团队-爬取豆瓣电影TOP250-开发环境搭建过程
从官网下载安装包(http://www.python.org)。

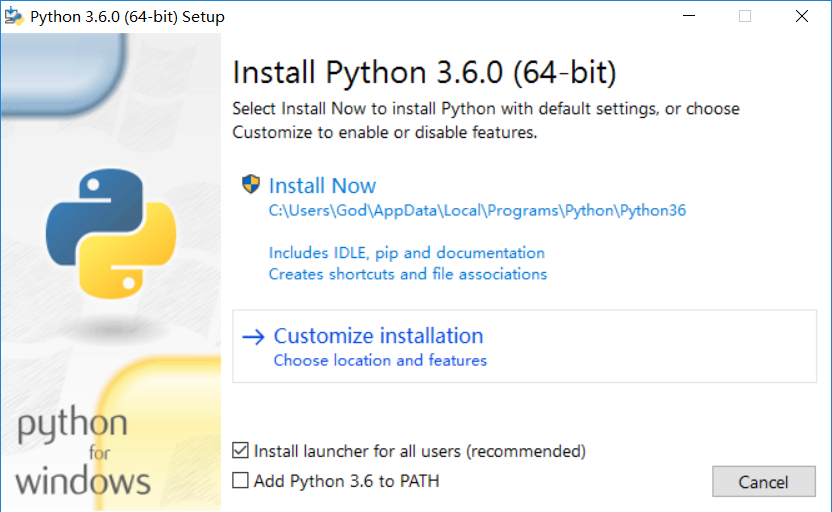
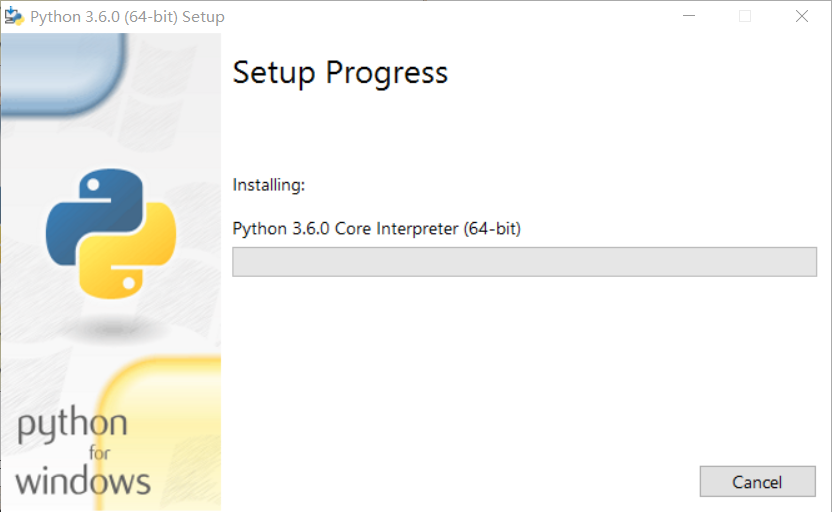
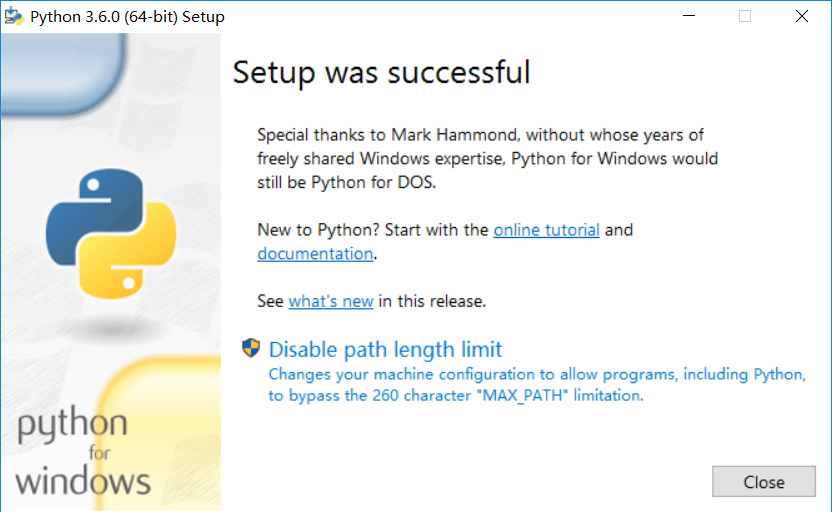
安装Python
选择安装路径(我选的默认)
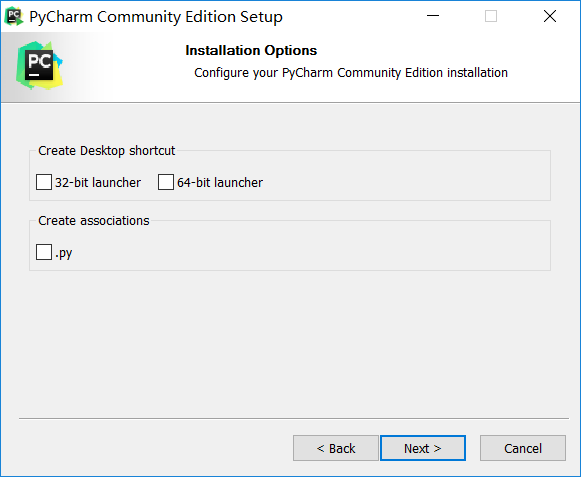
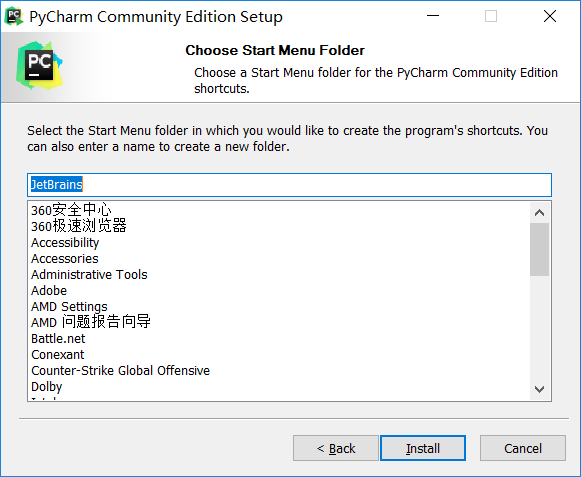
安装Pycharm
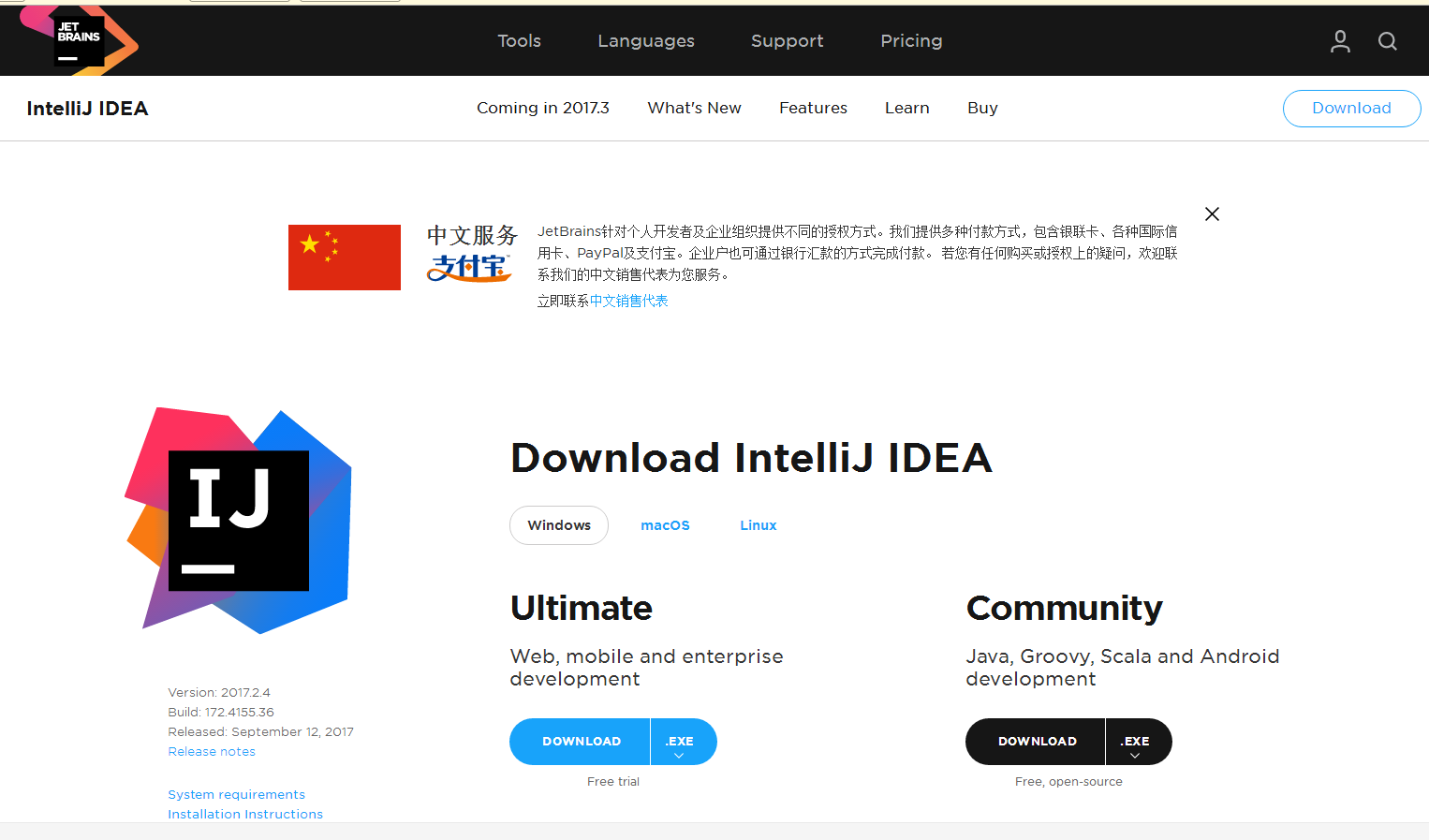
1.从官网下载安装包(https://www.jetbrains.com)。


