团队-爬取豆瓣电影TOP250-开发环境搭建过程
从官网下载安装包(http://www.python.org)。

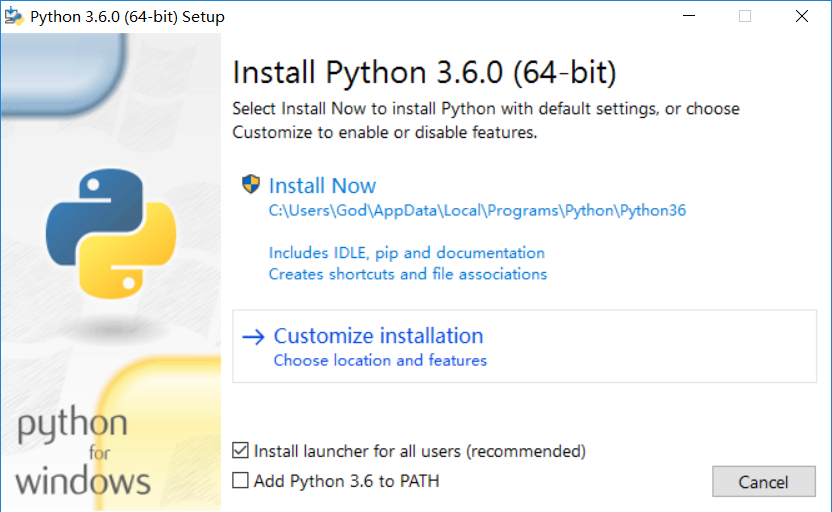
安装Python
选择安装路径(我选的默认)
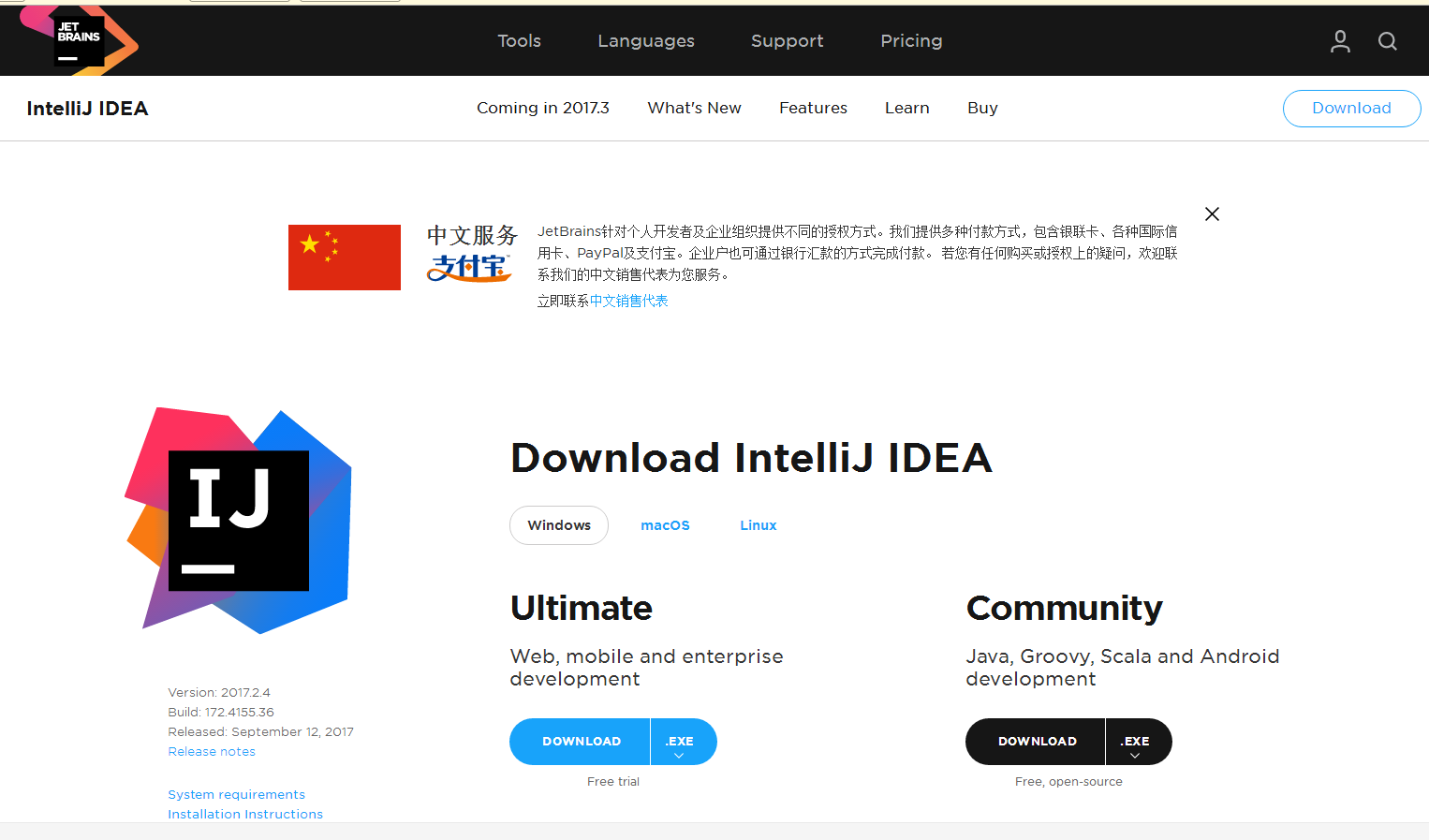
安装Pycharm
1.从官网下载安装包(https://www.jetbrains.com)。


团队-爬取豆瓣电影TOP250-开发环境搭建过程的更多相关文章
- scrapy爬虫框架教程(二)-- 爬取豆瓣电影TOP250
scrapy爬虫框架教程(二)-- 爬取豆瓣电影TOP250 前言 经过上一篇教程我们已经大致了解了Scrapy的基本情况,并写了一个简单的小demo.这次我会以爬取豆瓣电影TOP250为例进一步为大 ...
