elasticsearch 基础性操作
1 基础概念
Elasticsearch是一个近实时的系统,从你写入数据到数据可以被检索到,一般会有1秒钟的延时。Elasticsearch是基于Lucene的,Lucene的读写是两个分开的句柄,往写句柄写入的数据刷新之后,读句柄重新打开,这才能读到新写入的数据。
名词解释:
Cluster:集群。
Index:索引,Index相当于关系型数据库的DataBase。
Type:类型,这是索引下的逻辑划分,一般把有共性的文档放到一个类型里面,相当于关系型数据库的table。
Document:文档,Json结构,这点跟MongoDB差不多。
Shard、Replica:分片,副本。
分片有两个好处,一个是可以水平扩展,另一个是可以并发提高性能。在网络环境下,可能会有各种导致分片无法正常工作的问题,所以需要有失败预案。ES支持把分片拷贝出一份或者多份,称为副本分片,简称副本。副本有两个好处,一个是实现高可用(HA,High Availability),另一个是利用副本提高并发检索性能。
分片和副本的数量可以在创建index的时候指定,index创建之后,只能修改副本数量,不能修改分片。
健康状态:
安装了head插件之后,可以在web上看到集群健康状态,集群处于绿色表示当前一切正常,集群处于黄色表示当前有些副本不正常,集群处于红色表示部分数据无法正常提供。绿色和黄色状态下,集群都是能提供完整数据的,红色状态下集群提供的数据是有缺失的。
2 搭建ElasticSearch
首先安装java,设置好JAVA_HOME环境变量(export JAVA_HOME=.../java8),然后安装Elasticsearch。
参考官方文档:https://www.elastic.co/guide/en/elasticsearch/reference/current/_installation.html
设置配置的时候,ES可能因为各种原因不能自动找到集群,所以把地址也设置上,如:
discovery.zen.ping.unicast.hosts: ["host_name...:9301", "host_name_xxx:port_yyy"...]
安装head插件:拉取 https://github.com/mobz/elasticsearch-head 代码,将其放到./plugins/head 目录下。
启动之前设置ES使用的内存:export ES_HEAP_SIZE=10g。
elasticsearcy.yml配置文件中的一些配置点:

#设置集群名字
cluster.name: cswuyg_qa_pair_test
#设置node名字
node.name: xxx-node
#设置节点域名
network.host: 10.111.111.1
#设置内部传输端口和外部HTTP访问端口
transport.tcp.port: 9302
http.port: 8302
#设置集群其它节点地址
discovery.zen.ping.unicast.hosts: ["xxxhost:yyyport"]
#设置中文切词插件
index.analysis.analyzer.ik.type: "ik"
elasticsearch -d 以守护进程方式启动,启动之后,就可以在浏览器里使用head插件看到集群信息,如:
http://host_name_xxx:port_yyy/_plugin/head/
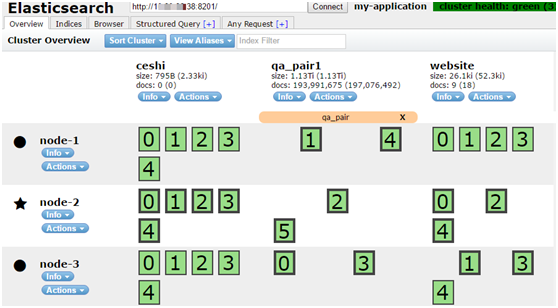
上图:启动了三个Elasticsearch实例,创建了三个Index;ceshi Index有一主shard,两replica shard;qa_pair1 Index只有主shard;website Index有一主shard,一replica shard。
3 测试Elasticsearch使用
Elasticsearch提供RESTful API,我采用Postman(chrome的一个插件)作为辅助客户端向ES发送请求。
可以向任意一个节点发起请求,虽然ES有Master的概念,但任意一个node都可以接受读写请求。
先创建一个index:
POST http://10.11.111.11:8301/test_index
查看创建的index:
GET http://10.11.111.11:8301/_cat/indices?v
写入数据:

查询数据:
(1)使用id直接查:
GET http://xxxhost:8201/qa_xx2/qa_xx3/1235
(2)DSL查询:
往查询url POST数据即可:
URL格式:http://xxxhost:8201/qa_xx2/qa_xx3/_search
a. 查询title中包含有cswuyg字段的文档。Highlight设置高亮命中的词。POST方法的body:
{
"query": {
"match": {
"title": {
"query": "cswuyg "
}
}
},
"highlight": {
"fields": {
"title": {
}
}
}
}
b. bool组合查询,命中的文档的title字段必须能命中“餐厅”、“好吃”、“深圳”,可以是完全命中,也可以是名字其中的个别字。“便宜”则是可选命中。
