bed文件格式解读
1)BED文件
BED 文件(Browser Extensible Data)格式是ucsc 的genome browser的一个格式 ,提供了一种灵活的方式来定义的数据行,以用来描述注释信息。BED行有3个必须的列和9个额外可选的列。每行的数据格式要求一致(见下图)。 每条线的字段数目必须是任意单条数据的在注释上一致。
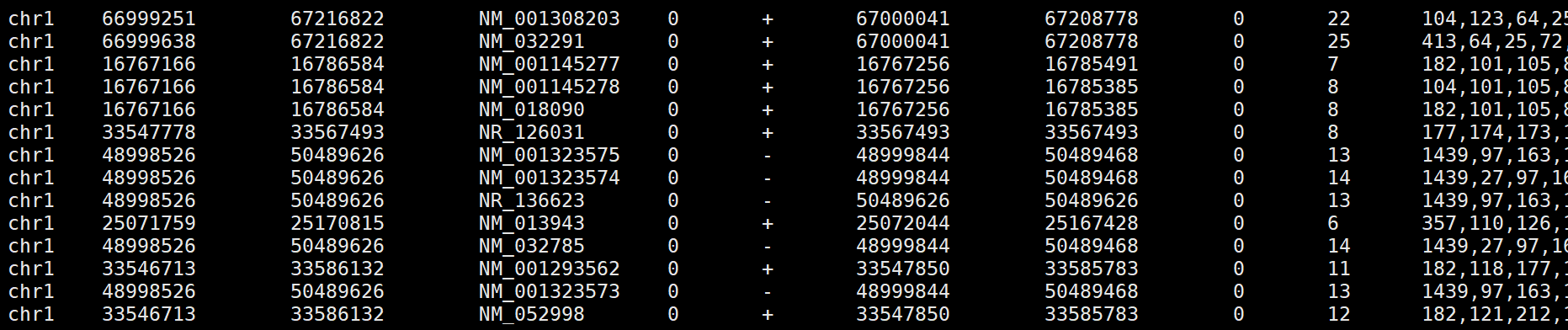
BED文件结构:
-------------------------------------------------------------必须有以下3列------------------------------------------------------------------------
chrom :即染色体号
chromStart :即feature在染色体上起始位置 。在染色体上最左端坐标是0
chromEnd :即feature在染色体上的终止位置。例如一个染色体前100个碱基定义为chromStart=0, chromEnd=100, 跨度为 0-99.
----------------------------------------------------------------可选9列-------------------------------------------------------------------------------
name :feature的名字 ,在基因组浏览器左边显示;
score :在基因组浏览器中显示的灰度设定,值介于0-1000;

strand :定义链的方向,''+” 或者”-”
thickStart :起始位置(例如,基因起始编码位置)
thickEnd :终止位置(例如:基因终止编码位置)
itemRGB :是一个RGB值的形式, R, G, B (eg. 255, 0,0), 如果itemRgb设置为'On”, 这个RBG值将决定数据的显示的颜色。
blockCount :BED行中的block数目,也就是外显子数目
blockSize:用逗号分割的外显子的大小, 这个item的数目对应于BlockCount的数目
blockStarts :用逗号分割的列表, 所有外显子的起始位置,数目也与blockCount数目对应
2)bed和gff之间的关系
前面已经讲过GFF格式,用UCSC Genome Browser可以将两者进行可视化比较。 Bed文件和GFF文件最基本的信息就是染色体或Contig的ID或编号,然后就是DNA的正负链信息,接着就是在染色体上的起始和终止位置数值。
两种文件的区别在于,BED文件中起始坐标为0,结束坐标至少是1;GFF中起始坐标是1而结束坐标至少是1。
3)习题
3.1)bed文件的全称是什么
3.2)bed文件有几列?
3.3)bed 文件染色体最左端坐标是从几开始?
3.4)如何设置界面灰度信息?
3.5)如何给track显示不同的颜色
3.6)bed和gff文件有什么区别?
3.7)bed文件默认是以什么分割?
3.8)bed文件如何可视化
3.9)如果你的bed文件太大,你将会如何操作?
3.10)bed文件能够与其它文件进行格式转化?
3.11)查看test.bed文件中有多少条染色体
3.12)找出所有genome feature在染色体中的最左端起始位置
3.13)找出所有genome feature在染色体中的最右端终止的位置
3.14)输出feture在染色体上跨度最大的长度
3.15)计算在1号染色体33546713-50489626位置间有多少feature
3.16)显示最高的灰度值
3.17) 展示所有位于正链上的行
3.18)展示负链上最长的feture特征
3.19)查看用了多少不同的颜色值(即RGB值)
3.20)显示正链上最长的基因所用的颜色
4) 参考资源
http://www.360doc.com/content/18/0329/22/19913717_741376781.shtml
https://blog.csdn.net/herokoking/article/details/79276513
https://genome.ucsc.edu/FAQ/FAQformat.html#format1
bed文件格式解读的更多相关文章
- Log4cpp配置文件格式说明
Log4cpp配置文件格式说明 博客分类: log4cpp log4cpp log4cpp有3个主要的组件:categories(类别).appenders(附加目的地).和 layouts(布局) ...
