亿级 ELK 日志平台构建部署实践
本篇主要讲工作中的真实经历,我们怎么打造亿级日志平台,同时手把手教大家建立起这样一套亿级 ELK 系统。日志平台具体发展历程可以参考上篇 「从 ELK 到 EFK 演进」
废话不多说,老司机们座好了,我们准备发车了~~~
整体架构
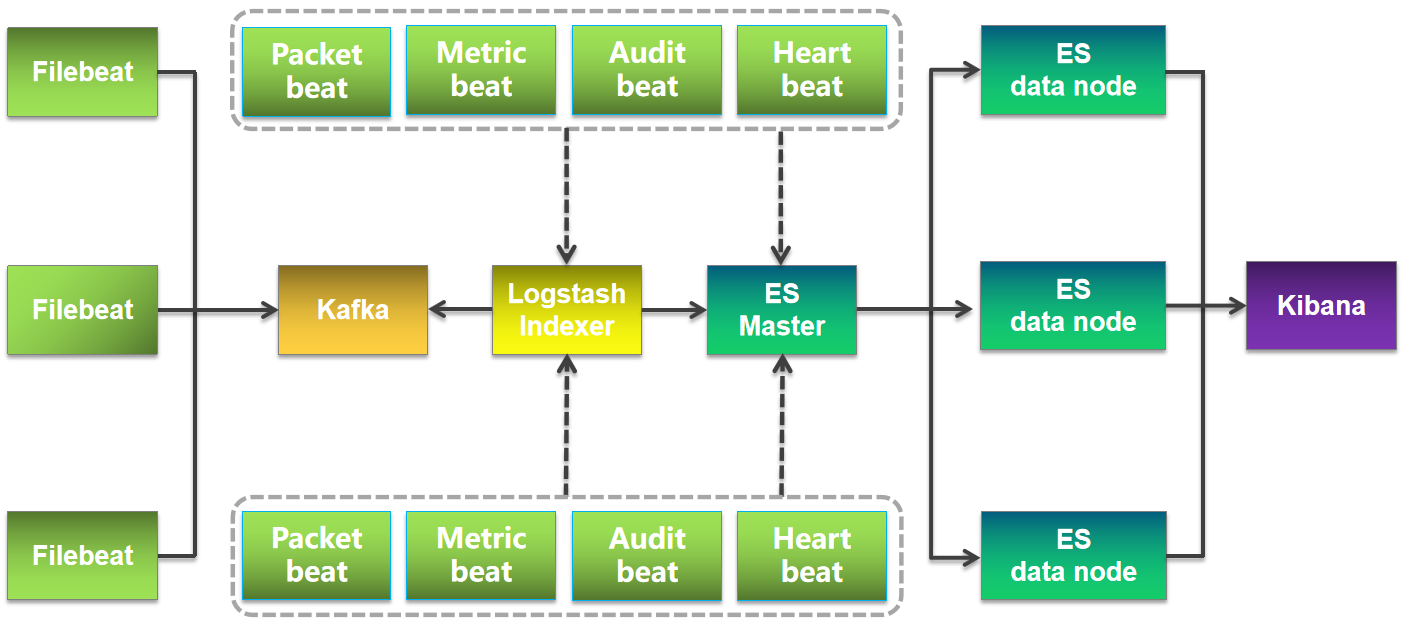
整体架构主要分为 4 个模块,分别提供不同的功能
Filebeat:轻量级数据收集引擎。基于原先 Logstash-fowarder 的源码改造出来。换句话说:Filebeat就是新版的 Logstash-fowarder,也会是 ELK Stack 在 Agent 的第一选择。
Kafka: 数据缓冲队列。作为消息队列解耦了处理过程,同时提高了可扩展性。具有峰值处理能力,使用消息队列能够使关键组件顶住突发的访问压力,而不会因为突发的超负荷的请求而完全崩溃。
Logstash :数据收集处理引擎。支持动态的从各种数据源搜集数据,并对数据进行过滤、分析、丰富、统一格式等操作,然后存储以供后续使用。
Elasticsearch :分布式搜索引擎。具有高可伸缩、高可靠、易管理等特点。可以用于全文检索、结构化检索和分析,并能将这三者结合起来。Elasticsearch 基于 Lucene 开发,现在使用最广的开源搜索引擎之一,Wikipedia 、StackOverflow、Github 等都基于它来构建自己的搜索引擎。
Kibana :可视化化平台。它能够搜索、展示存储在 Elasticsearch 中索引数据。使用它可以很方便的用图表、表格、地图展示和分析数据。
版本说明
Filebeat: 6.2.4
Kafka: 2.11-1
Logstash: 6.2.4
Elasticsearch: 6.2.4
Kibana: 6.2.4
相应的版本最好下载对应的插件具体实践
我们就以比较常见的 Nginx 日志来举例说明下,日志内容是 JSON 格式
{"@timestamp":"2017-12-27T16:38:17+08:00","host":"192.168.56.11","clientip":"192.168.56.11","size":26,"responsetime":0.000,"upstreamtime":"-","upstreamhost":"-","http_host":"192.168.56.11","url":"/nginxweb/index.html","domain":"192.168.56.11","xff":"-","referer":"-","status":"200"}
{"@timestamp":"2017-12-27T16:38:17+08:00","host":"192.168.56.11","clientip":"192.168.56.11","size":26,"responsetime":0.000,"upstreamtime":"-","upstreamhost":"-","http_host":"192.168.56.11","url":"/nginxweb/index.html","domain":"192.168.56.11","xff":"-","referer":"-","status":"200"}
