xgboost入门与实战
xgboost入门与实战(实战调参篇)
https://blog.csdn.net/sb19931201/article/details/52577592
前言
前面几篇博文都在学习原理知识,是时候上数据上模型跑一跑了。本文用的数据来自kaggle,相信搞机器学习的同学们都知道它,kaggle上有几个老题目一直开放,适合给新手练级,上面还有很多老司机的方案共享以及讨论,非常方便新手入门。这次用的数据是Classify handwritten digits using the famous MNIST data—手写数字识别,每个样本相当于一个图片像素矩阵(28x28),每个像元就是一个特征啦。用这个数据的好处就是不用做特征工程了,对于上手模型很方便。
xgboost安装看这里:http://blog.csdn.net/sb19931201/article/details/52236020
拓展一下:XGBoost Plotting API以及GBDT组合特征实践
数据集
1.数据介绍:数据采用的是广泛应用于机器学习社区的MNIST数据集:

The data for this competition were taken from the MNIST dataset. The MNIST (“Modified National Institute of Standards and Technology”) dataset is a classic within the Machine Learning community that has been extensively studied. More detail about the dataset, including Machine Learning algorithms that have been tried on it and their levels of success, can be found at http://yann.lecun.com/exdb/mnist/index.html.
2.训练数据集(共42000个样本):如下图所示,第一列是label标签,后面共28x28=784个像素特征,特征取值范围为0-255。


3.测试数据集(共28000条记录):就是我们要预测的数据集了,没有标签值,通过train.csv训练出合适的模型,然后根据test.csv的特征数据集来预测这28000的类别(0-9的数字标签)。

4.结果数据样例:两列,一列为ID,一列为预测标签值。 
xgboost模型调参、训练(python)
1.导入相关库,读取数据
import numpy as np
import pandas as pd
import xgboost as xgb
from sklearn.cross_validation import train_test_split
#记录程序运行时间
import time
start_time = time.time()
#读入数据
train = pd.read_csv("Digit_Recognizer/train.csv")
tests = pd.read_csv("Digit_Recognizer/test.csv") 2.划分数据集
#用sklearn.cross_validation进行训练数据集划分,这里训练集和交叉验证集比例为7:3,可以自己根据需要设置
train_xy,val = train_test_split(train, test_size = 0.3,random_state=1)
y = train_xy.label
X = train_xy.drop(['label'],axis=1)
val_y = val.label
val_X = val.drop(['label'],axis=1)
#xgb矩阵赋值
xgb_val = xgb.DMatrix(val_X,label=val_y)
xgb_train = xgb.DMatrix(X, label=y)
xgb_test = xgb.DMatrix(tests)3.xgboost模型
params={
'booster':'gbtree',
'objective': 'multi:softmax', #多分类的问题
'num_class':10, # 类别数,与 multisoftmax 并用
'gamma':0.1, # 用于控制是否后剪枝的参数,越大越保守,一般0.1、0.2这样子。
'max_depth':12, # 构建树的深度,越大越容易过拟合
'lambda':2, # 控制模型复杂度的权重值的L2正则化项参数,参数越大,模型越不容易过拟合。
'subsample':0.7, # 随机采样训练样本
'colsample_bytree':0.7, # 生成树时进行的列采样
'min_child_weight':3,
# 这个参数默认是 1,是每个叶子里面 h 的和至少是多少,对正负样本不均衡时的 0-1 分类而言
#,假设 h 在 0.01 附近,min_child_weight 为 1 意味着叶子节点中最少需要包含 100 个样本。
#这个参数非常影响结果,控制叶子节点中二阶导的和的最小值,该参数值越小,越容易 overfitting。
'silent':0 ,#设置成1则没有运行信息输出,最好是设置为0.
'eta': 0.007, # 如同学习率
'seed':1000,
'nthread':7,# cpu 线程数
#'eval_metric': 'auc'
}
plst = list(params.items())
num_rounds = 5000 # 迭代次数
watchlist = [(xgb_train, 'train'),(xgb_val, 'val')]
#训练模型并保存
# early_stopping_rounds 当设置的迭代次数较大时,early_stopping_rounds 可在一定的迭代次数内准确率没有提升就停止训练
model = xgb.train(plst, xgb_train, num_rounds, watchlist,early_stopping_rounds=100)
model.save_model('./model/xgb.model') # 用于存储训练出的模型
print "best best_ntree_limit",model.best_ntree_limit 4.预测并保存
preds = model.predict(xgb_test,ntree_limit=model.best_ntree_limit)
np.savetxt('xgb_submission.csv',np.c_[range(1,len(tests)+1),preds],delimiter=',',header='ImageId,Label',comments='',fmt='%d')
#输出运行时长
cost_time = time.time()-start_time
print "xgboost success!",'\n',"cost time:",cost_time,"(s)......"
5.变量信息
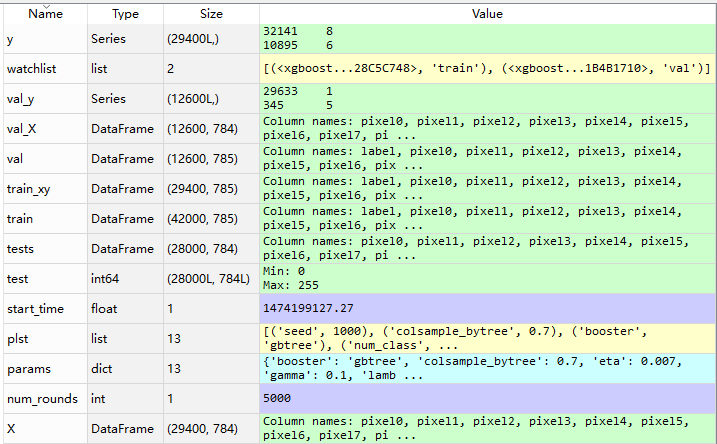
预测结果评价
将预测得到的xgb_submission.csv文件上传到kaggle,看系统评分。
由于迭代次数和树的深度设置的都比较大,程序还在训练中,等这次跑完在将这两个参数调整小一些,看看运行时间已经预测精度的变化。
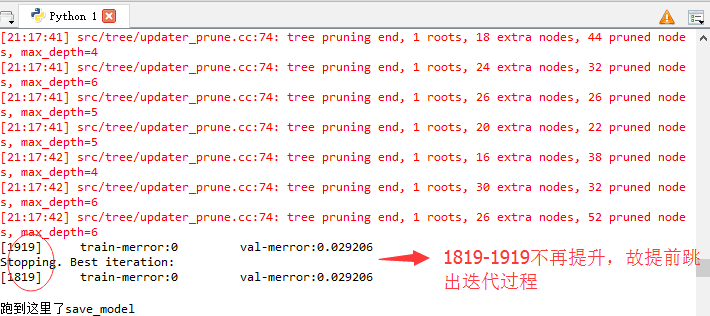
此处先留个坑。。。不同版本的运行结果我会陆续贴出来。
版本:1 运行时长:中间程序报错了一下,大概是2500s
参数:

成绩:

版本:2 运行时长:2275s
参数:

成绩:
.
.
.
结

果
图
片
.
.
.
附:完整代码
#coding=utf-8
"""
Created on 2016/09/17
By 我曾经被山河大海跨过
"""
import numpy as np
import pandas as pd
import xgboost as xgb
from sklearn.cross_validation import train_test_split
#from xgboost.sklearn import XGBClassifier
#from sklearn import cross_validation, metrics #Additional scklearn functions
#from sklearn.grid_search import GridSearchCV #Perforing grid search
#
#import matplotlib.pylab as plt
#from matplotlib.pylab import rcParams
#记录程序运行时间
import time
start_time = time.time()
#读入数据
train = pd.read_csv("Digit_Recognizer/train.csv")
tests = pd.read_csv("Digit_Recognizer/test.csv")
params={
'booster':'gbtree',
'objective': 'multi:softmax', #多分类的问题
'num_class':10, # 类别数,与 multisoftmax 并用
'gamma':0.1, # 用于控制是否后剪枝的参数,越大越保守,一般0.1、0.2这样子。
'max_depth':12, # 构建树的深度,越大越容易过拟合
'lambda':2, # 控制模型复杂度的权重值的L2正则化项参数,参数越大,模型越不容易过拟合。
'subsample':0.7, # 随机采样训练样本
'colsample_bytree':0.7, # 生成树时进行的列采样
'min_child_weight':3,
# 这个参数默认是 1,是每个叶子里面 h 的和至少是多少,对正负样本不均衡时的 0-1 分类而言
#,假设 h 在 0.01 附近,min_child_weight 为 1 意味着叶子节点中最少需要包含 100 个样本。
#这个参数非常影响结果,控制叶子节点中二阶导的和的最小值,该参数值越小,越容易 overfitting。
'silent':0 ,#设置成1则没有运行信息输出,最好是设置为0.
'eta': 0.007, # 如同学习率
'seed':1000,
'nthread':7,# cpu 线程数
#'eval_metric': 'auc'
}
plst = list(params.items())
num_rounds = 5000 # 迭代次数
train_xy,val = train_test_split(train, test_size = 0.3,random_state=1)
#random_state is of big influence for val-auc
y = train_xy.label
X = train_xy.drop(['label'],axis=1)
val_y = val.label
val_X = val.drop(['label'],axis=1)
xgb_val = xgb.DMatrix(val_X,label=val_y)
xgb_train = xgb.DMatrix(X, label=y)
xgb_test = xgb.DMatrix(tests)
watchlist = [(xgb_train, 'train'),(xgb_val, 'val')]
# training model
# early_stopping_rounds 当设置的迭代次数较大时,early_stopping_rounds 可在一定的迭代次数内准确率没有提升就停止训练
model = xgb.train(plst, xgb_train, num_rounds, watchlist,early_stopping_rounds=100)
model.save_model('./model/xgb.model') # 用于存储训练出的模型
print "best best_ntree_limit",model.best_ntree_limit
print "跑到这里了model.predict"
preds = model.predict(xgb_test,ntree_limit=model.best_ntree_limit)
np.savetxt('xgb_submission.csv',np.c_[range(1,len(tests)+1),preds],delimiter=',',header='ImageId,Label',comments='',fmt='%d')
#输出运行时长
cost_time = time.time()-start_time
print "xgboost success!",'\n',"cost time:",cost_time,"(s)"xgboost入门与实战的更多相关文章
- xgboost入门与实战(原理篇)
sklearn实战-乳腺癌细胞数据挖掘 https://study.163.com/course/introduction.htm?courseId=1005269003&utm_campai ...