- urllib+BeautifulSoup无登录模式爬取豆瓣电影Top250
对于简单的爬虫任务,尤其对于初学者,urllib+BeautifulSoup足以满足大部分的任务. 1.urllib是Python3自带的库,不需要安装,但是BeautifulSoup却是需要安装的. ...
- python2.7爬取豆瓣电影top250并写入到TXT,Excel,MySQL数据库
python2.7爬取豆瓣电影top250并分别写入到TXT,Excel,MySQL数据库 1.任务 爬取豆瓣电影top250 以txt文件保存 以Excel文档保存 将数据录入数据库 2.分析 电影 ...
- scrapy爬取豆瓣电影top250
# -*- coding: utf-8 -*- # scrapy爬取豆瓣电影top250 import scrapy from douban.items import DoubanItem class ...
- 一起学爬虫——通过爬取豆瓣电影top250学习requests库的使用
学习一门技术最快的方式是做项目,在做项目的过程中对相关的技术查漏补缺. 本文通过爬取豆瓣top250电影学习python requests的使用. 1.准备工作 在pycharm中安装request库 ...
- python 爬虫&爬取豆瓣电影top250
爬取豆瓣电影top250from urllib.request import * #导入所有的request,urllib相当于一个文件夹,用到它里面的方法requestfrom lxml impor ...
- 【转】爬取豆瓣电影top250提取电影分类进行数据分析
一.爬取网页,获取需要内容 我们今天要爬取的是豆瓣电影top250页面如下所示: 我们需要的是里面的电影分类,通过查看源代码观察可以分析出我们需要的东西.直接进入主题吧! 知道我们需要的内容在哪里了, ...
- Scrapy中用xpath/css爬取豆瓣电影Top250:解决403HTTP status code is not handled or not allowed
好吧,我又开始折腾豆瓣电影top250了,只是想试试各种方法,看看哪一种的方法效率是最好的,一直进行到这一步才知道 scrapy的强大,尤其是和selector结合之后,速度飞起.... 下面我就采用 ...
- Python爬虫入门:爬取豆瓣电影TOP250
一个很简单的爬虫. 从这里学习的,解释的挺好的:https://xlzd.me/2015/12/16/python-crawler-03 分享写这个代码用到了的学习的链接: BeautifulSoup ...
随机推荐
- 20175227张雪莹 2018-2019-2 《Java程序设计》第三周学习总结
20175227张雪莹 2018-2019-2 <Java程序设计>第三周学习总结 教材学习内容总结 (仅在此列举个性化学习总结) 一.编程语言的几个发展阶段. 1.面向机器语言:汇编语言 ...
- MFC 中CString 格式16进制转int 十进制
代码:CString v_hex ; int v_dec; v_dec = wcstol(v_hex, NULL, 16);
- 性能测试day04_性能监控
好了,今天接着来学习性能,在今天开始前,我今天在网上又看到了理发师经典模型,这里稍微提一下,详情可以百度哈,下面这张图是网上找到的经典场景性能相关的图,大致说明下: 这张图中展示的是1个标准的软件性能 ...
- 协程,greenlet,gevent
""" 协程 """ ''' 协程: 类似于一个可以暂停的函数,可以多次传入数据,可以多次返回数据 协程是可交互的 耗资源大小:进程 --& ...
- 实战ELK(3) Kibana安装与简单实用
第一步:下载 https://artifacts.elastic.co/downloads/kibana/kibana-6.5.1-x86_64.rpm 第二步:安装 1.安装 yum install ...
- !!字体图标(iconfont、Fontello 、雪碧图生成工具。Glyphicons、fontawesome 等)。 图片压缩
http://www.iconfont.cn/ 阿里巴巴矢量图标库 iconfont http://fontawesome.io fontawesome图标 http://www.bootcss.c ...
- V2Ray断流异常
V2Ray断流异常 1. 问题描述 最近一段时间发现,代理十分不稳定,经常出现“断流”,具体表现为:打开需要代理的站点,需要访问两次,第一次访问失败,需要再刷新一次.查看错误日志内容: Proxy ...
- A CLOSER LOOK AT CSS
A CLOSER LOOK AT CSS css-review Congratulations! You worked hard and made it to the end of a challen ...
- Vue开源项目汇总(史上最全)(转)
目录 UI组件 开发框架 实用库 服务端 辅助工具 应用实例 Demo示例 UI组件 element ★13489 - 饿了么出品的Vue2的web UI工具套件 Vux ★8133 - 基于Vue和 ...
- nexus的安装和简介(3)
从私服下载jar包 没有配置nexus之前,如果本地仓库没有,去中央仓库下载,通常在企业中会在局域网内部署一台私服服务器,有了私服本地项目首先去本地仓库找jar,如果没有找到则连接私服从私服下载ja ...