- lucene文件格式待整理
这是之前Lucene3.0生成的索引格式 a表
- lucene学习笔记:三,Lucene的索引文件格式
Lucene的索引里面存了些什么,如何存放的,也即Lucene的索引文件格式,是读懂Lucene源代码的一把钥匙. 当我们真正进入到Lucene源代码之中的时候,我们会发现: Lucene的索引过程, ...
- Lucene学习总结之三:Lucene的索引文件格式(1)
Lucene的索引里面存了些什么,如何存放的,也即Lucene的索引文件格式,是读懂Lucene源代码的一把钥匙. 当我们真正进入到Lucene源代码之中的时候,我们会发现: Lucene的索引过程, ...
- [解读REST] 5.Web的需求 & 推导REST
衔接上文[解读REST] 4.基于网络应用的架构风格,上文总结了一些适用于基于网络应用的架构风格,以及其评估结果.在前文的基础上,本文介绍一下Web架构的需求,以及在对Web的关键协议进行设计和改进的 ...
- [一]class 文件浅析 .class文件格式详解 字段方法属性常量池字段 class文件属性表 数据类型 数据结构
前言概述 本文旨在讲解class文件的整体结构信息,阅读本文后应该可以完整的了解class文件的格式以及各个部分的逻辑组成含义 class文件包含了java虚拟机指令集 和 符号表 以及若 ...
- 比起Windows,怎样解读Linux的文件系统与目录结构?
比起Windows,怎样解读Linux的文件系统与目录结构? Linux 和Windows的文件系统有些不同,在学习使用 Linux 之前,若能够了解这些不同,会有助于后续学习. 本文先对Window ...
- OS Tools-GO富集分析工具的使用与解读详细教程
我们的云平台上的GO富集分析工具,需要输入的文件表格和参数很简单,但很多同学都不明白其中的原理与结果解读,这个帖子就跟大家详细解释~ 一.GO富集介绍: Gene Ontology(简称G ...
- MP4文件格式
MP4文件格式详解(ISO-14496-12/14) Author:Pirate Leo Email:codeevoship@gmail.com 一.基本概念 1. 文件,由许多Box和FullBox ...
随机推荐
- React-Native 在android写不支持gif的解决方案!
只需要在android/app/build.gradle中的dependencies字段中添加: compile 'com.facebook.fresco:animated-gif:0.13.0' 然 ...
- R语言学习——输入与输出
导入数据: grades<-read.table("D:/ProgramData/test1.txt",sep="\t") 求均值:mean() 求方差: ...
- vcenter修改用户密码的方法
https://192.168.x.x:9443登录,必须用administrator@vsphere.local登录,不能用root用户登录. 主页-系统设置- Single Sing-On-用户和 ...
- python的return self的用法
转载:https://blog.csdn.net/jclian91/article/details/81238782 class foo: def __init__(self): self.m = 0 ...
- Chrome 鼠标左键-新标签打开
改chrome设置 1.打开google搜索主页2.打开右下角Settings选项->Search Settings3.找到where results open选项4.把Open each se ...
- 运行inetmgr提示“找不到文件”无法打开IIS管理器的解决办法
运行inetmgr提示“找不到文件”无法打开IIS管理器的解决办法 不知道什么时候开始运行inetmgr就提示找不到文件了,本以为是IIS坏了,这两天发现IIS服务还是可以运行的,只是运行inetmg ...
- 【Python编程:从入门到实践】chapter8 函数
chapter8 函数 8.6 将函数存储在模块中 8.6.1 导入整个模块 要让函数是可导入的,的先创建模块.模块 的扩展名为.py的文件 import pizza 8.6.2 到导入特定的函数 f ...
- 目前学习的爬取小数据图片zzz
import os import threading import re import time from lxml import etree all_img_urls = [] # 图片列表页面的数 ...
- Tensorflow线程和队列
读取数据 小数量数据读取 这仅用于可以完全加载到存储器中的小的数据集有两种方法: 存储在常数中. 存储在变量中,初始化后,永远不要改变它的值. 使用常数更简单一些,但是会使用更多的内存,因为常数会内联 ...
- angularjs 整合 bootstrap
第一步 :下载 bootstrap jquery ppper.js npm install bootstrap@4.0.0-beta.2 jquery popper.js --save 第二步: ...