ElasticSearch 学习记录之如任何设计可扩容的索引结构
ElasticSearch 系列文章
1 ES 入门之一 安装ElasticSearcha
2 ES 记录之如何创建一个索引映射
3 ElasticSearch 学习记录之Text keyword 两种基本类型区别
4 ES 入门记录之 match和term查询的区别
5 ElasticSearch 学习记录之ES几种常见的聚合操作
6 ElasticSearch 学习记录之父子结构的查询
7 ElasticSearch 学习记录之ES查询添加排序字段和使用missing或existing字段查询
8 ElasticSearch 学习记录之ES高亮搜索
9 ElasticSearch 学习记录之ES短语匹配基本用法
10 ElasticSearch 学习记录之 分布式文档存储往ES中存数据和取数据的原理
11 ElasticSearch 学习记录之集群分片内部原理
12 ElasticSearch 学习记录之ES如何操作Lucene段
13 ElasticSearch 学习记录之如任何设计可扩容的索引结构
14 ElasticSearch之 控制相关度原理讲解
扩容设计
扩容的单元
一个分片即一个 Lucene 索引 ,一个 Elasticsearch 索引即一系列分片的集合
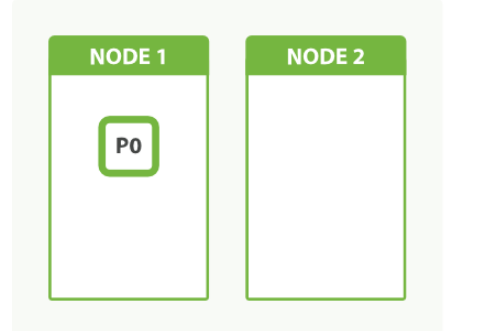
一个分片即为 扩容的单元 。 一个最小的索引拥有一个分片。
一个只有一个分片的索引无扩容因子
-
如何判断一个请求过来,我的信息在哪个分片上面
- shard = hash(routing) % number_of_primary_shards
- routing 大致是指文档的id
分片预分配
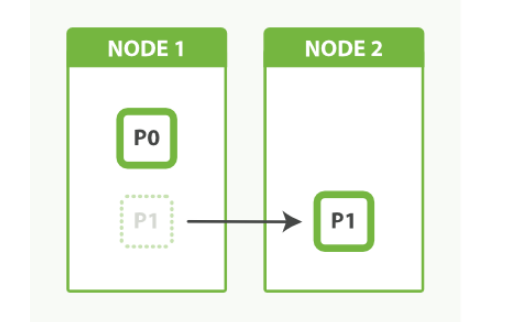
一个分片存在于单个节点, 但一个节点可以持有多个分片
一个拥有两个分片的索引可以利用第二个节点来存储数据
-
Elasticsearch 中新添加的索引默认被指定了五个主分片
为何不使用分片的分裂而是分片复制转移
- 分裂分片是重新索引数据,比复制更重
- 分裂是指数级的
- 分裂需要足够大的空间
海量分片
- 如何控制分片的数量
- 分片的数据模型是什么
- 一个分片的底层是Lucene索引,会消耗文件的句柄 内存 CPU 等
- 每个搜索请求都会命中索引的每个分片,多个分片咋同一个节点上会竞争资源
- 基于相关度的词频信息计算是基于分片的
容量规划
- 如何根据自己的自身情况,来判断分片的多少
- 可以根据下面的步骤,在特定环境中测定分片的多少
- 基于生产的单个节点集群
- 和生产相同的索引,知识他只有一个主分片无副本分片
- 索引实际文档
- 查询或聚合实际文档
- 在真实的环境上运行,直到它挂掉。
- 然后根据上面的信息,来进行分片的数量的计算
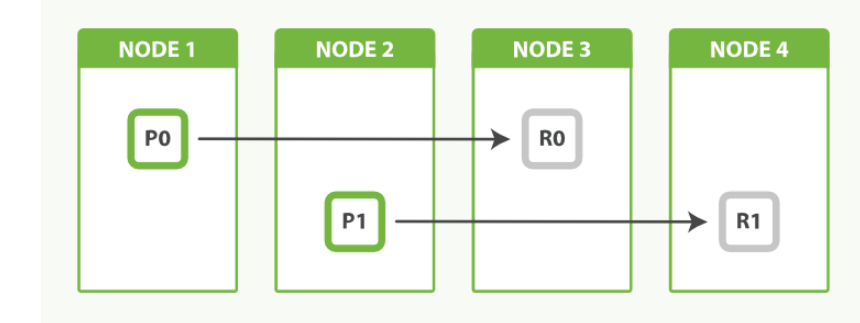
副本分片
副本分片的主要目的就是为了故障转移