{"@timestamp":"2017-12-27T16:38:17+08:00","host":"192.168.56.11","clientip":"192.168.56.11","size":26,"responsetime":0.000,"upstreamtime":"-","upstreamhost":"-","http_host":"192.168.56.11","url":"/nginxweb/index.html","domain":"192.168.56.11","xff":"-","referer":"-","status":"200"}
{"@timestamp":"2017-12-27T16:38:17+08:00","host":"192.168.56.11","clientip":"192.168.56.11","size":26,"responsetime":0.000,"upstreamtime":"-","upstreamhost":"-","http_host":"192.168.56.11","url":"/nginxweb/index.html","domain":"192.168.56.11","xff":"-","referer":"-","status":"200"}
{"@timestamp":"2017-12-27T16:38:17+08:00","host":"192.168.56.11","clientip":"192.168.56.11","size":26,"responsetime":0.000,"upstreamtime":"-","upstreamhost":"-","http_host":"192.168.56.11","url":"/nginxweb/index.html","domain":"192.168.56.11","xff":"-","referer":"-","status":"200"}Filebeat
为什么用 Filebeat ,而不用原来的 Logstash 呢?
原因很简单,资源消耗比较大。
由于 Logstash 是跑在 JVM 上面,资源消耗比较大,后来作者用 GO 写了一个功能较少但是资源消耗也小的轻量级的 Agent 叫 Logstash-forwarder。
后来作者加入 elastic.co 公司, Logstash-forwarder 的开发工作给公司内部 GO 团队来搞,最后命名为 Filebeat。
Filebeat 需要部署在每台应用服务器上,可以通过 Salt 来推送并安装配置。
下载
$ wget https://artifacts.elastic.co/downloads/beats/filebeat/filebeat-6.2.4-darwin-x86_64.tar.gz解压
