Scrapy爬虫入门
1.安装Scrapy
打开Anaconda Prompt,执行:pip install Scrapy执行安装!
注意:要是安装过程中抛出:
error: Microsoft Visual C++ 14.0 is required. Get it with "Microsoft Visual C++ Build Tools": http://landinghub.visualstudio.com/visual-cpp-build-tools(或者类似信息)的需要提前安装(根据自己的python版本安装,cp36是指匹配python3.6.x版本,amd64是指64位系统):

下载网站:http://www.lfd.uci.edu/~gohlke/pythonlibs/#twisted
完成之后执行安装:
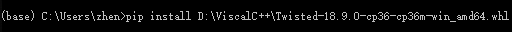
安装成功后再执行:pip install Scrapy执行安装即可!
2.查看scrapy
输入:scrapy,表示安装成功!

3.查看命令
输入:help

4.创建Scrapy项目
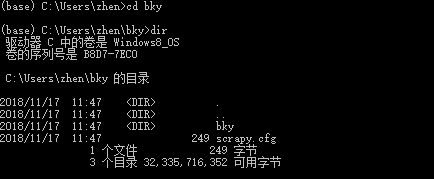
执行命令:scrapy startproject bky

这表示创建成功!
执行cd bky, dir命令查看详情:
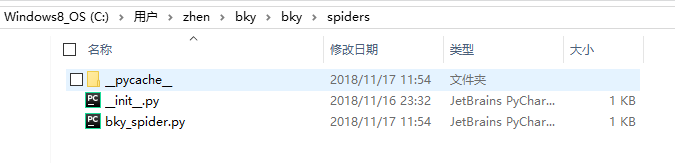
5.创建spider
查看spiders目录

创建一个新的spider,执行命令:scrapy genspider bky_spider "www.cnblogs.cn"


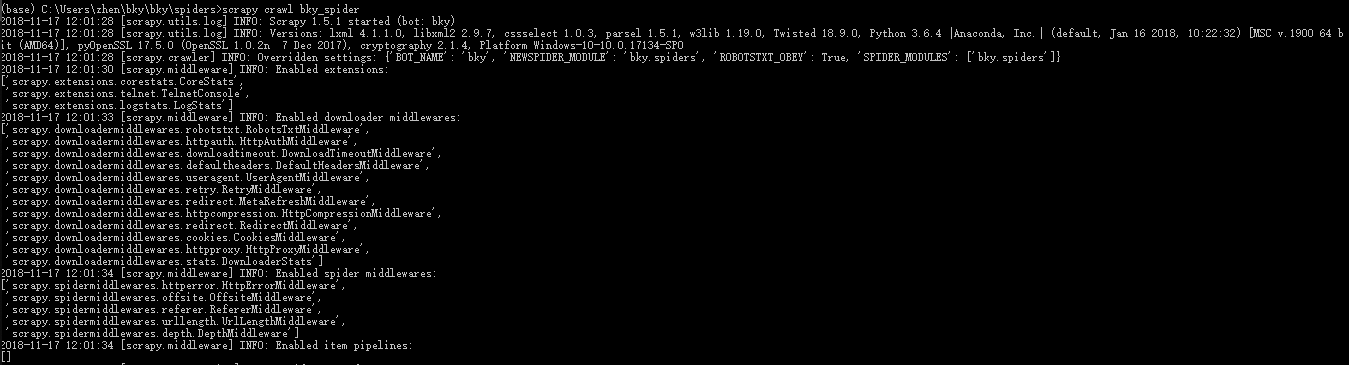
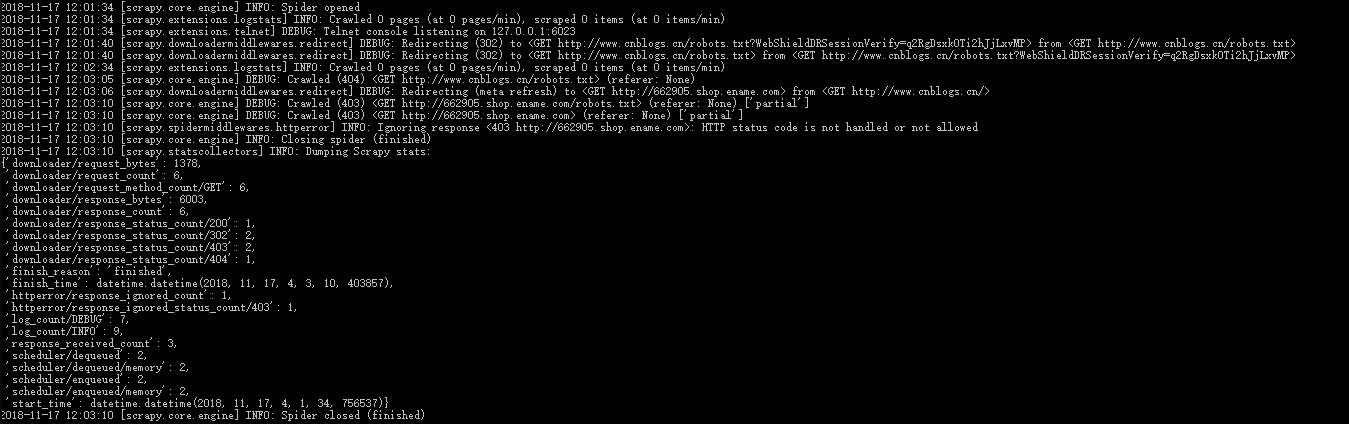
6.执行spider,爬取网页数据
修改bky_spider.py代码:

