大数据搜索引擎之elasticsearch使用篇(一)
作者:yanzm
原文来自:https://bbs.ichunqiu.com/thread-42421-1-1.html
1.基础介绍
本期,我们将着重介绍elasticsearch的基本使用方法。
2.名词解释
在介绍elasticsearch的基本使用方法之前,我们先来了解一下在elasticsearch中常用名词的含义。
索引(Index):一个索引就是含有某些相似特性的文档的集合。
例如,你可以有一个用户数据的索引,一个产品目录的索引,还有其他的有规则数据的索引。一个索引被一个名称(必须都是小写)唯一标识,并且这个名称被用于索引通过文档去执行索引,搜索,更新和删除操作。
类型(Type):一个类型是你的索引中的一个分类或者说是一个分区,它可以让你在同一索引中存储不同类型的文档。
例如,为用户建一个类型,为博客文章建另一个类型。
文档(Document):一个文档是一个可被索引的数据的基础单元。
例如,你可以给一个单独的用户创建一个文档,给单个产品创建一个文档,以及其他的单独的规则。这个文档用JSON格式表现,JSON是一种普遍的网络数据交换格式。
在一个索引或类型中,你可以根据自己的需求存储任意多的文档。注意,虽然一个文档在物理存储上属于一个索引,但是文档实际上必须指定一个在索引中的类型。
3.基本使用
进入控制台
1.打开浏览器,访问:http://服务器IP:5601/
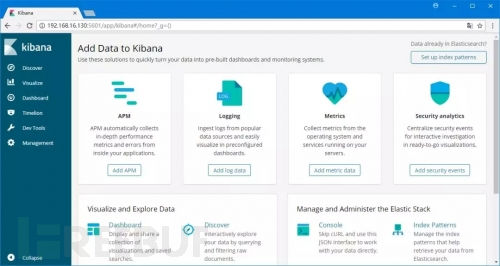
2.点击左边导航窗口的Dev Tools,进入开发者控制台。
访问数据的模式:
命令:<REST Verb> /<Index>/<Type>/<ID>
解释:请求方法 /索引名/类型/文档ID
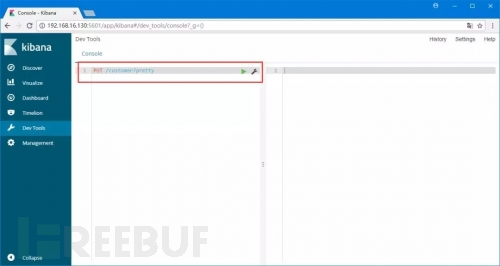
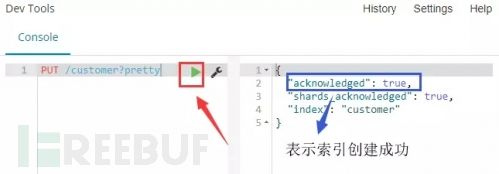
创建一个索引:
命令:PUT /customer?pretty
解释:使用PUT方法创建了一个名为“customer”的索引。我们简单的在请求后面追加pretty参数来使返回值以格式化过美观的JSON输出(如果返回值是JSON格式的话)
命令运行:在开发者控制台中输入创建索引的命令。
点击命令上的运行按钮,可在右边看到运行结果。
查看已创建索引:
命令:GET /_cat/indices?v
解释:使用GET方法进行数据查询,命令在这里是查询当前存在的所有索引。
命令运行:可在右边看到已创建的索引customer

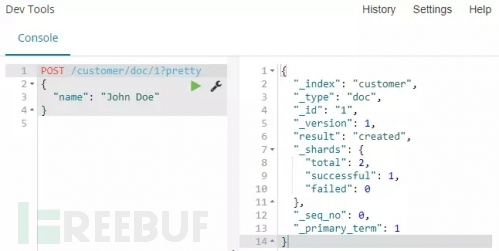
创建一个文档:
命令:

解释:使用POST请求方式,将一个简单的顾客文档放入customer索引中,这个文档ID为1。
命令运行:从下面截图我们可以看到,一个新的顾客文档已经在customer索引中成功创建。同时这个文档有一个自己的id,这个id就是我们在将文档加入索引时指定的。
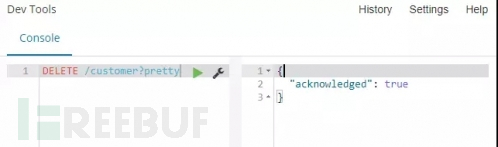
删除一个索引:
命令:DELETE /customer?pretty
解释:使用DELETE请求方式,将customer索引删除,并使用pretty参数美化输出。
命令运行:以下截图结果意味着我们的索引已经被删除。
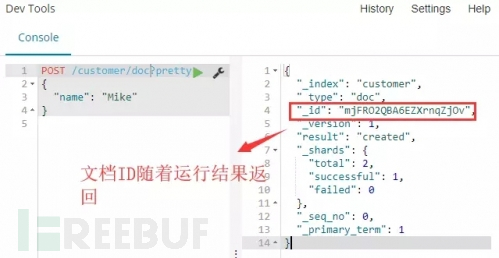
添加文档数据:
命令:

解释:上面创建一个文档的操作中,我们有指定文档ID为1。而实际上,当将文档加入索引时,ID部分并不是必须的。如果没有指定,Elasticsearch将会生产一个随机的ID,然后使用它去索引文档。实际Elasticsearch生成的ID(或者是我们明确指定的)将会在API调用成功后返回。
命令运行:如下图命令运行结果可以看到,在没有指定文档ID的情况下,随机的文档ID会被生成并随着运行结果返回。
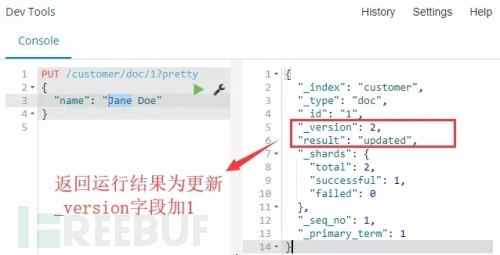
修改文档数据:
命令:

解释:如果我们再次执行上面的请求,以相同的文档内容或者是不同的,Elasticsearch将会用这个新文档替换之前的文档(就是以相同的ID重新加入索引)。
命令运行:通过下图运行结果可以看到,每次操作数据,_version字段将自加1。
删除文档数据:
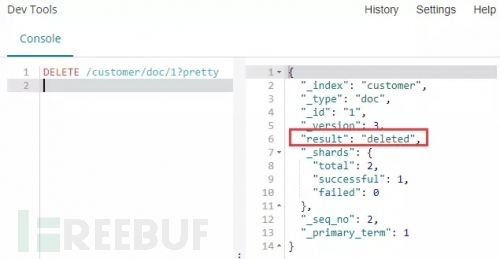
命令:DELETE /customer/doc/1?pretty
解释:使用DELETE请求方式,将customer索引下ID为1的文档删除,并使用pretty参数美化输出。
命令运行:以下截图结果意味着我们ID为1的文档数据已经被删除。
批处理:
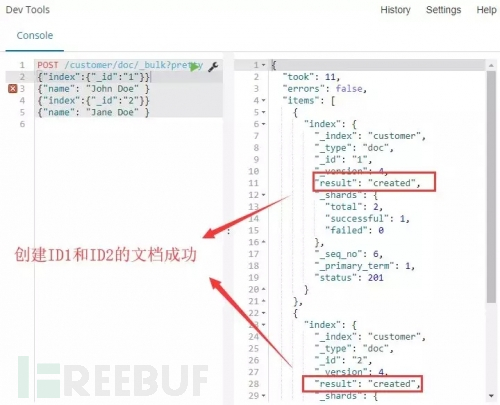
命令1:

解释:调用批处理方法_bulk,先是创建/更新ID为1的文档,然后创建/更新ID为2的文档
命令运行:成功创建ID为1、2的文档。
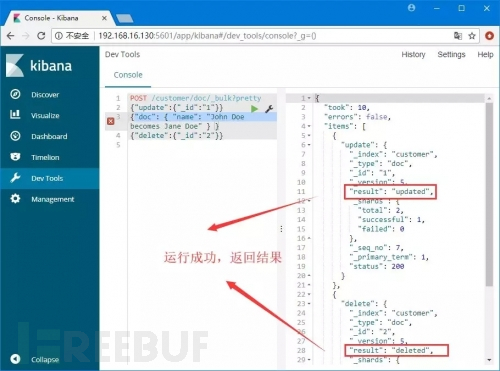
命令2:

解释:调用批处理方法_bulk,先是更新ID为1的文档,然后删除ID为2的文档。
命令运行:
有问题大家可以留言哦~也欢迎大家到春秋论坛中来玩耍呢! >>>点击跳转
大数据搜索引擎之elasticsearch使用篇(一)的更多相关文章
- Hadoop生态圈-大数据生态体系快速入门篇
Hadoop生态圈-大数据生态体系快速入门篇 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.大数据概念 1>.什么是大数据 大数据(big data):是指无法在一定时间 ...
- 用Python实现一个大数据搜索引擎
用Python实现一个大数据搜索引擎 搜索是大数据领域里常见的需求.Splunk和ELK分别是该领域在非开源和开源领域里的领导者.本文利用很少的Python代码实现了一个基本的数据搜索功能,试图让大家 ...
- 我的ElasticSearch集群部署总结--大数据搜索引擎你不得不知
摘要:世上有三类书籍:1.介绍知识,2.阐述理论,3.工具书:世间也存在两类知识:1.技术,2.思想.以下是我在部署ElasticSearch集群时的经验总结,它们大体属于第一类知识“techknow ...
- 大数据基础知识问答----spark篇,大数据生态圈
Spark相关知识点 1.Spark基础知识 1.Spark是什么? UCBerkeley AMPlab所开源的类HadoopMapReduce的通用的并行计算框架 dfsSpark基于mapredu ...
- 大数据基础知识问答----hadoop篇
handoop相关知识点 1.Hadoop是什么? Hadoop是一个由Apache基金会所开发的分布式系统基础架构.用户可以在不了解分布式底层细节的情况下,开发分布式程序.充分利用集群的威力进行高速 ...
- 用 Python 实现一个大数据搜索引擎
搜索是大数据领域里常见的需求.Splunk和ELK分别是该领域在非开源和开源领域里的领导者.本文利用很少的Python代码实现了一个基本的数据搜索功能,试图让大家理解大数据搜索的基本原理. 布隆过滤器 ...
- 大数据竞赛平台——Kaggle 入门篇
这篇文章适合那些刚接触Kaggle.想尽快熟悉Kaggle并且独立完成一个竞赛项目的网友,对于已经在Kaggle上参赛过的网友来说,大可不必耗费时间阅读本文.本文分为两部分介绍Kaggle,第一部分简 ...
- 【原创】大数据基础之ElasticSearch(2)常用API整理
Fortunately, Elasticsearch provides a very comprehensive and powerful REST API that you can use to i ...
- 【原创】大数据基础之ElasticSearch(4)es数据导入过程
1 准备analyzer 内置analyzer 参考:https://www.elastic.co/guide/en/elasticsearch/reference/current/analysis- ...
随机推荐
- mysql const与eq_ref的区别
简单地说是const是直接按主键或唯一键读取,eq_ref用于联表查询的情况,按联表的主键或唯一键联合查询. 下面的内容翻译自官方方档: const该表最多有一个匹配行, 在查询开始时读取.由于只有一 ...
- cmd创建文件命令
一.建立空文件的几种方法 1.cd.>a.txt cd.表示改变当前目录为当前目录,即等于没改变:而且此命令不会有输出. >表示把命令输出写入到文件.后面跟着a.txt,就表示写入到a.t ...
- [Ting's笔记Day5]在部署到Heroku之前,将Rails项目从SQLite设定为PostgreSQL
前情提要: Paas(平台及服务)公司Heroku是个可以把我们写好的App部署到网际网络的好地方.而本篇是我从自己的上一篇文章:将Ruby on Rails项目部署到Heroku遇到的问题,当时困扰 ...
- POJ-1797.HeavyTransportation(最长路中的最小权值)
本题思路:最短路变形,改变松弛方式即可,dist存的是源结点到当前结点的最长路的最小权值. 参考代码: #include <cstdio> #include <cstring> ...
- vue获取后台图片验证码,并点击刷新验证码
<--url为需要访问的接口地址--> <span style="display: inline-block;width: 130px;height: 53px;borde ...
- IIC基本概念和基本时序
1. IIC基本概念和基本时序 1.1 I2C串行总线概述 I2C总线是PHLIPS公司推出的一种串行总线,是具备多主机系统所需的包括总线裁决和高低速器件同步功能的高性能串行总线. 1.I2C总线具有 ...
- VMware虚拟机配置端口转发(端口映射),实现远程访问【转】
前言本文所写的远程为各个电脑在同一个网段内 本文主要详细介绍如何远程访问虚拟机里面的项目! 机器:虚拟机(装在电脑1里).电脑1(宿主机).电脑2.电脑3.电脑4.电脑n... 操作步骤: step1 ...
- 134. Gas Station加油站
[抄题]: There are N gas stations along a circular route, where the amount of gas at station i is gas[i ...
- java通过年月得到该月每一天的日期
public static List<String> getDayByMonth(int yearParam,int monthParam){ List<String> lis ...
- (O)WEB:前端网站性能优化(原创)
*从理论.实战编码.实战调试3个方面学习前端性能优化(包括页面加载时间和页面流畅度): -------------------------------理论----------------------- ...