- xgboost入门与实战(实战调参篇)
https://blog.csdn.net/sb19931201/article/details/52577592 xgboost入门与实战(实战调参篇) 前言 前面几篇博文都在学习原理知识,是时候上 ...
- 赞一个 kindle电子书有最新的计算机图书可买了【Docker技术入门与实战】
最近对docker这个比较感兴趣,找一个比较完整的书籍看看,在z.cn上找到了电子书,jd dangdang看来要加油啊 Docker技术入门与实战 [Kindle电子书] ~ 杨保华 戴王剑 曹亚仑 ...
- docker-9 supervisord 参考docker从入门到实战
参考docker从入门到实战 使用 Supervisor 来管理进程 Docker 容器在启动的时候开启单个进程,比如,一个 ssh 或者 apache 的 daemon 服务.但我们经常需要在一个机 ...
- webpack入门和实战(一):webpack配置及技巧
一.全面理解webpack 1.什么是 webpack? webpack是近期最火的一款模块加载器兼打包工具,它能把各种资源,例如JS(含JSX).coffee.样式(含less/sass).图片等都 ...
- CMake快速入门教程-实战
http://www.ibm.com/developerworks/cn/linux/l-cn-cmake/ http://blog.csdn.net/dbzhang800/article/detai ...
- Sping Boot入门到实战之入门篇(三):Spring Boot属性配置
该篇为Sping Boot入门到实战系列入门篇的第三篇.介绍Spring Boot的属性配置. 传统的Spring Web应用自定义属性一般是通过添加一个demo.properties配置文件(文 ...
- Sping Boot入门到实战之入门篇(二):第一个Spring Boot应用
该篇为Spring Boot入门到实战系列入门篇的第二篇.介绍创建Spring Boot应用的几种方法. Spring Boot应用可以通过如下三种方法创建: 通过 https://start.spr ...
- Sping Boot入门到实战之入门篇(一):Spring Boot简介
该篇为Spring Boot入门到实战系列入门篇的第一篇.对Spring Boot做一个大致的介绍. 传统的基于Spring的Java Web应用,需要配置web.xml, applicationCo ...
随机推荐
- Linux学习笔记08—如何关闭防火墙
Linux系统下面自带了防火墙iptables,iptables可以设置很多安全规则.但是如果配置错误很容易导致各种网络问题,那么如果要关闭禁用防火墙怎么操作呢,咗嚛本经验以centos系统为例演示如 ...
- javascript区域打印代码
这段代码是我从Highcharts的代码中改造出来的,非常感谢Highcharts的作者,先链上Highcharts的地址http://www.highcharts.com/,(Highcharts的 ...
- IDA .edata .rdata .idata .text segments
.rdata is for const data. It is the read only version of the .data segment. .idata holds the import ...
- 读写分离,读写分离死锁解决方案,事务发布死锁解决方案,发布订阅死锁解决方案|事务(进程 ID *)与另一个进程被死锁在 锁 资源上,并且已被选作死锁牺牲品。请重新运行该事务
前言: 由于网站访问压力的问题,综合分析各种因素后结合实际情况,采用数据库读写分离模式来解决当前问题.实际方案中采用“事务发布”模式实现主数据库和只读数据库的同步,其中: 发布服务器1 ...
- python dtrace 安装与应用
https://ipfans.github.io/2016/09/tracing-python-program-with-dtrace/?utm_source=tuicool&utm_medi ...
- Lex与Yacc学习
http://www.cnblogs.com/shine-yr/p/5214976.html
- getsockname()/getpeername()函数第一次被调用得到0.0.0.0结果
int getsockname(int sockfd, struct sockaddr *addr, socklen_t *addrlen); getsockname() returns the cu ...
- linux socket编程示例
#include <sys/socket.h> #include <netinet/in.h> #include <arpa/inet.h> #include &l ...
- WinForm基于插件开发实现多项配置存储
一.课程介绍和实例在线演示 明人不说暗话,跟着阿笨一起玩WinForm.本次分享课程属于<C#高级编程实战技能开发宝典课程系列>中的一部分,阿笨后续会计划将实际项目中的一些比较实用的关于C ...
- Creating popup windows in XBAP applications
A colleague at DevelopMentor recently asked me about creating popup windows in XAML browser applicat ...