[SQL Server 2014] SQL Server 2014新特性探秘
简介
SQL Server 2014提供了众多激动人心的新功能,但其中我想最让人期待的特性之一就要算内存数据库了。去年我再西雅图参加SQL PASS Summit 2012的开幕式时,微软就宣布了将在下一个SQL Server版本中附带代号为Hekaton的内存数据库引擎。现在随着2014CTP1的到来,我们终于可以一窥其面貌。
内存数据库
在传统的数据库表中,由于磁盘的物理结构限制,表和索引的结构为B-Tree,这就使得该类索引在大并发的OLTP环境中显得非常乏力,虽然有很多办法来解决这类问题,比如说乐观并发控制,应用程序缓存,分布式等。但成本依然会略高。而随着这些年硬件的发展,现在服务器拥有几百G内存并不罕见,此外由于NUMA架构的成熟,也消除了多CPU访问内存的瓶颈问题,因此内存数据库得以出现。
内存的学名叫做Random Access Memory(RAM),因此如其特性一样,是随机访问的,因此对于内存,对应的数据结构也会是Hash-Index,而并发的隔离方式也对应的变成了MVCC,因此内存数据库可以在同样的硬件资源下,Handle更多的并发和请求,并且不会被锁阻塞,而SQL Server 2014集成了这个强大的功能,并不像Oracle的TimesTen需要额外付费,因此结合SSD AS Buffer Pool特性,所产生的效果将会非常值得期待。
SQL Server内存数据库的表现形式
在SQL Server的Hekaton引擎由两部分组成:内存优化表和本地编译存储过程。虽然Hekaton集成进了关系数据库引擎,但访问他们的方法对于客户端是透明的,这也意味着从客户端应用程序的角度来看,并不会知道Hekaton引擎的存在。如图1所示。

图1.客户端APP不会感知Hekaton引擎的存在
首先内存优化表完全不会再存在锁的概念(虽然之前的版本有快照隔离这个乐观并发控制的概念,但快照隔离仍然需要在修改数据的时候加锁),此外内存优化表Hash-Index结构使得随机读写的速度大大提高,另外内存优化表可以设置为非持久内存优化表,从而也就没有了日志(适合于ETL中间结果操作,但存在数据丢失的危险)
下面我们来看创建一个内存优化表:
首先,内存优化表需要数据库中存在一个特殊的文件组,以供存储内存优化表的CheckPoint文件,与传统的mdf或ldf文件不同的是,该文件组是一个目录而不是一个文件,因为CheckPoint文件只会附加,而不会修改,如图2所示。

图2.内存优化表所需的特殊文件组
我们再来看一下内存优化文件组的样子,如图3所示。

图3.内存优化文件组
有了文件组之后,接下来我们创建一个内存优化表,如图4所示。

图4.创建内存优化表
目前SSMS还不支持UI界面创建内存优化表,因此只能通过T-SQL来创建内存优化表,如图5所示。

图5.使用代码创建内存优化表
当表创建好之后,就可以查询数据了,值得注意的是,查询内存优化表需要snapshot隔离等级或者hint,这个隔离等级与快照隔离是不同的,如图6所示。

图6.查询内存优化表需要加提示
此外,由创建表的语句可以看出,目前SQL Server 2014内存优化表的Hash Index只支持固定的Bucket大小,不支持动态分配Bucket大小,因此这里需要注意。
与内存数据库不兼容的特性
目前来说,数据库镜像和复制是无法与内存优化表兼容的,但AlwaysOn,日志传送,备份还原是完整支持。
性能测试
上面扯了一堆理论,大家可能都看郁闷了。下面我来做一个简单的性能测试,来比对使用内存优化表+本地编译存储过程与传统的B-Tree表进行对比,B-Tree表如图7所示,内存优化表+本地编译存储过程如图8所示。

