HashMap知识点、问题
转载:https://blog.csdn.net/qq_27007251/article/details/71403647
https://www.cnblogs.com/kxdblog/p/4323892.html
HashMap1.7
HashMap1.7出现闭环的原因
问题描述
从前我们的Java代码因为一些原因使用了HashMap这个东西,但是当时的程序是单线程的,一切都没有问题。因为考虑到程序性能,所以需要变成多线程的,于是,变成多线程后到了线上,发现程序经常占了100%的CPU,查看堆栈,你会发现程序都Hang在了HashMap.get()这个方法上了,重启程序后问题消失。但是过段时间又会来。而且,这个问题在测试环境里可能很难重现。简单的看一下我们自己的代码,我们就知道HashMap被多个线程操作。而Java的文档说HashMap是非线程安全的,应该用ConcurrentHashMap。
hash表数据结构
HashMap通常会用一个指针数组(假设为table[])来做分散所有的key,当一个key被加入时,会通过Hash算法通过key算出这个数组的下标i,然后就把这个<key, value>插到table[i]中,如果有两个不同的key被算在了同一个i,那么就叫冲突,又叫碰撞,这样会在table[i]上形成一个链表。
我们知道,如果table[]的尺寸很小,比如只有2个,如果要放进10个keys的话,那么碰撞非常频繁,于是一个O(1)的查找算法,就变成了链表遍历,性能变成了O(n),这是Hash表的缺陷(可参看《Hash Collision DoS 问题》)。
所以,Hash表的尺寸和容量非常的重要。一般来说,Hash表这个容器当有数据要插入时,都会检查容量有没有超过设定的thredhold,如果超过,需要增大Hash表的尺寸,这样一来,整个Hash表里的无素都需要被重算一遍。这叫rehash,这个成本相当的大。
HashMap的rehash源码
public V put(K key, V value)
{
......
//算Hash值
int hash = hash(key.hashCode());
int i = indexFor(hash, table.length);
//如果该key已被插入,则替换掉旧的value (链接操作)
for (Entry<K,V> e = table[i]; e != null; e = e.next) {
Object k;
if (e.hash == hash && ((k = e.key) == key || key.equals(k))) {
V oldValue = e.value;
e.value = value;
e.recordAccess(this);
return oldValue;
}
}
modCount++;
//该key不存在,需要增加一个结点
addEntry(hash, key, value, i);
return null;
}
void addEntry(int hash, K key, V value, int bucketIndex)
{
Entry<K,V> e = table[bucketIndex];
table[bucketIndex] = new Entry<K,V>(hash, key, value, e);
//查看当前的size是否超过了我们设定的阈值threshold,如果超过,需要resize
if (size++ >= threshold)
resize(2 * table.length);
} void resize(int newCapacity)
{
Entry[] oldTable = table;
int oldCapacity = oldTable.length;
......
