Observer的),然后Client就能够在其它数据中心查询数据了。可是使用了Observer并不是就能全然消除数据中心之间的延迟,由于Observer还得接收Leader的同步结果合Observer有更新请求也必须转发到Leader,所以在网络延迟非常大的情况下还是会有影响的,它的优势就为了本地读请求的高速响应。
大致的架构例如以下图:
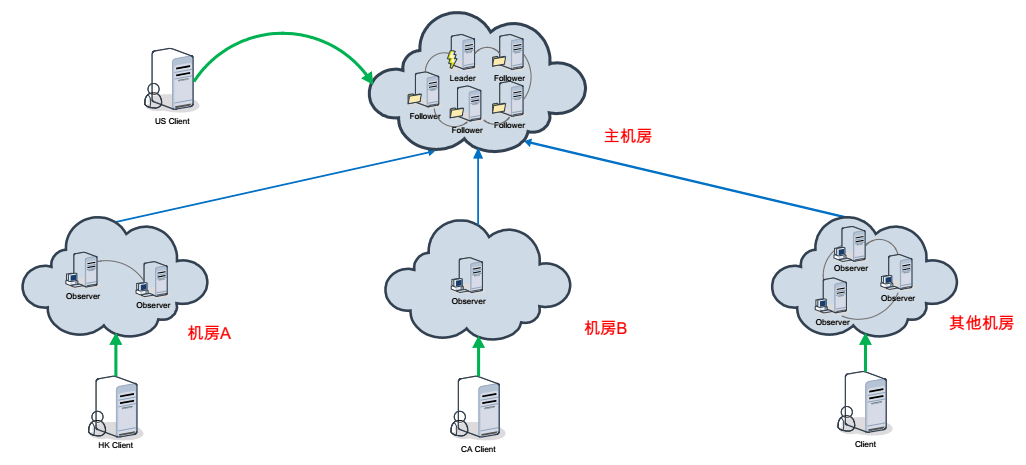
配置
为了使用Observer模式,在任何想变成Observer模式的配置文件($ZOOKEEPER_HOME/conf/zoo.cfg)中加入如下配置:
peerType=observer
并在所有Server的配置文件($ZOOKEEPER_HOME/conf/zoo.cfg)中,配置成Observer模式的server的那行配置追加:observer,例如:
server.1:localhost:2181:3181:observer
然后客户端的操作和Leader和Follow模式完全不变。
zookeeper写请求流程图:
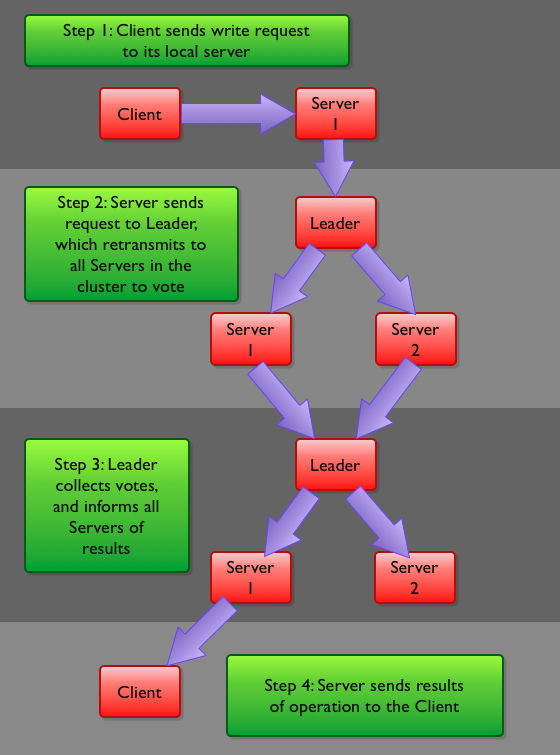
observer服务器在这个流程中只参与了1,4两个步骤,不参与投票。
https://www.cnblogs.com/EasonJim/p/7488484.html
http://blog.csdn.net/xhh198781/article/details/6665556
ZooKeeper 增加Observer部署模式提高性能的更多相关文章
- ZooKeeper增加Observer部署模式提高性能(转)
除了Leader和Follow模式之外,还有第三种模式:Observer模式. Observer:在不伤害写性能的情况下扩展ZooKeeper. 虽然通过Client直接连接到ZooKeeper集群的 ...
- zookeeper有几种部署模式? zookeeper 怎么保证主从节点的状态同步?
一.zookeeper的三种部署模式 Zookeeper 有三种部署模式分别是单机模式.伪集群模式.集群模式.这三种模式在不同的场景下使用: 单机部署:一般用来检验 Zookeeper 基础功能,熟悉 ...
