Hadoop2之NameNode HA详解
在Hadoop1中NameNode存在一个单点故障问题,如果NameNode所在的机器发生故障,整个集群就将不可用(Hadoop1中虽然有个SecorndaryNameNode,但是它并不是NameNode的备份,它只是NameNode的一个助理,协助NameNode工作,SecorndaryNameNode会对fsimage和edits文件进行合并,并推送给NameNode,防止因edits文件过大,导致NameNode重启变慢),这是Hadoop1的不可靠实现。
在Hadoop2中这个问题得以解决,Hadoop2中的高可靠性是指同时启动NameNode,其中一个处于active工作状态,另外一个处于随时待命standby状态。这样,当一个NameNode所在的服务器宕机时,可以在数据不丢失的情况下, 手工或者自动切换到另一个NameNode提供服务。
这些NameNode之间通过共享数据,保证数据的状态一致。多个NameNode之间共享数据,可以通过Network File System或者Quorum Journal Node。前者是通过Linux共享的文件系统,属于操作系统的配置;后者是Hadoop自身的东西,属于软件的配置。
我们这里讲述使用Quorum Journal Node的配置方式,方式是手工切换。
集群启动时,可以同时启动2个NameNode。这些NameNode只有一个是active的,另一个属于standby状态。active状态意味着提供服务,standby状态意味着处于休眠状态,只进行数据同步,时刻准备着提供服务,如图2所示。
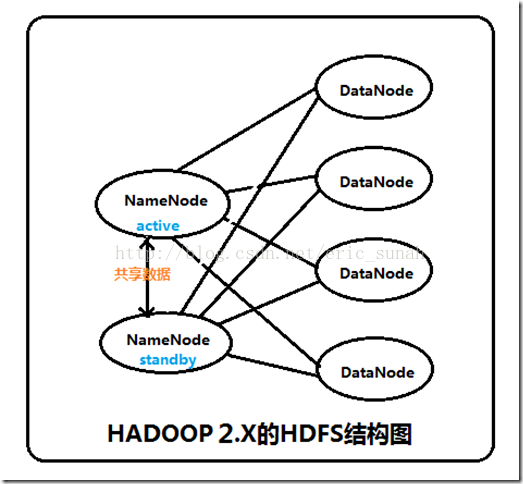
图2
架构
在一个典型的HA集群中,每个NameNode是一台独立的服务器。在任一时刻,只有一个NameNode处于active状态,另一个处于standby状态。其中,active状态的NameNode负责所有的客户端操作,standby状态的NameNode处于从属地位,维护着数据状态,随时准备切换。
两个NameNode为了数据同步,会通过一组称作JournalNodes的独立进程进行相互通信。当active状态的NameNode的命名空间有任何修改时,会告知大部分的JournalNodes进程。standby状态的NameNode有能力读取JNs中的变更信息,并且一直监控edit log的变化,把变化应用于自己的命名空间。standby可以确保在集群出错时,命名空间状态已经完全同步了,如图3所示。
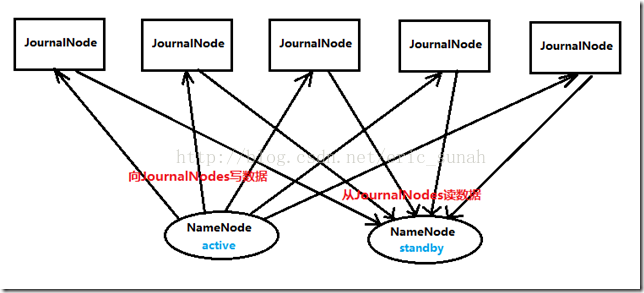
图3
为了确保快速切换,standby状态的NameNode有必要知道集群中所有数据块的位置。为了做到这点,所有的datanodes必须配置两个NameNode的地址,发送数据块位置信息和心跳给他们两个。
对于HA集群而言,确保同一时刻只有一个NameNode处于active状态是至关重要的。否则,两个NameNode的数据状态就会产生分歧,可能丢失数据,或者产生错误的结果。为了保证这点,JNs必须确保同一时刻只有一个NameNode可以向自己写数据。
硬件资源
为了部署HA集群,应该准备以下事情:
* NameNode服务器:运行NameNode的服务器应该有相同的硬件配置。
* JournalNode服务器:运行的JournalNode进程非常轻量,可以部署在其他的服务器上。注意:必须允许至少3个节点。当然可以运行更多,但是必须是奇数个,如3、5、7、9个等等。当运行N个节点时,系统可以容忍至少(N-1)/2个节点失败而不影响正常运行。
在HA集群中,standby状态的NameNode可以完成checkpoint操作,因此没必要配置Secondary NameNode、CheckpointNode、BackupNode。如果真的配置了,还会报错。
配置
HA集群需要使用nameservice ID区分一个HDFS集群。另外,HA中还要使用一个词,叫做NameNode ID。同一个集群中的不同NameNode,使用不同的NameNode ID区分。为了支持所有NameNode使用相同的配置文件,因此在配置参数中,需要把“nameservice ID”作为NameNode ID的前缀。
HA配置内容是在文件hdfs-site.xml中的。下面介绍关键配置项。
dfs.nameservices 命名空间的逻辑名称。如果使用HDFS Federation,可以配置多个命名空间的名称,使用逗号分开即可。
<property>
<name>dfs.nameservices</name>
<value>mycluster</value>
</property>
dfs.ha.namenodes.[nameservice ID] 命名空间中所有NameNode的唯一标示名称。可以配置多个,使用逗号分隔。该名称是可以让DataNode知道每个集群的所有NameNode。当前,每个集群最多只能配置两个NameNode。
<property>
<name>dfs.ha.namenodes.mycluster</name>
<value>nn1,nn2</value>
</property>
dfs.namenode.rpc-address.[nameservice ID].[name node ID] 每个namenode监听的RPC地址。如下所示
<property>
<name>dfs.namenode.rpc-address.mycluster.nn1</name>
<value>machine1.example.com:8020</value>
</property>
<property>