//创建一个新的Hash Table
Entry[] newTable = new Entry[newCapacity];
//将Old Hash Table上的数据迁移到New Hash Table上
transfer(newTable);
table = newTable;
threshold = (int)(newCapacity * loadFactor);
}
新建一个更大尺寸的hash表,然后把数据从老的Hash表中迁移到新的Hash表中。
void transfer(Entry[] newTable)
{
Entry[] src = table;
int newCapacity = newTable.length;
//下面这段代码的意思是:
// 从OldTable里摘一个元素出来,然后放到NewTable中
for (int j = 0; j < src.length; j++) {
Entry<K,V> e = src[j];
if (e != null) {
src[j] = null;
do {
Entry<K,V> next = e.next;
int i = indexFor(e.hash, newCapacity);
e.next = newTable[i];
newTable[i] = e;
e = next;
} while (e != null);
}
}
}
正常的ReHash的过程
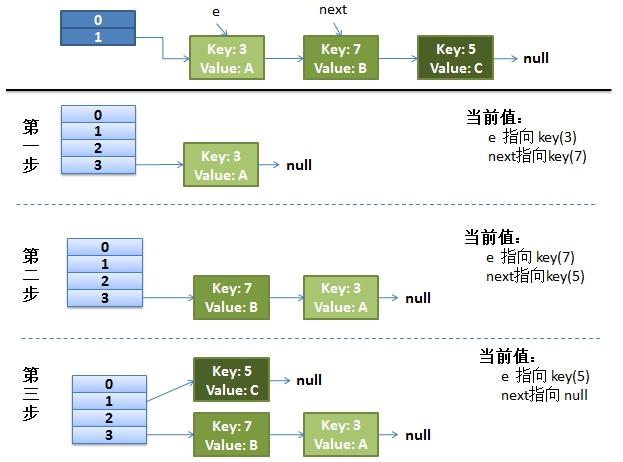
画了个图做了个演示。
- 我假设了我们的hash算法就是简单的用key mod 一下表的大小(也就是数组的长度)。
- 最上面的是old hash 表,其中的Hash表的size=2, 所以key = 3, 7, 5,在mod 2以后都冲突在table[1]这里了。
- 接下来的三个步骤是Hash表 resize成4,然后所有的<key,value> 重新rehash的过程
并发下的rehash
1)假设我们有两个线程。我用红色和浅蓝色标注了一下。
我们再回头看一下我们的 transfer代码中的这个细节:
- do {
- Entry<K,V> next = e.next; // <--假设线程一执行到这里就被调度挂起了
- int i = indexFor(e.hash, newCapacity);
- e.next = newTable[i];
- newTable[i] = e;
- e = next;
- } while (e != null);
而我们的线程二执行完成了。于是我们有下面的这个样子。
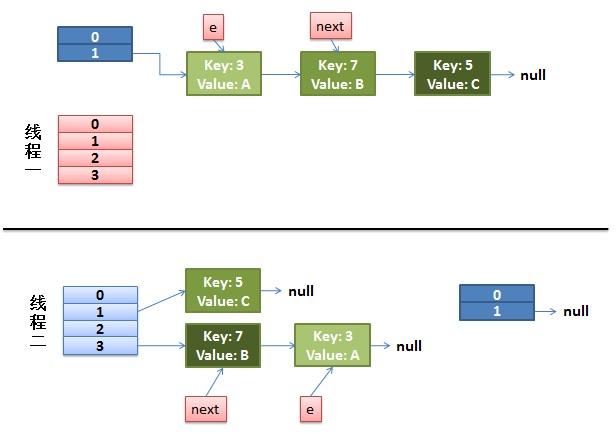
注意,因为Thread1的 e 指向了key(3),而next指向了key(7),其在线程二rehash后,指向了线程二重组后的链表。我们可以看到链表的顺序被反转后。
2)线程一被调度回来执行。
- 先是执行 newTalbe[i] = e; (这里,下面线程一的3位置指向Key:3)
- 然后是e = next,导致了e指向了key(7),
- 而下一次循环的next = e.next导致了next指向了key(3)
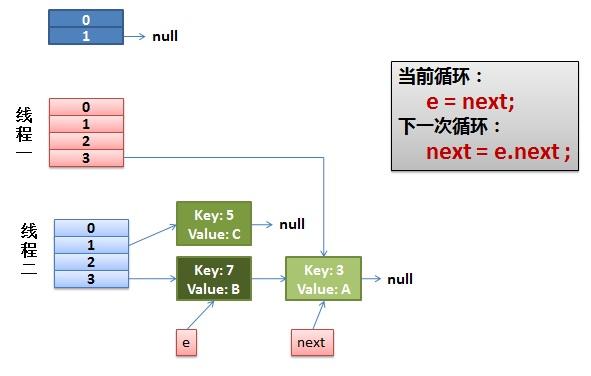
