理解ThreadPoolExecutor线程池的corePoolSize、maximumPoolSize和poolSize
我们知道,受限于硬件、内存和性能,我们不可能无限制的创建任意数量的线程,因为每一台机器允许的最大线程是一个有界值。也就是说ThreadPoolExecutor管理的线程数量是有界的。线程池就是用这些有限个数的线程,去执行提交的任务。然而对于多用户、高并发的应用来说,提交的任务数量非常巨大,一定会比允许的最大线程数多很多。为了解决这个问题,必须要引入排队机制,或者是在内存中,或者是在硬盘等容量很大的存储介质中。J.U.C提供的ThreadPoolExecutor只支持任务在内存中排队,通过BlockingQueue暂存还没有来得及执行的任务。
任务的管理是一件比较容易的事,复杂的是线程的管理,这会涉及线程数量、等待/唤醒、同步/锁、线程创建和死亡等问题。ThreadPoolExecutor与线程相关的几个成员变量是:keepAliveTime、allowCoreThreadTimeOut、poolSize、corePoolSize、maximumPoolSize,它们共同负责线程的创建和销毁。
corePoolSize:
线程池的基本大小,即在没有任务需要执行的时候线程池的大小,并且只有在工作队列满了的情况下才会创建超出这个数量的线程。这里需要注意的是:在刚刚创建ThreadPoolExecutor的时候,线程并不会立即启动,而是要等到有任务提交时才会启动,除非调用了prestartCoreThread/prestartAllCoreThreads事先启动核心线程。再考虑到keepAliveTime和allowCoreThreadTimeOut超时参数的影响,所以没有任务需要执行的时候,线程池的大小不一定是corePoolSize。
maximumPoolSize:
线程池中允许的最大线程数,线程池中的当前线程数目不会超过该值。如果队列中任务已满,并且当前线程个数小于maximumPoolSize,那么会创建新的线程来执行任务。这里值得一提的是largestPoolSize,该变量记录了线程池在整个生命周期中曾经出现的最大线程个数。为什么说是曾经呢?因为线程池创建之后,可以调用setMaximumPoolSize()改变运行的最大线程的数目。
poolSize:
线程池中当前线程的数量,当该值为0的时候,意味着没有任何线程,线程池会终止;同一时刻,poolSize不会超过maximumPoolSize。
现在我们通过ThreadPoolExecutor.execute()方法,看一下这3个属性的关系,以及线程池如何处理新提交的任务。以下源码基于JDK1.6.0_37版本。
private boolean addIfUnderCorePoolSize(Runnable firstTask) {
Thread t = null;
final ReentrantLock mainLock = this.mainLock;
mainLock.lock();
try {
if (poolSize < corePoolSize && runState == RUNNING)
t = addThread(firstTask);