tar -zxvf filebeat-6.2.4-darwin-x86_64.tar.gz
mv filebeat-6.2.4-darwin-x86_64 filebeat
cd filebeat修改配置
修改 Filebeat 配置,支持收集本地目录日志,并输出日志到 Kafka 集群中
$ vim fileat.yml
filebeat.prospectors:
- input_type: log
paths:
- /opt/logs/server/nginx.log
json.keys_under_root: true
json.add_error_key: true
json.message_key: log
output.kafka:
hosts: ["192.168.0.1:9092","192.168.0.2:9092","192.168.0.3:9092"]
topic: 'nginx'
Filebeat 6.0 之后一些配置参数变动比较大,比如 document_type 就不支持,需要用 fields 来代替等等。
启动
$ ./filebeat -e -c filebeat.yml
Kafka
生产环境中 Kafka 集群中节点数量建议为(2N + 1 )个,这边就以 3 个节点举例
下载
直接到官网下载 Kafka
$ wget http://mirror.bit.edu.cn/apache/kafka/1.0.0/kafka_2.11-1.0.0.tgz解压
tar -zxvf kafka_2.11-1.0.0.tgz
mv kafka_2.11-1.0.0 kafka
cd kafka修改 Zookeeper 配置
修改 Zookeeper 配置,搭建 Zookeeper 集群,数量 ( 2N + 1 ) 个
ZK 集群建议采用 Kafka 自带,减少网络相关的因素干扰
$ vim zookeeper.properties
tickTime=2000
dataDir=/opt/zookeeper
clientPort=2181
maxClientCnxns=50
initLimit=10
syncLimit=5
server.1=192.168.0.1:2888:3888
server.2=192.168.0.2:2888:3888
server.3=192.168.0.3:2888:3888
Zookeeper data 目录下面添加 myid 文件,内容为代表 Zooekeeper 节点 id (1,2,3),并保证不重复
$ vim /opt/zookeeper/myid
1
启动 Zookeeper 节点
分别启动 3 台 Zookeeper 节点,保证集群的高可用
$ ./zookeeper-server-start.sh -daemon ./config/zookeeper.properties修改 Kafka 配置
kafka 集群这边搭建为 3 台,可以逐个修改 Kafka 配置,需要注意其中 broker.id 分别 (1,2,3)
