Group Normalization
Group Normalization
FAIR 团队,吴育昕和恺明大大的新作Group Normalization。

主要的优势在于,BN会受到batchsize大小的影响。如果batchsize太小,算出的均值和方差就会不准确,如果太大,显存又可能不够用。
而GN算的是channel方向每个group的均值和方差,和batchsize没关系,自然就不受batchsize大小的约束。
从上图可以看出,随着batchsize的减小,GN的表现基本不受影响,而BN的性能却越来越差。
BatchNorm基础:
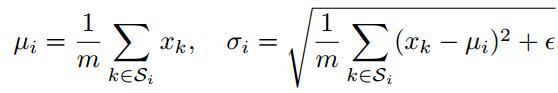
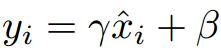
其中u为均值,seigema为方差,实际训练中使用指数滑动平均EMA计算。
gamma为scale值,beta为shift值
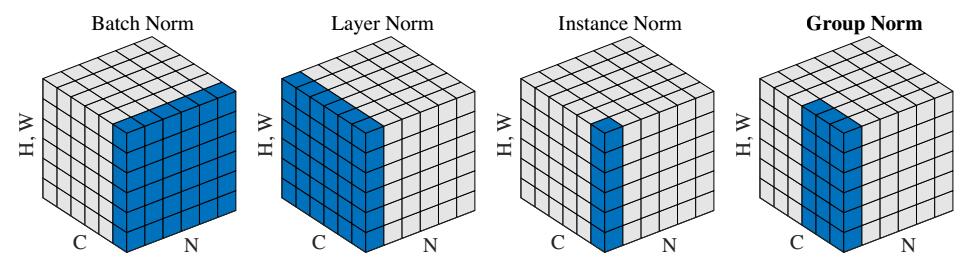
BatchNorm:batch方向做归一化,算N*H*W的均值
LayerNorm:channel方向做归一化,算C*H*W的均值
InstanceNorm:一个channel内做归一化,算H*W的均值
GroupNorm:将channel方向分group,然后每个group内做归一化,算(C//G)*H*W的均值
Tensorflow代码:
- def GroupNorm(x,G=16,eps=1e-5):
- N,H,W,C=x.shape
- x=tf.reshape(x,[tf.cast(N,tf.int32),tf.cast(H,tf.int32),tf.cast(W,tf.int32),tf.cast(G,tf.int32),tf.cast(C//G,tf.int32)])
- mean,var=tf.nn.moments(x,[1,2,4],keep_dims=True)
- x=(x-mean)/tf.sqrt(var+eps)
- x=tf.reshape(x,[tf.cast(N,tf.int32),tf.cast(H,tf.int32),tf.cast(W,tf.int32),tf.cast(C,tf.int32)])
- gamma = tf.Variable(tf.ones(shape=[1,1,1,tf.cast(C,tf.int32)]), name="gamma")
- beta = tf.Variable(tf.zeros(shape=[1,1,1,tf.cast(C,tf.int32)]), name="beta")
- return x*gamma+beta
References:
https://www.zhihu.com/question/269576836/answer/348670955
https://github.com/taokong/group_normalization
https://github.com/shaohua0116/Group-Normalization-Tensorflow
Group Normalization的更多相关文章
- Group Normalization笔记
作者:Yuxin,Wu Kaiming He 机构:Facebook AI Research (FAIR) 摘要:BN是深度学习发展中的一个里程碑技术,它使得各种网络得以训练.然而,在batch维度上 ...
- Batch Normalization、Layer Normalization、Instance Normalization、Group Normalization、Switchable Normalization比较
深度神经网络难训练一个重要的原因就是深度神经网络涉及很多层的叠加,每一层的参数变化都会导致下一层输入数据分布的变化,随着层数的增加,高层输入数据分布变化会非常剧烈,这就使得高层需要不断适应低层的参数更 ...