图7.传统的B-Tree表

图8.内存优化表+本地编译存储过程
因此不难看出,内存优化表+本地编译存储过程有接近几十倍的性能提升。
SQL Server 2014新特性探秘(2)-SSD Buffer Pool Extension
简介
SQL Server 2014中另一个非常好的功能是,可以将SSD虚拟成内存的一部分,来供SQL Server数据页缓冲区使用。通过使用SSD来扩展Buffer-Pool,可以使得大量随机的IOPS由SSD来承载,从而大量减少对于数据页的随机IOPS和PAGE-OUT。
SSD AS Buffer Pool
SSD是固态硬盘,不像传统的磁盘有磁头移动的部分,因此随机读写的IOPS远远大于传统的磁盘。将SSD作为Buffer Pool的延伸,就可以以非常低的成本巨量的扩充内存。而传统的模式是内存只能容纳下热点数据的一小部分,从而造成比较大的Page-Out,如图1所示。
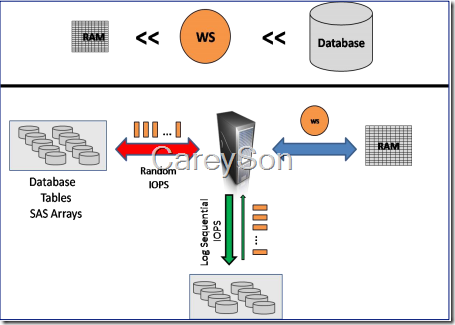
图1.大量随机的IOPS需要由磁盘阵列所承担
但如果考虑到将SSD加入计算机的存储体系,那么内存可以以非常低的成本扩展到约等于热点数据,不仅仅是提升了性能,还可以减少IO成本,如图2所示。
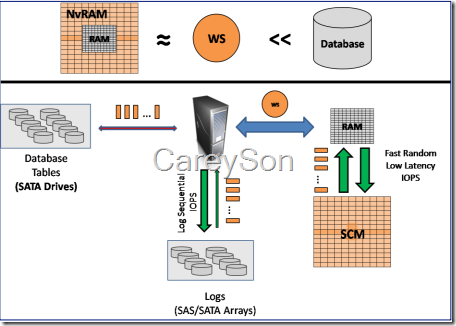
图2.扩展后内存几乎能HOLD所有热点数据
由图1和图2的对比可以看出,扩展后可以使用更便宜的SATA存储。此外,该特性是透明的,无需应用程序端做任何的改变。
此外,该特性为了避免数据的丢失,仅仅在作为缓冲区的SSD中存储Buffer Pool的Clean Page,即使SSD出现问题,也只需要从辅助存储中Page In页即可。
最后,该特性对于NUMA进行了特别优化,即使拥有超过8个Socket的系统,CPU也能无障碍的访问内存。
启用BUFFER Pool Extension
在SQL Server 2014总,启用Buffer Pool Extension非常简单,仅仅需要拥有SysAdmin权限后,输入一个T-SQL语句即可,如图3所示。
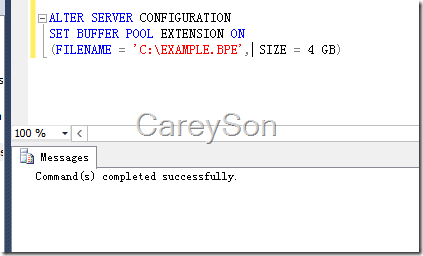
图3.启用Buffer Pool Extension
对应的,我们可以在物理磁盘中看到这个扩展文件,该文件的性能和Windows的虚拟内存文件非常类似,如图4所示。
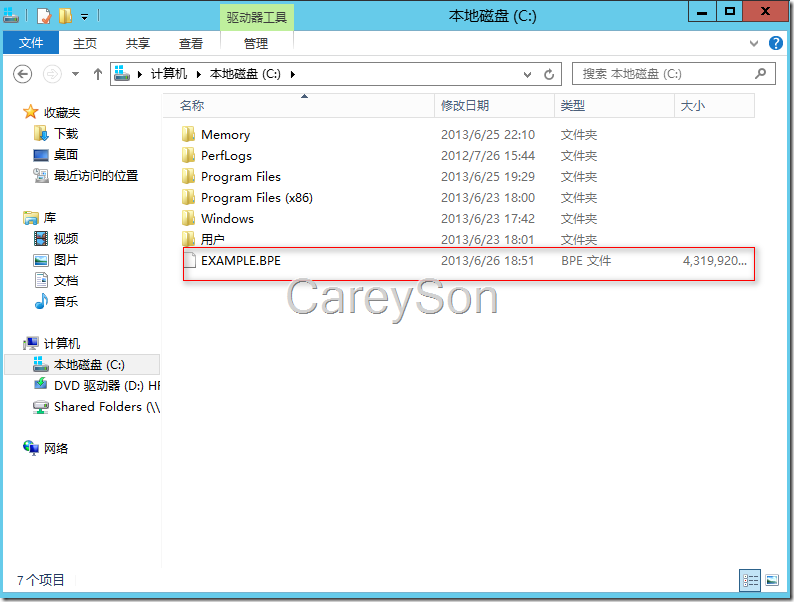
图4.对应的Buffer Pool扩展文件
但这里值得注意的是,我们启用的内存扩展无法小于物理内存或阈值,否则会报错,如图5所示。
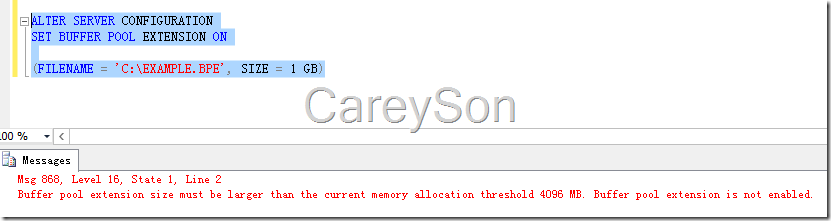
图5.报错信息
对于该功能,SQL Server引入了一个全新的DMV和在原有的DMV上加了一列,来描述Buffer Pool Extention,如图6所示。
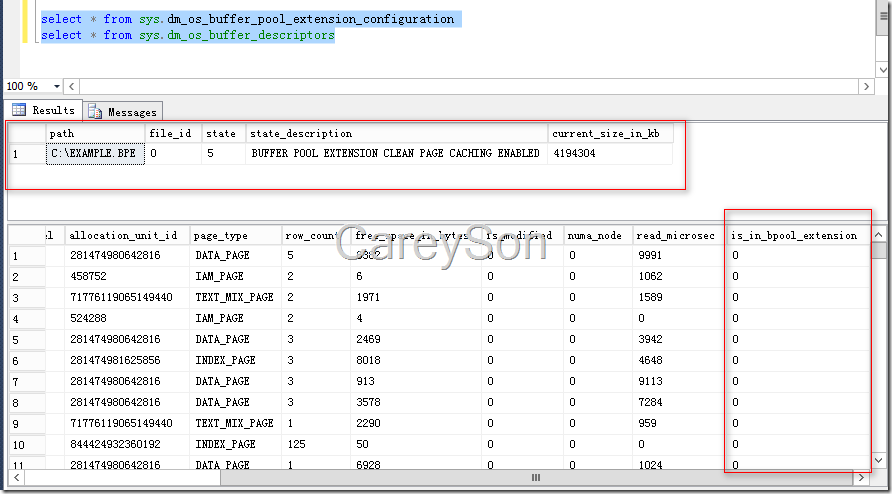
图6.引入的新的DMV和对于原有DMV的更新
此外,对于该特性的监控,SQL Server还引入了大量与之相关的计数器,如图7所示。
图7.相关计数器
小结