} finally {
mainLock.unlock();
}
if (t == null)
return false;
t.start();
return true;
}
private boolean addIfUnderMaximumPoolSize(Runnable firstTask) {
Thread t = null;
final ReentrantLock mainLock = this.mainLock;
mainLock.lock();
try {
if (poolSize < maximumPoolSize && runState == RUNNING)
t = addThread(firstTask);
} finally {
mainLock.unlock();
}
if (t == null)
return false;
t.start();
return true;
}
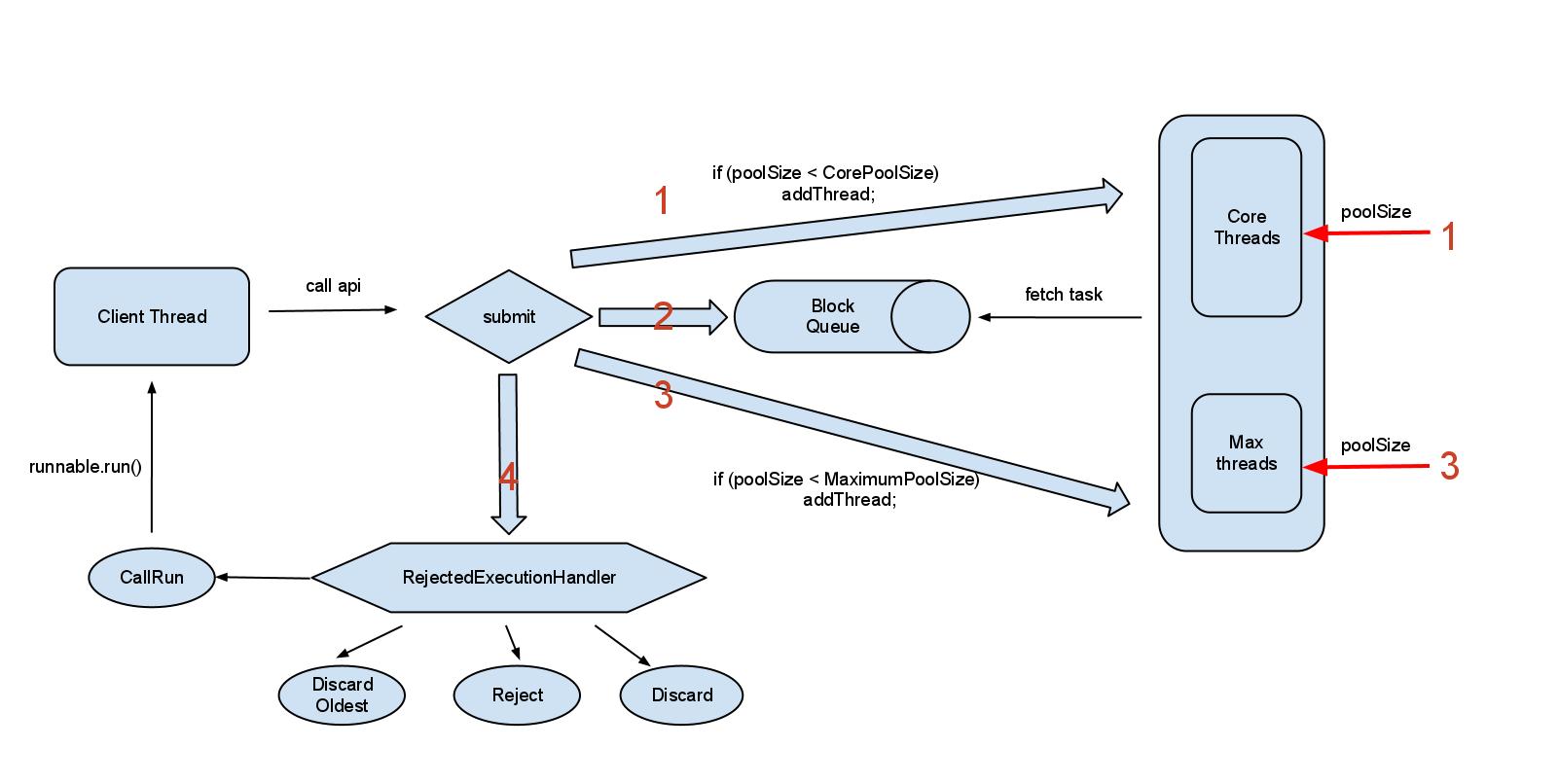
新提交一个任务时的处理流程很明显:
1、如果当前线程池的线程数还没有达到基本大小(poolSize < corePoolSize),无论是否有空闲的线程新增一个线程处理新提交的任务;
2、如果当前线程池的线程数大于或等于基本大小(poolSize >= corePoolSize) 且任务队列未满时,就将新提交的任务提交到阻塞队列排队,等候处理workQueue.offer(command);
3、如果当前线程池的线程数大于或等于基本大小(poolSize >= corePoolSize) 且任务队列满时;
3.1、当前poolSize<maximumPoolSize,那么就新增线程来处理任务;
3.2、当前poolSize=maximumPoolSize,那么意味着线程池的处理能力已经达到了极限,此时需要拒绝新增加的任务。至于如何拒绝处理新增的任务,取决于线程池的饱和策略RejectedExecutionHandler。
Queuing
Any BlockingQueue may be used to transfer and hold submitted tasks. The use of this queue interacts with pool sizing:
- If fewer than corePoolSize threads are running, the Executor always prefers adding a new thread rather than queuing.
- If corePoolSize or more threads are running, the Executor always prefers queuing a request rather than adding a new thread.
- If a request cannot be queued, a new thread is created unless this would exceed maximumPoolSize, in which case, the task will be rejected.