<name>dfs.namenode.rpc-address.mycluster.nn2</name>
<value>machine2.example.com:8020</value>
</property>
dfs.namenode.http-address.[nameservice ID].[name node ID] 每个namenode监听的http地址。如下所示
<property>
<name>dfs.namenode.http-address.mycluster.nn1</name>
<value>machine1.example.com:50070</value>
</property>
<property>
<name>dfs.namenode.http-address.mycluster.nn2</name>
<value>machine2.example.com:50070</value>
</property>
如果启用了安全策略,也应该对每个namenode配置htts-address信息,与此类似。
dfs.namenode.shared.edits.dir 这是NameNode读写JNs组的uri。通过这个uri,NameNodes可以读写edit log内容。URI的格式"qjournal://host1:port1;host2:port2;host3:port3/journalId"。这里的host1、host2、host3指的是Journal Node的地址,这里必须是奇数个,至少3个;其中journalId是集群的唯一标识符,对于多个联邦命名空间,也使用同一个journalId。配置如下
<property>
<name>dfs.namenode.shared.edits.dir</name>
<value>qjournal://node1.example.com:8485;node2.example.com:8485;node3.example.com:8485/mycluster</value>
</property>
这里配置HDFS客户端连接到Active NameNode的一个java类
<property>
<name>dfs.client.failover.proxy.provider.mycluster</name>
<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value>
</property>
dfs.ha.fencing.methods 配置active namenode出错时的处理类。当active namenode出错时,一般需要关闭该进程。处理方式可以是ssh也可以是shell。
如果使用ssh,配置如下
<property>
<name>dfs.ha.fencing.methods</name>
<value>sshfence</value>
</property> <property>
<name>dfs.ha.fencing.ssh.private-key-files</name>
<value>/home/exampleuser/.ssh/id_rsa</value>
</property>
这种方法配置简单,推荐使用。
fs.defaultFS 客户端连接HDFS时,默认的路径前缀。如果前面配置了nameservice ID的值是mycluster,那么这里可以配置为授权信息的一部分
可以在core-site.xml中配置如下
<property>
<name>fs.defaultFS</name>
<value>hdfs://mycluster</value>
</property>
dfs.journalnode.edits.dir 这是JournalNode进程保持逻辑状态的路径。这是在linux服务器文件的绝对路径。
<property>
<name>dfs.journalnode.edits.dir</name>
<value>/path/to/journal/node/local/data</value>
</property>
部署
以上配置完成后,就可以启动JournalNode进程了。在各个JournalNode机器上执行命令“hadoop-daemon.sh journalnode”。
如果是一个新的HDFS集群,还要首先执行格式化命令“hdfs namenode -format”,紧接着启动本NameNode进程。
如果存在一个已经格式化过的NameNode,并且已经启动了。那么应该把该NameNode的数据同步到另一个没有格式化的NameNode。在未格式化过的NameNode上执行命令“hdfs namenode -bootstrapStandby”。
如果是把一个非HA集群转成HA集群,应该运行命令“hdfs –initializeSharedEdits”,这会初始化JournalNode中的数据。
做了这些事情后,就可以启动两个NameNode了。启动成功后,通过web页面观察两个NameNode的状态,都是standby。
下面执行命令“hdfs haadmin -failover --forcefence serviceId serviceId2”。就会把NameNode的状态进行安全的切换。其中后面一个会变为active状态。这时候再通过web页面观察就能看到正确结果了
Hadoop2之NameNode HA详解的更多相关文章
- Hadoop2.0 Namenode HA实现方案
Hadoop2.0 Namenode HA实现方案介绍及汇总 基于社区最新release的Hadoop2.2.0版本,调研了hadoop HA方面的内容.hadoop2.0主要的新特性(Hadoop2 ...