POST方法的body:
{
"query": {
"bool": {
"must": [{
"match": {
"title": {
"query": "餐厅"
}
}
},
{
"match": {
"title": {
"query": "好吃"
}
}
},
{
"match": {
"title": {
"query": "深圳"
}
}
}],
"should": [{
"match": {
"title": "便宜"
}
}]
}
},
"highlight": {
"fields": {
"title": {
}
}
}
}
如果要求每一个字都命中,可以把match修改为match_phrase。
{
'query': {
'bool': {
'should': [{
'match': {
'title': {
'query': '张三',
'boost': 0.2
}
}
}],
'must': [{
'match_phrase': {
'title': {
'query': '李四',
'boost': 0.69
}
}
},
{
'match_phrase': {
'title': {
'query': '王五',
'boost': 0.11
}
}
}]
}
}
}
例子:要求必须完全命中“酒后”和“标准",“驾驶”可以部分命中
{
"query": {
"bool": {
"must": [{
"match_phrase": {
"question": {
"query": "酒后",
"boost": 0.69
}
}
},
{
"match": {
"question": {
"query": "驾驶",
"boost": 0.11
}
}
},
{
"match_phrase": {
"question": {
"query": "标准",
"boost": 0.2
}
}
}]
}
}
}
c. 给查询词设置权重(boost)。POST方法的body:
{
"query": {
"bool": {
"must": {
"match": {
"title": {
"query": "好吃的餐厅",
"boost": 1
}
}
},
"must": {
"match": {
"title": {
"query": "深圳湾",
"boost": 100
}
}
},
"should": [{
"match": {
"title": "便宜"
}
}]
}
},
"highlight": {
"fields": {
"title": {
}
}
}
}
d. filter查询,也就是kv查询,不涉及检索的相关性打分,title必须是完全命中,如果建库时是有对这个字段切词的,则查询时,需要是切词后的某个词去查询,如“今天天气”,建库切词为“今天”和“天气”,那么filter查询的时候需要使用“今天”或者“天气”才能命中。POST方法的body:
{
"query": {
"bool": {
"filter": [{
"term": {
"title": "好吃的"
}
}]
}
}
}
e. 完全匹配某个短语,这就要求“好厉害”三个字组成的词必须在文档中出现,不能是只出现其中的个别字(match就是这样)。POST方法的body:
{
"query": {
"match_phrase": {
"title": {
"query": "好厉害"
}
}
}
}
(3)运维
a. 去掉副本,调研的时候希望不要副本,这样子写入会快点
PUT http://10.11.111.11:8202/qa_pair2/_settings
{
"number_of_replicas" : 0
}
4 使用ik中文切词插件
Elasticsearch默认的中文切词插件是单字切词,这不能满足我们要求,需要安装中文切词插件。
插件github地址:https://github.com/medcl/elasticsearch-analysis-ik
源码安装:编译时需要联网,可以在windows下编译完之后,把elasticsearch-analysis-ik-1.9.3.zip拷贝到linux机器的./plugin/head目录下解压。
配置:在配置文件./config/elasticsearch.yml末尾添加配置: index.analysis.analyzer.ik.type: "ik"
测试ik切词:http://host_name_xx:port_yyy/qa_pair/_analyze?analyzer=ik&pretty=true&text=我是中国人"
elasticsearch 基础性操作的更多相关文章
- ElasticSearch Index操作源码分析
ElasticSearch Index操作源码分析 本文记录ElasticSearch创建索引执行源码流程.从执行流程角度看一下创建索引会涉及到哪些服务(比如AllocationService.Mas ...
- 使用Spring Data ElasticSearch+Jsoup操作集群数据存储
使用Spring Data ElasticSearch+Jsoup操作集群数据存储 1.使用Jsoup爬取京东商城的商品数据 1)获取商品名称.价格以及商品地址,并封装为一个Product对象,代码截 ...