1、corePoolSize:核心线程数
* 核心线程会一直存活,及时没有任务需要执行
* 当线程数小于核心线程数时,即使有线程空闲,线程池也会优先创建新线程处理
* 设置allowCoreThreadTimeout=true(默认false)时,核心线程会超时关闭 2、queueCapacity:任务队列容量(阻塞队列)
* 当核心线程数达到最大时,新任务会放在队列中排队等待执行 3、maxPoolSize:最大线程数
* 当线程数>=corePoolSize,且任务队列已满时。线程池会创建新线程来处理任务
* 当线程数=maxPoolSize,且任务队列已满时,线程池会拒绝处理任务而抛出异常 4、 keepAliveTime:线程空闲时间
* 当线程空闲时间达到keepAliveTime时,线程会退出,直到线程数量=corePoolSize
* 如果allowCoreThreadTimeout=true,则会直到线程数量=0 5、allowCoreThreadTimeout:允许核心线程超时
6、rejectedExecutionHandler:任务拒绝处理器
* 两种情况会拒绝处理任务:
- 当线程数已经达到maxPoolSize,切队列已满,会拒绝新任务
- 当线程池被调用shutdown()后,会等待线程池里的任务执行完毕,再shutdown。如果在调用shutdown()和线程池真正shutdown之间提交任务,会拒绝新任务
* 线程池会调用rejectedExecutionHandler来处理这个任务。如果没有设置默认是AbortPolicy,会抛出异常
* ThreadPoolExecutor类有几个内部实现类来处理这类情况:
- AbortPolicy 丢弃任务,抛运行时异常
- CallerRunsPolicy 执行任务
- DiscardPolicy 忽视,什么都不会发生
- DiscardOldestPolicy 从队列中踢出最先进入队列(最后一个执行)的任务
* 实现RejectedExecutionHandler接口,可自定义处理器
接下来我们看下allowCoreThreadTimeOut和keepAliveTime属性的含义。在压力很大的情况下,线程池中的所有线程都在处理新提交的任务或者是在排队的任务,这个时候线程池处在忙碌状态。如果压力很小,那么可能很多线程池都处在空闲状态,这个时候为了节省系统资源,回收这些没有用的空闲线程,就必须提供一些超时机制,这也是线程池大小调节策略的一部分。通过corePoolSize和maximumPoolSize,控制如何新增线程;通过allowCoreThreadTimeOut和keepAliveTime,控制如何销毁线程。
allowCoreThreadTimeOut:
该属性用来控制是否允许核心线程超时退出。默认值为:false。If false,core threads stay alive even when idle.If true, core threads use keepAliveTime to time out waiting for work。如果线程池的大小已经达到了corePoolSize,不管有没有任务需要执行,线程池都会保证这些核心线程处于存活状态。可以知道:该属性只是用来控制核心线程的。
keepAliveTime:
如果一个线程处在空闲状态的时间超过了该属性值,就会因为超时而退出。举个例子,如果线程池的核心大小corePoolSize=5,而当前大小poolSize =8,那么超出核心大小的线程,会按照keepAliveTime的值判断是否会超时退出。如果线程池的核心大小corePoolSize=5,而当前大小poolSize =5,那么线程池中所有线程都是核心线程,这个时候线程是否会退出,取决于allowCoreThreadTimeOut。
Runnable getTask() {
for (;;) {
try {
int state = runState;
if (state > SHUTDOWN)
return null;
Runnable r;
if (state == SHUTDOWN) // Help drain queue
r = workQueue.poll();
else if (poolSize > corePoolSize || allowCoreThreadTimeOut)
r = workQueue.poll(keepAliveTime, TimeUnit.NANOSECONDS);
else
r = workQueue.take();
if (r != null)
return r;
if (workerCanExit()) {
if (runState >= SHUTDOWN) // Wake up others
interruptIdleWorkers();
return null;
}
// Else retry
} catch (InterruptedException ie) {
// On interruption, re-check runState
}
}
}
(poolSize > corePoolSize || allowCoreThreadTimeOut)这个条件,就是用来判断是否允许当前线程退出。workQueue.poll(keepAliveTime, TimeUnit.NANOSECONDS);就是借助阻塞队列,让空闲线程等待keepAliveTime时间之后,恢复执行。这样空闲线程会由于超时而退出。
理解ThreadPoolExecutor线程池的corePoolSize、maximumPoolSize和poolSize的更多相关文章
- ThreadPoolExecutor 线程池的源码解析
1.背景介绍 上一篇从整体上介绍了Executor接口,从上一篇我们知道了Executor框架的最顶层实现是ThreadPoolExecutor类,Executors工厂类中提供的newSchedul ...
- j.u.c系列(01) ---初探ThreadPoolExecutor线程池
写在前面 之前探索tomcat7启动的过程中,使用了线程池(ThreadPoolExecutor)的技术 public void createExecutor() { internalExecutor ...
- 深入理解Java线程池
我们使用线程的时候就去创建一个线程,这样实现起来非常简便,但是就会有一个问题: 如果并发的线程数量很多,并且每个线程都是执行一个时间很短的任务就结束了,这样频繁创建线程就会大大降低系统的效率,因为频繁 ...