$ vim ./config/server.properties
broker.id=1
port=9092
host.name=192.168.0.1
num.replica.fetchers=1
log.dirs=/opt/kafka_logs
num.partitions=3
zookeeper.connect=192.168.0.1:2181,192.168.0.2:2181,192.168.0.3:2181
zookeeper.connection.timeout.ms=6000
zookeeper.sync.time.ms=2000
num.io.threads=8
num.network.threads=8
queued.max.requests=16
fetch.purgatory.purge.interval.requests=100
producer.purgatory.purge.interval.requests=100
delete.topic.enable=true启动 Kafka 集群
分别启动 3 台 Kafka 节点,保证集群的高可用
$ ./bin/kafka-server-start.sh -daemon ./config/server.properties查看 topic 是否创建成功
$ bin/kafka-topics.sh --list --zookeeper localhost:2181
nginx
监控 Kafka Manager
Kafka-manager 是 Yahoo 公司开源的集群管理工具。
可以在 Github 上下载安装:https://github.com/yahoo/kafka-manager
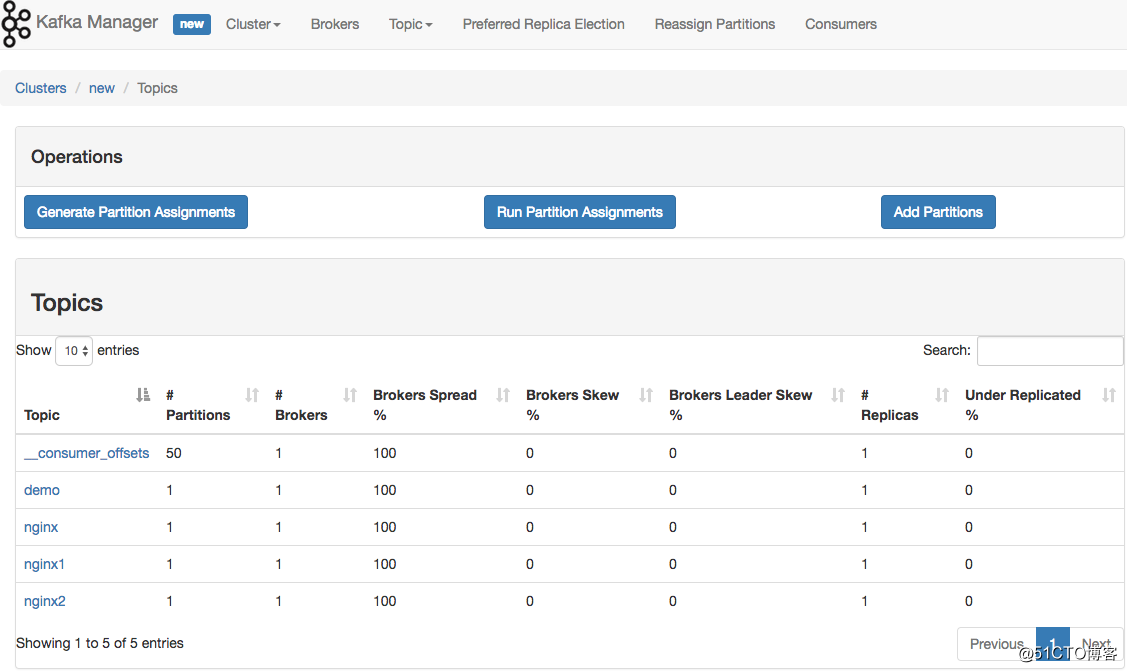
如果遇到 Kafka 消费不及时的话,可以通过到具体 cluster 页面上,增加 partition。Kafka 通过 partition 分区来提高并发消费速度

Logstash
Logstash 提供三大功能
- INPUT 进入
- FILTER 过滤功能
- OUTPUT 出去
如果使用 Filter 功能的话,强烈推荐大家使用 Grok debugger 来预先解析日志格式。
下载
$ wget https://artifacts.elastic.co/downloads/logstash/logstash-6.2.4.tar.gz解压重命名
$ tar -zxvf logstash-6.2.4.tar.gz
$ mv logstash-6.2.4 logstash修改 Logstash 配置
修改 Logstash 配置,使之提供 indexer 的功能,将数据插入到 Elasticsearch 集群中
$ vim nginx.conf
input {
kafka {
type => "kafka"
bootstrap_servers => "192.168.0.1:2181,192.168.0.2:2181,192.168.0.3:2181"
topics => "nginx"