3)一切安好。
线程一接着工作。把key(7)摘下来,放到newTable[i]的第一个,然后把e和next往下移。
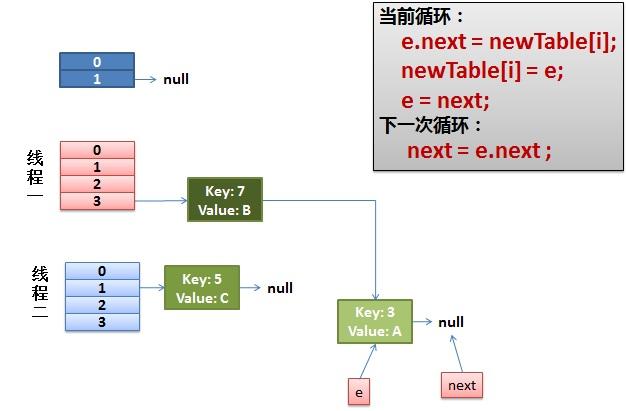
4)环形链接出现。
e.next = newTable[i] 导致 key(3).next 指向了 key(7)
注意:此时的key(7).next 已经指向了key(3), 环形链表就这样出现了。
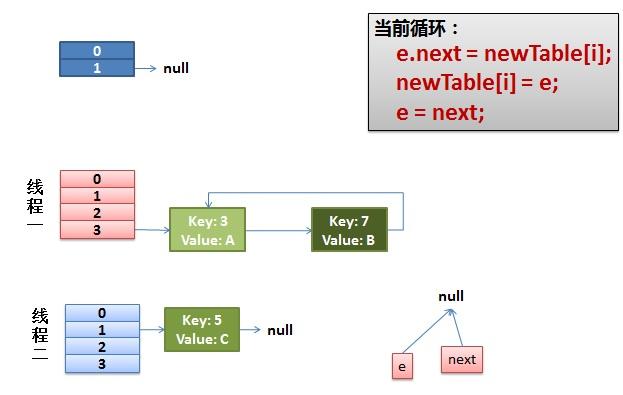
于是,当我们的线程一调用到,HashTable.get(11)时,悲剧就出现了——Infinite Loop。
其它
有人把这个问题报给了Sun,不过Sun不认为这个是一个问题。因为HashMap本来就不支持并发。要并发就用ConcurrentHashmap
我在这里把这个事情记录下来,只是为了让大家了解并体会一下并发环境下的危险。
HashMap1.8
HashMap1.8多线程put不会造成死循环
hashmap1.7多线程操作会造成链表的循环,上面已经讲了。是put过程中的resize方法在调用transfer方法的时候导致的死锁。
final Node<K,V>[] resize() {
Node<K,V>[] oldTab = table;//oldTab指向hash桶数组
int oldCap = (oldTab == null) ? 0 : oldTab.length;
int oldThr = threshold;
int newCap, newThr = 0;
if (oldCap > 0) {//如果oldCap不为空的话,就是hash桶数组不为空
if (oldCap >= MAXIMUM_CAPACITY) {//如果大于最大容量了,就赋值为整数最大的阀值
threshold = Integer.MAX_VALUE;
return oldTab;//返回
}//如果当前hash桶数组的长度在扩容后仍然小于最大容量 并且oldCap大于默认值16
else if ((newCap = oldCap << 1) < MAXIMUM_CAPACITY &&
oldCap >= DEFAULT_INITIAL_CAPACITY)
newThr = oldThr << 1; // double threshold 双倍扩容阀值threshold
}
else if (oldThr > 0) // initial capacity was placed in threshold
newCap = oldThr;
else { // zero initial threshold signifies using defaults
newCap = DEFAULT_INITIAL_CAPACITY;
newThr = (int)(DEFAULT_LOAD_FACTOR * DEFAULT_INITIAL_CAPACITY);
}
if (newThr == 0) {
float ft = (float)newCap * loadFactor;
newThr = (newCap < MAXIMUM_CAPACITY && ft < (float)MAXIMUM_CAPACITY ?