- Zookeeper 有哪几种几种部署模式?
部署模式:单机模式.伪集群模式.集群模式.
- Centos6下zookeeper集群部署记录
ZooKeeper是一个开放源码的分布式应用程序协调服务,它包含一个简单的原语集,分布式应用程序可以基于它实现同步服务,配置维护和命名服务等. Zookeeper设计目的 最终一致性:client不论 ...
- SQL Server 性能优化之——系统化方法提高性能
SQL Server 性能优化之——系统化方法提高性能 阅读导航 1. 概述 2. 规范逻辑数据库设计 3. 使用高效索引设计 4. 使用高效的查询设计 5. 使用技术分析低性能 6. 总结 1. 概 ...
- php大型网站如何提高性能和并发访问
一.大型网站性能提高策略: 大型网站,比如门户网站,在面对大量用户访问.高并发请求方面,基本的解决方案集中在这样几个环节:使用高性能的服务器.高性能的数据库.高效率的编程语言.还有高性能的Web容器. ...
- Zookeeper安装和部署
Zookeeper安装和部署:ZooKeeper是一个分布式的,开放源码的分布式应用程序协调服务,是Google的Chubby一个开源的实现,是Hadoop和Hbase的重要组件.它是一个为分布式应用 ...
- ASP.NET MVC深入浅出系列(持续更新) ORM系列之Entity FrameWork详解(持续更新) 第十六节:语法总结(3)(C#6.0和C#7.0新语法) 第三节:深度剖析各类数据结构(Array、List、Queue、Stack)及线程安全问题和yeild关键字 各种通讯连接方式 设计模式篇 第十二节: 总结Quartz.Net几种部署模式(IIS、Exe、服务部署【借
ASP.NET MVC深入浅出系列(持续更新) 一. ASP.NET体系 从事.Net开发以来,最先接触的Web开发框架是Asp.Net WebForm,该框架高度封装,为了隐藏Http的无状态模 ...
- 使用SQL Server 2000索引视图提高性能
什么是索引视图? 许多年来,Microsoft? SQL Server? 一直都提供创建虚拟表(称为视图)的功能.在过去,这些视图主要有两种用途: 提供安全机制,将用户限制在一个或多个基表中的数据的某 ...
随机推荐
- 学习grunt四解决yo webapp生成的是gulpfile而不是gruntfile问题
虽然gulp慢慢取代了gruntfile,但是还有大部分的github源码保留gruntfile,另外我们开发项目也不是全用gulp,也是用grunt. 但是yeoman上generator-weba ...
- C#基础笔记(第十一天)
1.复习字符串(1)字符串的不可变性(2)字符串的方法:1)Split() 分割 把字符串中不想要的内容分割掉 返回一个字符串类型的数组 可以添加StringSplitOption.RemoveEmp ...
- 11 jmeter之图形监控扩展
Jmeter默认监听器的缺陷 Jmeter默认的监听器在表格.文字方面比较健全,但是在图形监控方面比较逊色,尤其在监控Windows或Linux的系统资源方面.但是jmeter作为一款开源工具,允许通 ...
- 万恶之源 - Python函数进阶
函数参数-动态参数 之前我们说过传参,如果我们在传参数的时候不很清楚有哪些的时候,或者说给一个函数传了很多参数,我们就要写很多,很麻烦怎么办呢,我们可以考虑使用动态参数 形参的第三种:动态参数 动态参 ...
- bootstrap模态框手动开启关闭与设置点击外部不关闭
http://www.cnblogs.com/qlqwjy/p/7491054.html 完整的参考菜鸟教程:http://www.runoob.com/bootstrap/bootstrap-mod ...
- logstash的各个场景应用(配置文件均已实践过)
场景: 1) datasource->logstash->elasticsearch->kibana 2) datasource->filebeat->logstash- ...
- PAT Counting Leaves[一般]
1004 Counting Leaves (30)(30 分) A family hierarchy is usually presented by a pedigree tree. Your job ...
- mysql 常用命令 常用SQL语句
维护命令 数据库 ##创建数据库 mysql> create database test; Query OK, 1 row affected ##删除数据库 mysql> drop dat ...
- RMAN备份与恢复实践(转)
1 RMAN备份与恢复实践 1.1 备份 1.1.1 对数据库进行全备 使用backup database命令执行备份 RMAN> BACKUP DATABASE; 执行上述命令后将对目标 ...
- 172. Factorial Trailing Zeroes(阶乘中0的个数 数学题)
Given an integer n, return the number of trailing zeroes in n!. Example 1: Input: 3 Output: 0 Explan ...