group_id => "logstash"
consumer_threads => 2
}
}
output {
elasticsearch {
host => ["192.168.0.1","192.168.0.2","192.168.0.3"]
port => "9300"
index => "nginx-%{+YYYY.MM.dd}"
}
}启动 Logstash
$ ./bin/logstash -f nginx.confElasticsearch
下载
$ wget https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-6.2.4.tar.gz解压
$ tar -zxvf elasticsearch-6.2.4.tar.gz
$ mv elasticsearch-6.2.4.tar.gz elasticsearch修改配置
$ vim config/elasticsearch.yml
cluster.name: es
node.name: es-node1
network.host: 192.168.0.1
discovery.zen.ping.unicast.hosts: ["192.168.0.1"]
discovery.zen.minimum_master_nodes: 1启动
通过 -d 来后台启动
$ ./bin/elasticsearch -d打开网页 http://192.168.0.1:9200/, 如果出现下面信息说明配置成功
{
name: "es-node1",
cluster_name: "es",
cluster_uuid: "XvoyA_NYTSSV8pJg0Xb23A",
version: {
number: "6.2.4",
build_hash: "ccec39f",
build_date: "2018-04-12T20:37:28.497551Z",
build_snapshot: false,
lucene_version: "7.2.1",
minimum_wire_compatibility_version: "5.6.0",
minimum_index_compatibility_version: "5.0.0"
},
tagline: "You Know, for Search"
}控制台
Cerebro 这个名字大家可能觉得很陌生,其实过去它的名字叫 kopf !因为 Elasticsearch 5.0 不再支持 site plugin,所以 kopf 作者放弃了原项目,另起炉灶搞了 cerebro,以独立的单页应用形式,继续支持新版本下 Elasticsearch 的管理工作。
注意点
- Master 与 Data 节点分离,当 Data 节点大于 3 个的时候,建议责任分离,减轻压力
- Data Node 内存不超过 32G ,建议设置成 31 G ,具体原因可以看上一篇文章
- discovery.zen.minimum_master_nodes 设置成 ( total / 2 + 1 ),避免脑裂情况