(int)ft : Integer.MAX_VALUE);
}
threshold = newThr;
@SuppressWarnings({"rawtypes","unchecked"})
Node<K,V>[] newTab = (Node<K,V>[])new Node[newCap];//新建hash桶数组
table = newTab;//将新数组的值复制给旧的hash桶数组
if (oldTab != null) {//进行扩容操作,复制Node对象值到新的hash桶数组
for (int j = 0; j < oldCap; ++j) {
Node<K,V> e;
if ((e = oldTab[j]) != null) {//如果旧的hash桶数组在j结点处不为空,复制给e
oldTab[j] = null;//将旧的hash桶数组在j结点处设置为空,方便gc
if (e.next == null)//如果e后面没有Node结点
newTab[e.hash & (newCap - 1)] = e;//直接对e的hash值对新的数组长度求模获得存储位置
else if (e instanceof TreeNode)//如果e是红黑树的类型,那么添加到红黑树中
((TreeNode<K,V>)e).split(this, newTab, j, oldCap);
else { // preserve order
Node<K,V> loHead = null, loTail = null;
Node<K,V> hiHead = null, hiTail = null;
Node<K,V> next;
do {
next = e.next;//将Node结点的next赋值给next
if ((e.hash & oldCap) == 0) {//如果结点e的hash值与原hash桶数组的长度作与运算为0
if (loTail == null)//如果loTail为null
loHead = e;//将e结点赋值给loHead
else
loTail.next = e;//否则将e赋值给loTail.next
loTail = e;//然后将e复制给loTail
}
else {//如果结点e的hash值与原hash桶数组的长度作与运算不为0
if (hiTail == null)//如果hiTail为null
hiHead = e;//将e赋值给hiHead
else
hiTail.next = e;//如果hiTail不为空,将e复制给hiTail.next
hiTail = e;//将e复制个hiTail
}
} while ((e = next) != null);//直到e为空
if (loTail != null) {//如果loTail不为空
loTail.next = null;//将loTail.next设置为空
newTab[j] = loHead;//将loHead赋值给新的hash桶数组[j]处
}
if (hiTail != null) {//如果hiTail不为空
hiTail.next = null;//将hiTail.next赋值为空
newTab[j + oldCap] = hiHead;//将hiHead赋值给新的hash桶数组[j+旧hash桶数组长度]
}
}
}
}
}
return newTab;
}
声明两对指针,维护两个连链表
依次在末端添加新的元素。(在多线程操作的情况下,无非是第二个线程重复第一个线程一模一样的操作)。
的确不会因为多线程put导致死循环,但是依然有其他的弊端,比如数据丢失等等。因此多线程情况下还是建议使用concurrenthashmap。
应该是resize()方法中这句: if ((e = oldTab[j]) != null) { oldTab[j] = null; 多个线程都触发了扩容操作。多线程put的时候,当index相同而又同时达到链表的末尾时,另一个线程put的数据会把之前线程put的数据覆盖掉,就会产生数据丢失。
HashMap知识点、问题的更多相关文章
- HashMap知识点总结,这一篇算是总结的不错的了,建议看看!
HashMap存储结构 内部包含了⼀个 Entry 类型的数组 Entry[] table.transient Entry[] table;(transient:表示不能被序列化)Entry类型存储着 ...
- 阿里P7岗位面试,面试官问我:为什么HashMap底层树化标准的元素个数是8
前言 先声明一下,本文有点标题党了,像我这样的菜鸡何德何能去面试阿里的P7岗啊,不过,这确实是阿里p7级岗位的面试题,当然,参加面试的人不是我,而是我部门的一个大佬.他把自己的面试经验分享给了我,也让 ...
- 牛客网Java刷题知识点之为什么HashMap和HashSet区别
不多说,直接上干货! HashMap 和 HashSet的区别是Java面试中最常被问到的问题.如果没有涉及到Collection框架以及多线程的面试,可以说是不完整.而Collection框架的 ...
- 牛客网Java刷题知识点之为什么HashMap不支持线程的同步,不是线程安全的?如何实现HashMap的同步?
不多说,直接上干货! 这篇我是从整体出发去写的. 牛客网Java刷题知识点之Java 集合框架的构成.集合框架中的迭代器Iterator.集合框架中的集合接口Collection(List和Set). ...