- elasticsearch使用操作部分
本片文章记录了elasticsearch概念.特点.集群.插件.API使用方法. 1.elasticsearch的概念及特点.概念:elasticsearch是一个基于lucene的搜索服务器.luc ...
- Elasticsearch批处理操作——bulk API
Elasticsearch提供的批量处理功能,是通过使用_bulk API实现的.这个功能之所以重要,在于它提供了非常高效的机制来尽可能快的完成多个操作,与此同时使用尽可能少的网络往返. 1.批量索引 ...
- elasticsearch简单操作
现在,启动一个节点和kibana,接下来的一切操作都在kibana中Dev Tools下的Console里完成 创建一篇文档 将小黑的小姨妈的个人信息录入elasticsearch.我们只要输入 PU ...
- JestClient 使用教程,教你完成大部分ElasticSearch的操作。
本篇文章代码实现不多,主要是教你如何用JestClient去实现ElasticSearch上的操作. 授人以鱼不如授人以渔. 一.说明 1.elasticsearch版本:6.2.4 . jdk版本: ...
- Elasticsearch 安装操作手册
第一部分 ES安装环境的准备和初始化 现在交心的版本Elasticsearch 5.6.3 官方建议安装Oracle的JDK8,安装前先检查机器是否已安装JDK. Step 1 检查环境机器是否已安装 ...
- elasticsearch简单操作(二)
让我们建立一个员工目录,假设我们刚好在Megacorp工作,这时人力资源部门出于某种目的需要让我们创建一个员工目录,这个目录用于促进人文关怀和用于实时协同工作,所以它有以下不同的需求:1.数据能够包含 ...
- elasticsearch聚合操作——本质就是针对搜索后的结果使用桶bucket(允许嵌套)进行group by,统计下分组结果,包括min/max/avg
分析 Elasticsearch有一个功能叫做聚合(aggregations),它允许你在数据上生成复杂的分析统计.它很像SQL中的GROUP BY但是功能更强大. 举个例子,让我们找到所有职员中最大 ...
随机推荐
- 使用rssh创建一个安全的文件服务器
使用rssh创建一个安全的文件服务器 目前有这样一个需求,公司需要一台linux服务器作为文件服务器,但是基于安全性考虑,我不想使用ftp或者samba,但又必须允许用户上传文件.怎么办呢? 因为是l ...
- Disable or enable the IPv6 protocol in Red Hat Enterprise Linux
Resolution Red Hat Enterprise Linux 4, 5 and 6 enable Internet Protocol Version 6 (IPv6) by default. ...
- html中<a href> </a>的用法
一.绝对跳转 <a href="http://www.baidu.com/">百度</a> 二.相对跳转有如下方式,需要了解(以下的例子中,分别以你的 ...
- 转:Android 的进程与线程总结
当一个Android应用程序组件启动时候,如果此时这个程序的其他组件没有正在运行,那么系统会为这个程序 以单一线程的形式启动一个新的Linux 进程. 默认情况下,同一应用程序下的所有组件都运行再相同 ...
- Hibernate中多种方式解除延迟加载
问题引发:因为dao使用load(),默认延迟加载的,当在biz关闭session之后,UI层无法获取对象的非id属性值 解决方案: 1.变成get,即时加载 2.用Hibernate.isIniti ...
- 各版本Sql Server下载地址全
SQL Server 2014简体中文企业版 文件名:cn_sql_server_2014_enterprise_edition 32位下载地址:ed2k://|file|cn_sql_server_ ...
- AUTOIT3设置用户包含目录
- 在windows系统上word转pdf
一.前言:我在做文件转换过程中遇到的一些坑,在这里记录下,因为项目需求,需要使用html转pdf,由于itext转换质量问题(一些Css属性不起作用),导致只能通过word文件作为跳板来转换到pdf文 ...
- 51nod 1873 初中的算术【Java BigDecimal/高精度小数】
1873 初中的算术 基准时间限制:1 秒 空间限制:131072 KB 分值: 10 难度:2级算法题 收藏 关注 Noder现在上初三了,正在开始复习中考.他每天要计算型如 (a× a× a× ...
- 理解css的BFC
BFC是CSS中一个看不见的盒子,(先理解CSS的盒子模型).它的页面渲染方式与普通流的盒子模型不同,它决定了其子元素将如何定位(所用属于BFC的box 都默认左对齐),以及和其他元素的关系和相互作用 ...