- 全面解读Group Normalization,对比BN,LN,IN
前言 Face book AI research(FAIR)吴育昕-何恺明联合推出重磅新作Group Normalization(GN),提出使用Group Normalization 替代深度学习里 ...
- (转载)深度剖析 | 可微分学习的自适配归一化 (Switchable Normalization)
深度剖析 | 可微分学习的自适配归一化 (Switchable Normalization) 作者:罗平.任家敏.彭章琳 编写:吴凌云.张瑞茂.邵文琪.王新江 转自:知乎.原论文参考arXiv:180 ...
- 扫盲记-第六篇--Normalization
深度学习模型中的Normalization 数据经过归一化和标准化后可以加快梯度下降的求解速度,这就是Batch Normalization等技术非常流行的原因,Batch Normalization ...
- 『计算机视觉』各种Normalization层辨析
『教程』Batch Normalization 层介绍 知乎:详解深度学习中的Normalization,BN/LN/WN 一.两个概念 独立同分布(independent and identical ...
- 深度学习中的Normalization模型
Batch Normalization(简称 BN)自从提出之后,因为效果特别好,很快被作为深度学习的标准工具应用在了各种场合.BN 大法虽然好,但是也存在一些局限和问题,诸如当 BatchSize ...
- bn两个参数的计算以及layer norm、instance norm、group norm
bn一般就在conv之后并且后面再接relu 1.如果输入feature map channel是6,bn的gamma beta个数是多少个? 6个. 2.bn的缺点: BN会受到batchsize大 ...
- [优化]深度学习中的 Normalization 模型
来源:https://www.chainnews.com/articles/504060702149.htm 机器之心专栏 作者:张俊林 Batch Normalization (简称 BN)自从提出 ...
随机推荐
- 【Unity】4.0 第4章 创建基本的游戏场景
分类:Unity.C#.VS2015 创建日期:2016-04-05 一.简介 上一章我们学习了如何利用长方体(Cube)制作基本的3D模型,以及如何导入各种资源,本章将在此基础上,分别制作路面.跳板 ...
- lua -- 商店的数据管理类
module (..., package.seeall) local ShopM = {} local SystemPrompt = require(__APP_PACKAGE_NAME__ .. & ...
- Google MapReduce到底解决什么问题?
很多时候,定义清楚问题比解决问题更难. 什么是MapReduce? 它不是一个产品,而是一种解决问题的思路,它有多个工程实现,Google在论文中也给出了它自己的工程架构实现. MapReduce这个 ...
- 【FastDFS】FastDFS在CentOS的搭建
准备安装软件 [root@blog third_package]# cp fastdfs-nginx-module_v1.16.tar.gz FastDFS_v5.08.tar.gz libfastc ...
- 兼容ios和Android的复制js代码
//2种方法本人全部亲测有效 方法1:比较简单 <!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN" ...
- kindeditor自定义插件插入视频代码
kindeditor自定义插件插入视频代码 1.添加插件js 目录:/kindeditor/plugins/diy_video/diy_video.js KindEditor.plugin('diy_ ...
- SQLite区分大小写查询
http://www.cnblogs.com/zhuawang/archive/2013/01/15/2861566.html 大部分数据库在进行字符串比较的时候,对大小写是不敏感的.但是,在SQLi ...
- STM32——项目需求之低功耗的停机模式
在说低功耗之前,先要明白一个东西,那就是stm32中的事件和中断. 事件是中断的触发源,开放了对应的中断屏蔽位,则事件可以触发相应的中断.在STM32中,中断与事件不是等价的,一个中断肯定对应一个事件 ...
- 未能加载文件或程序集“System.Web.Mvc, Version=3.0.0.0,
直接下载安装 ASP.NET MVC 3.0就可以了
- JedisConnectionPool scala
/** * Created by lq on 2017/8/29. */ object JedisConnectionPool { val config = new JedisPoolConfig() ...