- 牛客网Java刷题知识点之Map的两种取值方式keySet和entrySet、HashMap 、Hashtable、TreeMap、LinkedHashMap、ConcurrentHashMap 、WeakHashMap
不多说,直接上干货! 这篇我是从整体出发去写的. 牛客网Java刷题知识点之Java 集合框架的构成.集合框架中的迭代器Iterator.集合框架中的集合接口Collection(List和Set). ...
- 牛客网Java刷题知识点之HashMap的实现原理、HashMap的存储结构、HashMap在JDK1.6、JDK1.7、JDK1.8之间的差异以及带来的性能影响
不多说,直接上干货! 福利 => 每天都推送 欢迎大家,关注微信扫码并加入我的4个微信公众号: 大数据躺过的坑 Java从入门到架构师 人工智能躺过的坑 ...
- HashMap面试知识点
HashMap的工作原理是近年来常见的Java面试题. 几乎每个Java程序员都知道HashMap,都知道哪里要用HashMap,知道Hashtable和HashMap之间的区别,那么为何这道面试题如 ...
- HashMap面试知识点总结
主要参考 JavaGuide 和 敖丙 的文章, 其中也有参考其他的文章, 但忘记保存链接了, 文中图片也是引用别的大佬的, 请见谅. 新手上路, 若有问题, 欢迎指正. 背景 HashMap 的相关 ...
- HashMap几个需要注意的知识点
HashMap简介 HashMap 是java集合框架的一部分. key value都允许null值 (除了非同步和允许使用 null 之外,HashMap 类与 Hashtable 大致相同) 不保 ...
随机推荐
- P2864 [USACO06JAN]树林The Grove
P2864 [USACO06JAN]树林The Grove 神奇的射线法+bfs 裸的bfs很难写....... 那么我们找一个最外围障碍点,向图的外边引一条虚拟射线. 蓝后bfs时经过这条射线奇数次 ...
- Node.js读取文件内容
原文链接:http://blog.csdn.net/zk437092645/article/details/9231787 Node.js读取文件内容包括同步和异步两种方式. 1.同步读取,调用的是r ...
- Adobe漏洞攻击
Adobe漏洞攻击 windows ip 开启msfconsole 进入攻击模块 设置攻击载荷payload 设置相关参数 确定需要修改的参数 exploit生成5303.pdf 将pdf复制到靶机里 ...
- 20145304 刘钦令 Exp2 后门原理与实践
20145304 刘钦令 Exp2 后门原理与实践 基础问题回答 (1)例举你能想到的一个后门进入到你系统中的可能方式? 浏览网页时,或许会触发网站中隐藏的下载代码,将后门程序下载到默认地址. 下载的 ...
- 牛客网试卷: 京东2019校招笔试Java开发工程师笔试题(1-)
1.在软件开发过程中,我们可以采用不同的过程模型,下列有关 增量模型描述正确的是() A 是一种线性开发模型,具有不可回溯性 B 把待开发的软件系统模块化,将每个模块作为一个增量组件,从而分批次地分析 ...
- script 加载顺序问题的延展研究
今天群里有人问为什么会出现脚本的加载顺序与定义脚本顺序不一致的问题,这个问题引起了我的好奇,经过一番调研,有了这篇文章. 这是一个伪命题吗? 首先,W3C 推荐 script 脚本应该被立即加载和执行 ...
- Python3基础 os chdir 改变工作目录
Python : 3.7.0 OS : Ubuntu 18.04.1 LTS IDE : PyCharm 2018.2.4 Conda ...
- ZedGraph如何动态的加载曲线
ZedGraph的在线文档 http://zedgraph.sourceforge.net/documentation/default.html 官网的源代码 http://sourceforge.n ...
- hdu 3415 Max Sum of Max-K-sub-sequence 单调队列优化DP
题目链接: https://www.cnblogs.com/Draymonder/p/9536681.html 同上一篇文章,只是 需要记录最大值的开始和结束的位置 #include <iost ...
- 学习mybatis-3 step by step 篇三
动态 SQL if choose (when, otherwise) trim (where, set) foreach 动态 SQL 通常要做的事情是有条件地包含 where 子句的一部分.比如: ...