团队-爬取豆瓣电影TOP250-开发环境搭建过程的更多相关文章
- scrapy爬虫框架教程(二)-- 爬取豆瓣电影TOP250
scrapy爬虫框架教程(二)-- 爬取豆瓣电影TOP250 前言 经过上一篇教程我们已经大致了解了Scrapy的基本情况,并写了一个简单的小demo.这次我会以爬取豆瓣电影TOP250为例进一步为大 ...
- urllib+BeautifulSoup无登录模式爬取豆瓣电影Top250
对于简单的爬虫任务,尤其对于初学者,urllib+BeautifulSoup足以满足大部分的任务. 1.urllib是Python3自带的库,不需要安装,但是BeautifulSoup却是需要安装的. ...
- python2.7爬取豆瓣电影top250并写入到TXT,Excel,MySQL数据库
python2.7爬取豆瓣电影top250并分别写入到TXT,Excel,MySQL数据库 1.任务 爬取豆瓣电影top250 以txt文件保存 以Excel文档保存 将数据录入数据库 2.分析 电影 ...
- scrapy爬取豆瓣电影top250
# -*- coding: utf-8 -*- # scrapy爬取豆瓣电影top250 import scrapy from douban.items import DoubanItem class ...
- 一起学爬虫——通过爬取豆瓣电影top250学习requests库的使用
学习一门技术最快的方式是做项目,在做项目的过程中对相关的技术查漏补缺. 本文通过爬取豆瓣top250电影学习python requests的使用. 1.准备工作 在pycharm中安装request库 ...