- Executors、ThreadPoolExecutor线程池讲解
官方+白话讲解Executors.ThreadPoolExecutor线程池使用 Executors:JDK给提供的线程工具类,静态方法构建线程池服务ExecutorService,也就是Thread ...
- 深入理解 Java 线程池
一.简介 什么是线程池 线程池是一种多线程处理形式,处理过程中将任务添加到队列,然后在创建线程后自动启动这些任务. 为什么要用线程池 如果并发请求数量很多,但每个线程执行的时间很短,就会出现频繁的创建 ...
- 手写线程池,对照学习ThreadPoolExecutor线程池实现原理!
作者:小傅哥 博客:https://bugstack.cn Github:https://github.com/fuzhengwei/CodeGuide/wiki 沉淀.分享.成长,让自己和他人都能有 ...
- 源码剖析ThreadPoolExecutor线程池及阻塞队列
本文章对ThreadPoolExecutor线程池的底层源码进行分析,线程池如何起到了线程复用.又是如何进行维护我们的线程任务的呢?我们直接进入正题: 首先我们看一下ThreadPoolExecuto ...
- 手写一个线程池,带你学习ThreadPoolExecutor线程池实现原理
摘要:从手写线程池开始,逐步的分析这些代码在Java的线程池中是如何实现的. 本文分享自华为云社区<手写线程池,对照学习ThreadPoolExecutor线程池实现原理!>,作者:小傅哥 ...
- Android ThreadPoolExecutor线程池
引言 Android的线程池概念来自于Java的Executor,真正的线程池实现为ThreadPoolExecutor.在Android中,提供了4类不同的线程池,具体下面会说到.为什么使用线程池呢 ...
随机推荐
- 20165235祁瑛 2018-3 《Java程序设计》第三周学习总结
20165235祁瑛 2018-3 <Java程序设计>第三周学习总结 教材学习内容总结 类与对象学习总结 类:java作为面向对象型语言具有三个特性:①封装性.②继承性.③多态性.jav ...
- day66 模板小结 [母板继承,块,组件]
小结: day65 1. 老师编辑功能写完 1. magic2函数 --> 用两层for循环解决 全栈8期之殇 问题 2. 模板语言 in 语法 {% if xx in xx_list %} { ...
- day43 mysql 基本管理,[破解密码以及用户权限设置]以及慢日志查询配置
配置文件:详细步骤, 1,找到mysql的安装包,然后打开后会看到一个my.ini命名的程序,把它拖拽到notepad++里面来打开,(应该是其他文本形式也可以打开,可以试一下),直接拖拽即可打开该文 ...
- Python之路【第八篇】:面向对象的程序设计
阅读目录 一 面向对象的程序设计的由来二 什么是面向对象的程序设计及为什么要有它三 类和对象3.1 什么是对象,什么是类3.2 类相关知识3.3 对象相关知识3.4 对象之间的交互3.5 类名称空间与 ...
- SparkException: Could not find CoarseGrainedScheduler or it has been stopped.
org.apache.spark.SparkException: Could not find CoarseGrainedScheduler or it has been stopped. at or ...
- 牛客练习赛35-背单词-线性DP
背单词 思路 :dp[ i ] [ 0 ]表示 第i 位放的元音 dp[ i ] [ 1 ]表示 第i 位放的辅音 ,cnt [ i ]含义是 长度为 i 的方案数. 转移 :dp[ i ] ...
- 关于eclipse启动报错,an error has occurred.see the log file
网上搜索各种方法,得知为由于Eclipse卡死或强制关闭之后会出现的情况 提供解决方法一: 查看log文件,发现有这样的信息: !MESSAGE The workspace exited with u ...
- 修改HAL标准库用printf函数发送数据直接输出
主函数文件,请直接关注自己写上去的代码: 直接看43行代码:#include "stdio.h"//要添加这个头文件 还有97行到112行:实现用HAL库函数和printf函数发送 ...
- [NOIp2018提高组]旅行
[NOIp2018提高组]旅行: 题目大意: 一个\(n(n\le5000)\)个点,\(m(m\le n)\)条边的连通图.可以从任意一个点出发,前往任意一个相邻的未访问的结点,或沿着第一次来这个点 ...
- OpenCV3.2.0+VS2017环境配置与常见问题(巨细坑爹版)
目录 安装 常见问题 题外话:首先,配环境一定要有耐心... 本博客是本小白第一次装OpenCV成功后第一时间整理发布.用的是刚下载好的OpenCV3.2.0版,用x64编译器Debug运行(当然Re ...