- 最重要的一点,不要将 ES 暴露在公网中,建议都安装 X-PACK ,来加强其安全性
kibana
下载
$ wget https://artifacts.elastic.co/downloads/kibana/kibana-6.2.4-darwin-x86_64.tar.gz解压
$ tar -zxvf kibana-6.2.4-darwin-x86_64.tar.gz
$ mv kibana-6.2.4-darwin-x86_64.tar.gz kibana修改配置
$ vim config/kibana.yml
server.port: 5601
server.host: "192.168.0.1"
elasticsearch.url: "http://192.168.0.1:9200"启动 Kibana
$ nohup ./bin/kibana &界面展示
创建索引页面需要到 Management -> Index Patterns 中通过前缀来指定
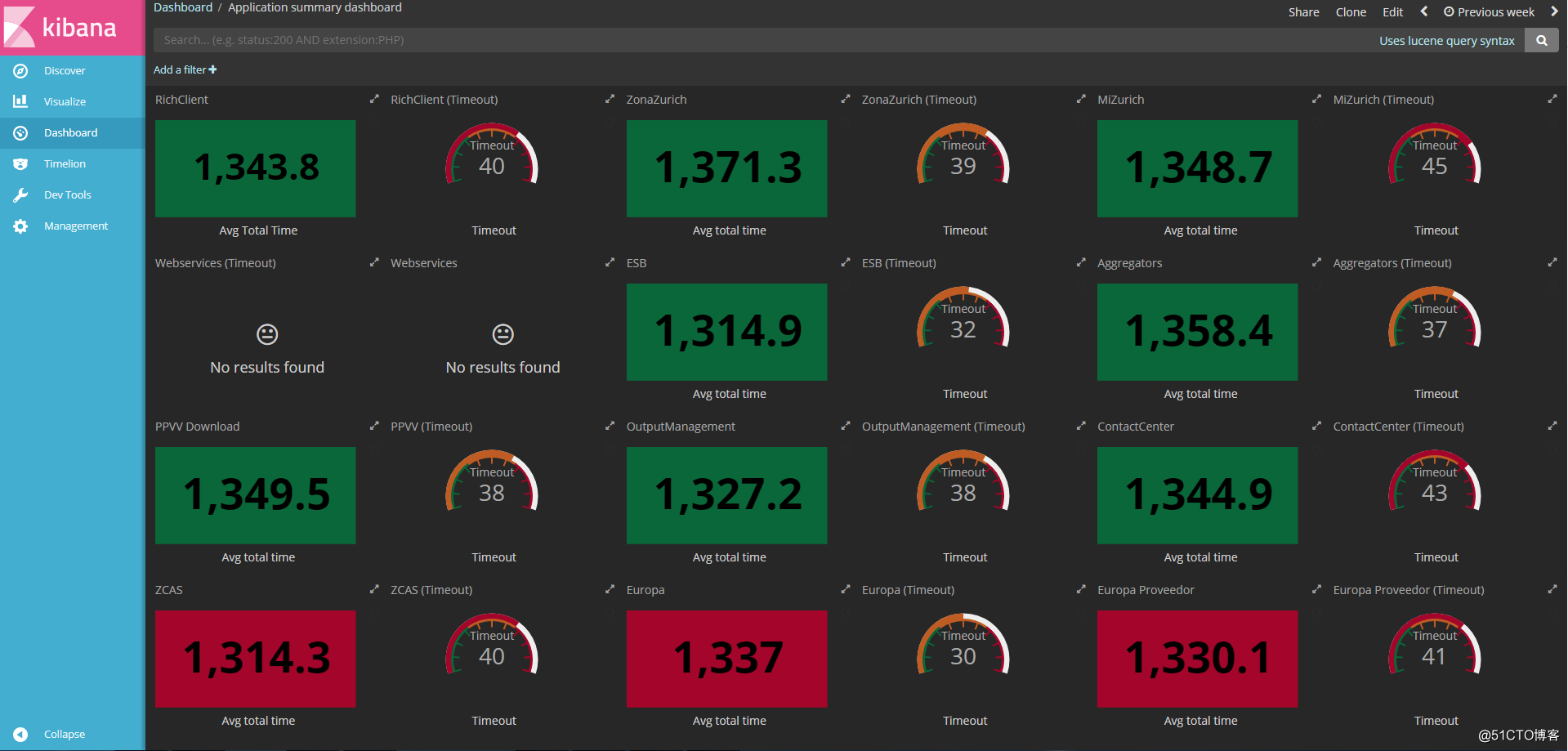
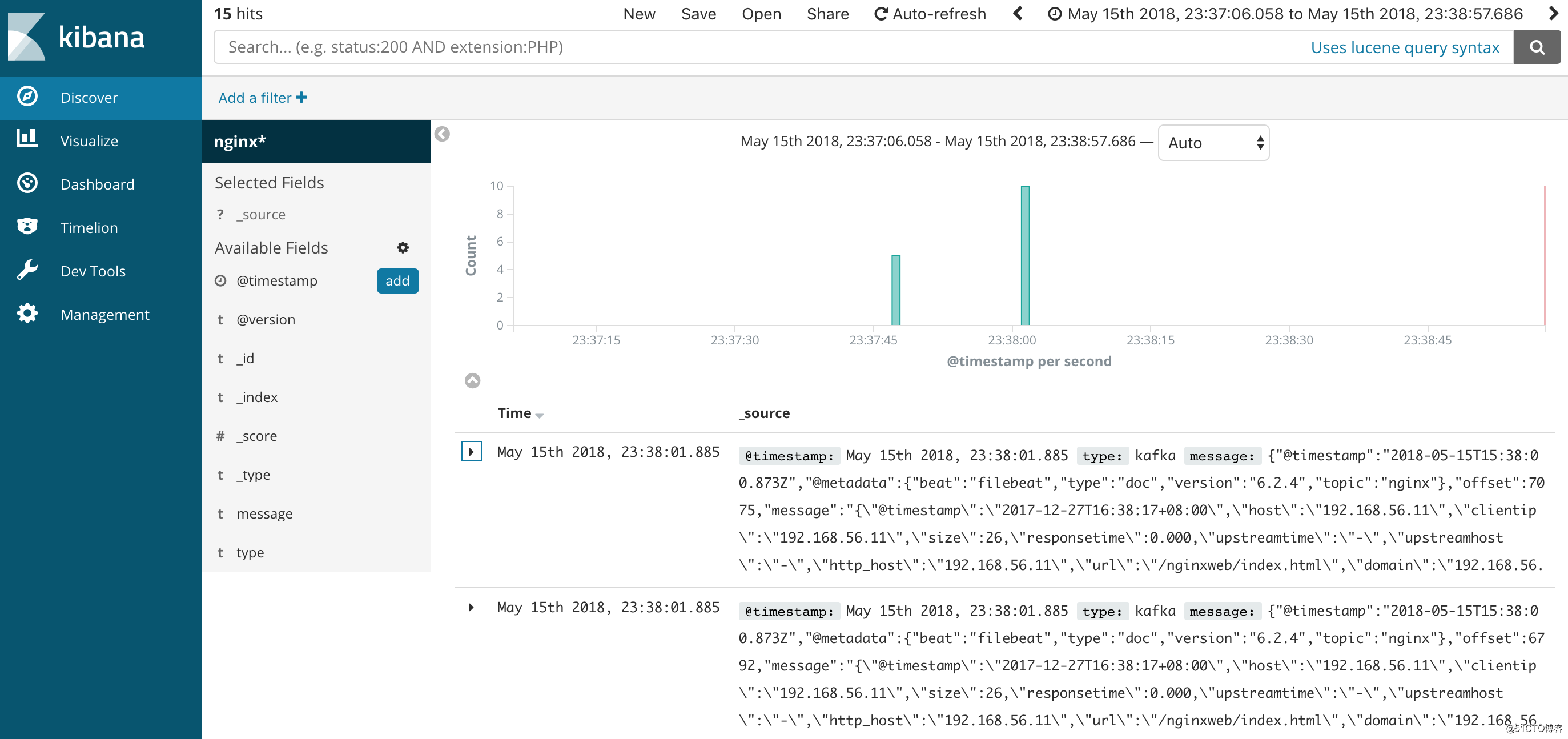
最终效果展示
kibana汉化
github汉化项目:
https://github.com/anbai-inc/Kibana_Hanization
注意:此项目适用于Kibana 5.x-6.x 的任意版本,汉化过程不可逆,汉化前请注意备份!
# 下载并解压
wget https://github.com/anbai-inc/Kibana_Hanization/archive/master.zip
unzip master.zip
cd master
# 汉化
python main.py Kibana目录
# 启动elasticsearch
cd elasticsearch-6.6.0/bin
elasticsearch -d
# 启动kibana
cd kibana-6.6.0-linux-x86_64/bin
kibana
浏览器访问 localhost:5601
总结
综上,通过上面部署命令来实现 ELK 的整套组件,包含了日志收集、过滤、索引和可视化的全部流程,基于这套系统实现分析日志功能。同时,通过水平扩展 Kafka、Elasticsearch 集群,可以实现日均亿级的日志实时处理。
亿级 ELK 日志平台构建部署实践的更多相关文章
- ELK 日志平台构建
elastic中文社区 https://elasticsearch.cn/ 完整参考 ELK实时日志分析平台环境部署--完整记录 https://www.cnblogs.com/kevingrace/ ...
- 阿里PB级Kubernetes日志平台建设实践
干货分享 | 阿里PB级Kubernetes日志平台建设实践https://www.infoq.cn/article/HiIxh-8o0Lm4b3DWKvph 日志最主要的采集工具是 Agent,在 ...