- HDFS NameNode内存详解
前言 <HDFS NameNode内存全景>中,我们从NameNode内部数据结构的视角,对它的内存全景及几个关键数据结构进行了简单解读,并结合实际场景介绍了NameNode可能遇到的问题 ...
- hadoop2.7作业提交详解之文件分片
在前面一篇文章中(hadoop2.7之作业提交详解(上))中涉及到文件的分片. JobSubmitter.submitJobInternal方法中调用了int maps = writeSplits(j ...
- hadoop HA 详解
NameNode 高可用整体架构概述 在 Hadoop 1.0 时代,Hadoop 的两大核心组件 HDFS NameNode 和 JobTracker 都存在着单点问题,这其中以 NameNode ...
- HDFS2.0架构以及HA详解
HDFS2.0概述 一背景,Hadoop1.0中HDFS和MapReduce在高可用,扩展性等方面存在问题 HDFS存在问题,1,NameNode单点故障,难以应用于在线场景.2,NameNod ...
- CentOS7下用jdk1.7编译hadoop-2.7.1全过程详解
说实话,本人编译hadoop的过程比较曲折,但收获也很多,下面系统介绍一下CentOS7下编译hadoop-2.7.1的全过程吧. 先说明,32位Linux操作系统可以直接下载编译好的hadoop使用 ...
- hadoop2——新MapReduces——yarm详解
YARN总体上仍然是Master/Slave结构,在整个资源管理框架中,ResourceManager为Master,NodeManager为Slave,ResourceManager负责对各个Nod ...
- 【转载】VMware vSphere 5 HA详解 1
很久没有动笔写博客了.总算最近的几项工作告一段落,对iOS和Android的折腾也兴趣稍退,该写点技术博客了. 想写一篇关于VMware HA的博客由来已久,曾经做了些功课,查了不少资料,写了点笔记, ...
- Prometheus HA详解
Prometheus 横向扩展 当Exporter或者采集信息需要越来越多时就会考虑高可用,高可用优点不会因为集群中某个节点down而导致Prometheus不可用,可以让算力下沉; 缺点是A-Pro ...
随机推荐
- mysql表管理
4.1 查看所有表 查看所有表语句: show tables; 例: mysql> show tables; +-----------------+ | Tables_in_emp | +--- ...
- Nessus忘记密码的解决
进入到Nessus安装目录下
- python词云
词云图 from os import path from PIL import Image import numpy as np import matplotlib.pyplot as plt fro ...
- web前端中navigator
<script> if(navigator.cookieEnabled){ document.write("浏览器已启用cookie,请妥善保存个人信息"); }els ...
- BZOJ3393 [Usaco2009 Jan]Laserphones 激光通讯 BFS
原文链接http://www.cnblogs.com/zhouzhendong/p/8371735.html 题目传送门 - BZOJ3393 题意概括 直接看原题的翻译吧,很容易懂的. 题解 我不知 ...
- asp.net core 使用docker默认端口修改
默认端口是80 在dockerfile文件中修改 ENV ASPNETCORE_URLS http://+:80 ------------------------------------------- ...
- Python交互图表可视化Bokeh:5 柱状图| 堆叠图| 直方图
柱状图/堆叠图/直方图 ① 单系列柱状图② 多系列柱状图③ 堆叠图④ 直方图 1.单系列柱状图 import numpy as np import pandas as pd import matplo ...
- sql union 列的字段不一样的时候
- Java字符串处理
代码: import java.util.Scanner; public class Main { public static void main(String[] args) { Scanner s ...
- ssh centos 上传文件
ssh centos 上传文件命令(ftp开不起的情报况下): rz -be 下载文件: sz