- python 爬虫&爬取豆瓣电影top250
爬取豆瓣电影top250from urllib.request import * #导入所有的request,urllib相当于一个文件夹,用到它里面的方法requestfrom lxml impor ...
- 【转】爬取豆瓣电影top250提取电影分类进行数据分析
一.爬取网页,获取需要内容 我们今天要爬取的是豆瓣电影top250页面如下所示: 我们需要的是里面的电影分类,通过查看源代码观察可以分析出我们需要的东西.直接进入主题吧! 知道我们需要的内容在哪里了, ...
- Scrapy中用xpath/css爬取豆瓣电影Top250:解决403HTTP status code is not handled or not allowed
好吧,我又开始折腾豆瓣电影top250了,只是想试试各种方法,看看哪一种的方法效率是最好的,一直进行到这一步才知道 scrapy的强大,尤其是和selector结合之后,速度飞起.... 下面我就采用 ...
- Python爬虫入门:爬取豆瓣电影TOP250
一个很简单的爬虫. 从这里学习的,解释的挺好的:https://xlzd.me/2015/12/16/python-crawler-03 分享写这个代码用到了的学习的链接: BeautifulSoup ...
随机推荐
- Linux下安装MySQL----来自简书(挺好的)
来自简书的: https://www.jianshu.com/p/f4a98a905011 注: 1. 下载方式: 可以使用命令下载: wget http://downloads.mysql.com/ ...
- Promise的实现原理
1.Promise 介绍 Promise类似一个事务管理器,将用户异步操作流程用流水的形式来表达,用来延迟deferred和异步asynchronous. 特点如下: (1)对象的状态不受外界影响 P ...
- 谷歌浏览器内核Cef js代码整理(一)
尊重作者原创,未经作者允许不得转载!作者:xtfnpgy,原文地址: https://www.cnblogs.com/xtfnpgy/p/9285359.html 一.js基础知识 <!-- ...
- Kafka介绍与消息队列
消息队列的好处: 消息队列(Message Queue) 消息: 网络中的两台计算机或者两个通讯设备之间传递的数据.例如说:文本.音乐.视频等内容. 队列:一种特殊的线性表(数据元素首尾相接),特殊之 ...
- 【阿里云服务器】外网无法访问tomcat下部署的项目
问题提出:在ESC实例上部署了jdk和tomcat(略,上云了,上云了),启动tomct后,内网可以访问8080端口,外网无法访问8080. 系统环境:winsdow 2008 企业版 解决方案: 在 ...
- python3:实现字符串的全排列(无重复字符)
最近在学一些基础的算法,发现我的数学功底太差劲了,特别是大学的这一部分,概率论.线性代数.高数等等,这些大学学的我是忘得一干二净(我当时学的时候也不见得真的懂),导致现在学习算法,非常的吃力.唉!不说 ...
- 数据库设计,表与表的关系,一对多。One-To-Many(2)
一对多:主键数据表中只能包含一个记录,而在其关系记录表中这条记录可以与一个或多个记录相关,也可以没有记录与之相关. 关联映射:一对多/多对一存在最普遍的映射关系,简单来讲就如球员与球队的关系:一对多: ...
- SVG绘制太极图
思路:先画一整个圆,填充颜色为黑色,再用一个边框和填充颜色均为白色的长方形覆盖右半边的半圆,再以同一个圆心,相同半径绘制一整个圆,该圆的边线颜色为黑色,没有填充颜色,最后常规操作再画四个小圆 源代码: ...
- 关于深度学习中的batch_size
5.4.1 关于深度学习中的batch_size 举个例子: 例如,假设您有1050个训练样本,并且您希望设置batch_size等于100.该算法从训练数据集中获取前100个样本(从第1到第100个 ...
- Linux firewalld使用教程+rhce课程实验
--timeout= 设置规则生效300秒 调试阶段使用,防止规则设置错误导致无法远程连接 实验:在server0机器上部署httpd服务,通过添加富规则,只允许172.25.0.10/32访问,并且 ...