- 转:亿级Web系统的高容错性实践(好博文)
亿级Web系统的高容错性实践 亿级Web系统的高容错性实践 背景介绍 大概三年前,我在腾讯负责的活动运营系统,因为业务流量规模的数倍增长,系统出现了各种各样的异常,当时,作为开发的我,7*24小时地没 ...
- 亿级Web系统的高容错性实践
亿级Web系统的高容错性实践 背景介绍 大概三年前,我在腾讯负责的活动运营系统,因为业务流量规模的数倍增长,系统出现了各种各样的异常,当时,作为开发的我,7*24小时地没日没夜处理告警,周末和凌晨也经 ...
- 升级到php7相关问题,日请求过亿QQ会员活动平台PHP7升级实践
升级到php7相关问题,日请求过亿QQ会员活动平台PHP7升级实践 日请求过亿:QQ会员活动平台PHP7升级实践http://mp.weixin.qq.com/s?__biz=MjM5MjAwODM4 ...
- elk日志平台搭建小记
最近抽出点时间,搭建了新版本的elk日志平台 elastaicsearch 和logstash,kibana和filebeat都是5.6版本的 中间使用redis做缓存,版本为3.2 使用的系统为ce ...
- Springboot项目使用aop切面保存详细日志到ELK日志平台
上一篇讲过了将Springboot项目中logback日志插入到ELK日志平台,它只是个示例.这一篇来看一下实际使用中,我们应该怎样通过aop切面,拦截所有请求日志插入到ELK日志系统.同时,由于往往 ...
- Springboot项目搭配ELK日志平台
上一篇讲过了elasticsearch和kibana的可视化组合查询,这一篇就来看看大名鼎鼎的ELK日志平台是如何搞定的. elasticsearch负责数据的存储和检索,kibana提供图形界面便于 ...
- 亿级Web系统的容错性建设实践(转)
三年多前,我在腾讯负责的活动运营系统,因为业务流量规模的数倍增长,系统出现了各种各样的异常,那个时候,我7*24小时地没日没夜处理告警,周末和凌晨也经常上线,疲于奔命.后来,当时的老领导对我说:你不能 ...
随机推荐
- jquery绑定回车事件
//回车事件绑定 $(".left-content").keyup(function(event){ var theEvent = event || window.event; v ...
- 19/03/30Python笔记
一.三元运算 a = 1 if (条件) else a = 2 #如果条件成立,a = 1,否则a = 2 二.文件的处理 1.读取 f = open("user.txt",&qu ...
- torchvision里densenet代码分析
#densenet原文地址 https://arxiv.org/abs/1608.06993 #densenet介绍 https://blog.csdn.net/zchang81/article/de ...
- The problems when using a new ubuntu 18.04
how to install dual systems (windows & ubuntu) Donwloading the ubuntu from web. Using refu to cr ...
- Spring Web常见面试问题
一.Web容器初始化过程 先初始化listener,然后是filter,然后是servlet. 二.Spring MVC项目中IOC容器关系 Web容器启动时通知ContextLoaderListen ...
- python 常用的模块
面试的过程中经常被问到使用过那些python模块,然后我大脑就出现了一片空白各种模块一顿说,其实一点顺序也没有然后给面试官造成的印象就是自己是否真实的用到这些模块,所以总结下自己实际工作中常用的模块: ...
- spring @Autowired注入对象,在构造方法中为null问题
出现问题的代码如下: @Service public class BaseHttpServiceImpl implements BaseHttpClient { private final stati ...
- ThinkPHP模板的知识
php框架 一.真实项目开发步骤: 多人同时开发项目,协作开发项目.分工合理.效率有提高(代码风格不一样.分工不好) 测试阶段 上线运行 对项目进行维护.修改.升级(单个人维护项目,十分困难,代码风格 ...
- Ubuntu 14.10 下安装Ambari
安装ambari有两种方式,一是自己下载源码编译,另外一个是使用公共仓库 1 使用Public Respositories Step1: Download the Ambari repository ...
- 解决mysql使用GTID主从复制错误问题
做MySQL主从的话肯定会遇到很多同步上的问题,大多数都是由于机器宕机,重启,或者是主键冲突等引起的从服务器停止工作,这里专门收集类似问题并提供整理解决方案,仅供参考. 1.主从网络中断,或主服务器重 ...