SQL Server Buffer Pool Extension给我们提供了以更低成本来满足更高企业级需求的可能,结合内存数据库,未来的可能性将无限延伸。
[SQL Server 2014] SQL Server 2014新特性探秘的更多相关文章
- SQL Server 2014新特性探秘(1)-内存数据库
简介 SQL Server 2014提供了众多激动人心的新功能,但其中我想最让人期待的特性之一就要算内存数据库了.去年我再西雅图参加SQL PASS Summit 2012的开幕式时,微软就宣布 ...
- SQL Server 2014新特性探秘(2)-SSD Buffer Pool Extension
简介 SQL Server 2014中另一个非常好的功能是,可以将SSD虚拟成内存的一部分,来供SQL Server数据页缓冲区使用.通过使用SSD来扩展Buffer-Pool,可以使得大量随 ...
- SQL Server 2014新特性探秘(3)-可更新列存储聚集索引
简介 列存储索引其实在在SQL Server 2012中就已经存在,但SQL Server 2012中只允许建立非聚集列索引,这意味着列索引是在原有的行存储索引之上的引用了底层的数据,因此会 ...
- SQL Server 2014新特性——Buffer Pool扩展
Buffer Pool扩展 Buffer Pool扩展是buffer pool 和非易失的SSD硬盘做连接.以SSD硬盘的特点来提高随机读性能. 缓冲池扩展优点 SQL Server读以随机读为主,S ...
- SQL Server 2014 BI新特性(一)五个关键点带你了解Excel下的Data Explorer
Data Explorer是即将发布的SQL Server 2014里的一个新特性,借助这个特性讲使企业中的自助式的商业智能变得更加的灵活,从而也降低了商业智能的门槛. 此文是在微软商业智能官方博客里 ...
- SQL Server 2014新特性:五个关键点带你了解Excel下的Data Explorer
SQL Server 2014新特性:五个关键点带你了解Excel下的Data Explorer Data Explorer是即将发布的SQL Server 2014里的一个新特性,借助这个特性讲使企 ...
- SQL Server 2008新特性——策略管理
策略管理是SQL Server 2008中的一个新特性,用于管理数据库实例.数据库以及数据库对象的各种属性.策略管理在SSMS的对象资源管理器数据库实例下的“管理”节点下,如图: 从图中可以看到,策略 ...
- atitit.Windows Server 2003 2008 2012系统的新特性 attilax 总结
atitit.Windows Server 2003 2008 2012系统的新特性 attilax 总结 1. Windows Server 2008 新特性也可以归纳为4个方面. 1 2. 相 ...
- sqlserver2014新特性
1.SQL Server 2014新特性探秘(1)-内存数据库 在传统的数据库表中,由于磁盘的物理结构限制,表和索引的结构为B-Tree,这就使得该类索引在大并发的OLTP环境中显得非常乏力,虽然有很 ...