执行命令:scrapy crawl bky_spider
Scrapy爬虫入门的更多相关文章
- Scrapy爬虫入门系列3 将抓取到的数据存入数据库与验证数据有效性
抓取到的item 会被发送到Item Pipeline进行处理 Item Pipeline常用于 cleansing HTML data validating scraped data (checki ...
- Scrapy 爬虫入门 +实战
爬虫,其实很早就有涉及到这个点,但是一直没有深入,今天来搞爬虫.选择了,scrapy这个框架 http://scrapy-chs.readthedocs.io/zh_CN/0.24/intro/tut ...
- Scrapy爬虫入门实例
网上关于Scracpy的讲述已经非常丰富了,而且还有大神翻译的官方文档,我就不重复造轮子了,自己写了一个小爬虫,遇到不少坑,也学到不少东西,在这里给大家分享一下,自己也做个备忘录. 主要功能就是爬取c ...
- Scrapy爬虫入门Request和Response(请求和响应)
开发环境:Python 3.6.0 版本 (当前最新)Scrapy 1.3.2 版本 (当前最新) 请求和响应 Scrapy的Request和Response对象用于爬网网站. 通常,Request对 ...
- Scrapy爬虫入门系列4抓取豆瓣Top250电影数据
豆瓣有些电影页面需要登录才能查看. 目录 [隐藏] 1 创建工程 2 定义Item 3 编写爬虫(Spider) 4 存储数据 5 配置文件 6 艺搜参考 创建工程 scrapy startproj ...
- Scrapy爬虫入门系列2 示例教程
本来想爬下http://www.alexa.com/topsites/countries/CN 总排名的,但是收费了 只爬了50条数据: response.xpath('//div[@class=&q ...
- Scrapy爬虫入门系列1 安装
安装python2.7 参见CentOS升级python 2.6到2.7 安装pip 参见CentOS安装python setuptools and pip 依赖 https://docs.scra ...
- [Python爬虫] scrapy爬虫系列 <一>.安装及入门介绍
前面介绍了很多Selenium基于自动测试的Python爬虫程序,主要利用它的xpath语句,通过分析网页DOM树结构进行爬取内容,同时可以结合Phantomjs模拟浏览器进行鼠标或键盘操作.但是,更 ...
- 转:Scrapy安装、爬虫入门教程、爬虫实例(豆瓣电影爬虫)
Scrapy在window上的安装教程见下面的链接:Scrapy安装教程 上述安装教程已实践,可行.(本来打算在ubuntu上安装Scrapy的,但是Ubuntu 磁盘空间太少了,还没扩展磁盘空间,所 ...
随机推荐
- vue项目打包上线时的配置操作
vue的图片路径,和背景图片路径打包后错误解决 2017-12-11 16:00 by muamaker, 7037 阅读, 0 评论, 收藏, 编辑 最近在研究vue,老实的按照官网提供的,搭建的了 ...
- Tomcat使用IDEA远程Debug调试
Tomcat运行环境:CentOS6.5.Tomcat7.0.IDEA 远程Tomcat设置 1.在tomcat/bin下的catalina.sh上边添加下边的一段设置 CATALINA_OPTS=& ...
- ZooKeeper和Curator相关经验总结
一.关于ZooKeeper的watch用法,需要注意 详细说明如下: ZooKeeper Watches All of the read operations in ZooKeeper - getDa ...
- Alienware 15 R3 装Ubuntu 和 win10 双系统
一.安装环境 Alienware 15 R3 win10 专业版64位 ubuntu16.04 二.软件下载 1.Ubuntu16.04 下载地址:https://www.ubuntu.com/dow ...
- tf.cast()的用法(转)
一.函数 tf.cast() cast( x, dtype, name=None ) 将x的数据格式转化成dtype.例如,原来x的数据格式是bool, 那么将其转化成float以后,就能够将其转化成 ...
- html css 其他常用 onclick跳转
opacity: 0.5. 0-1 透明度 cursor: pointer;手指 clear:both 清楚浮动 我是医生不是人 文本内容超出框word-wrap:break-word; word-b ...
- Spring Cloud 微服务分布式链路跟踪 Sleuth 与 Zipkin
Zipkin 是一个开放源代码分布式的跟踪系统,由 Twitter 公司开源,它致力于收集服务的定时数据,以解决微服务架构中的延迟问题,包括数据的收集.存储.查找和展现.它的理论模型来自于Google ...
- vue页面参数闪一下的问题
解决方法: 直接在外层元素加上v-cloak <div id='app' v-cloak></div>
- Java并发编程笔记之CyclicBarrier源码分析
JUC 中 回环屏障 CyclicBarrier 的使用与分析,它也可以实现像 CountDownLatch 一样让一组线程全部到达一个状态后再全部同时执行,但是 CyclicBarrier 可以被复 ...
- Eclipse Gradle 构建多模块项目
注意: 1.Eclipse不如IDEA智能,Eclipse建立的Gradle Project项目在目录级别上是同级的; 2.user-web模块如果要引用user-service模块,直接引用是找不到 ...