随机推荐
- Arduino驱动无源蜂鸣器发声
tone()函数 tone(pin, frequency) tone(pin, frequency, duration) # 参数 pin: the pin on which to generate ...
- 开源分布式搜索平台ELK(Elasticsearch+Logstash+Kibana)入门学习资源索引
from: http://www.w3c.com.cn/%E5%BC%80%E6%BA%90%E5%88%86%E5%B8%83%E5%BC%8F%E6%90%9C%E7%B4%A2%E5%B9%B ...
- Netty-gRPC介绍和使用
转自:http://www.saily.top/2017/07/23/netty5/ gRPC Define your service using Protocol Buffers, a powerf ...
- 新系统基础优化--Centos6.6
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 3 ...
- 使用java修改图片DPI
修改以后可以直接用PS打开看效果 全部使用rt下的类,无需下载其他jar包 import com.sun.image.codec.jpeg.JPEGCodec; import com.sun.imag ...
- ASP.NET MVC4中的App_start中BundleConfig的介绍使用
在BundleConfig.cs中,指定CSS和JS,主要用来压缩JS和CSS 在ASP.NET MVC4中(在WebForm中应该也有),有一个叫做Bundle的东西,它用来将js和css进行压 ...
- easyui按钮linkbutton 不可用(置灰)与 可用(取消置灰)
easyui linkbutton按钮: 不可用(置灰) $('#butFree').linkbutton('disable'); 可用(取消置灰) $('#butFree').linkbutton( ...
- Linux引导启动程序 - boot
主要描述 boot/目录中的三个汇编代码文件,见列表 3-1 所示.正如在前一章中提到的,这三个 文件虽然都是汇编程序,但却使用了两种语法格式.bootsect.s 和 setup.s 采用近似于 I ...
- [转]IDEA 导出自己的jar包 并且在另一个工程中引用
1.导出jar包 1.1 idea导出jar包不如eclipse方便,但是熟练了也很容易操作 1.2 File -> Project Settings -> Artifacts(艺术品) ...
- java 执行mysql 8.0.11存储过程报错The user specified as a definer ('root'@'10.%.%.%') does not exist解决办法
执行存储过程,报错 java.sql.SQLException: The user specified as a definer ('root'@'10.%.%.%') does not exist ...