如果持有主分片的节点挂掉了,一个副本分片就会晋升为主分片
新文档首先被索引进主分片然后再同步到其它所有的副本分片
副本分片可以服务于读请求
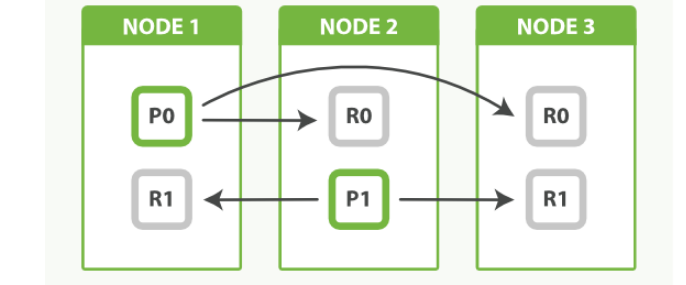
可以通过增加副本的数目来提升查询性能
一个拥有两个主分片一份副本的索引可以在四个节点中横向扩展
过调整副本数来均衡节点负载
- 原则上一个主分片不会它索引的副本分片在一起
多索引
- 如何不停服务来增加容量
- 创建一个新的索引存储数据
- 同时搜索两个索引来获取新数据和旧数据
- 使用索引别名来同时查询两个索引的数据
索引模板‘
使用模板可以创建有用的索引
创建索引模板PUT /_template/my_logs 创建一个名为 my_logs 的模板
{
"template": "logstash-*",
将这个模板应用于所有以 logstash- 为起始的索引
"order": 1, 这个模板将会覆盖默认的 logstash 模板,因为默认模板的 order 更低。
"settings": {
"number_of_shards": 1 限制主分片数量为 1
},
"mappings": {
"default": { 为所有类型禁用 _all 域
"_all": {
"enabled": false
}
}
},
"aliases": {
"last_3_months": {}
添加这个索引至 last_3_months 别名中。
}
}
数据过期
一次删除多个索引
- DELETE /logs_2013* //使用通配符
关闭旧的索引
POST /logs_2014-01-/_flush 刷写(Flush)所有一月的索引来清空事务日志
POST /logs_2014-01-/_close
关闭所有一月的索引.
POST /logs_2014-01-*/_open当你需要再次访问它们时,使用 open API 来重新打开它们。- DELETE /logs_2013* //使用通配符
归档旧索引数据
非常旧的索引 可以通过snapshot-restore API归档至长期存储
基于用户的数据
Elasticsearch 支持多租户所以每个用户可以在相同的集群中拥有自己的索引
一个用户一个索引”对大多数场景都可以满足
共享索引
利用别名实现一个用户一个索引
对子文档进行聚合操作
POST product/_search
{
"size": 0,
"aggs": {
"productSource": {
"terms": {
"field": "productSource"
},
"aggs": {
"prices": {
"children": {
"type": "price"
},
"aggs": {
"minPrice": {
"terms": {
"field": "minPrice"
}
}
}
}
}
}
}
}ElasticSearch 学习记录之如任何设计可扩容的索引结构的更多相关文章
- ElasticSearch 学习记录之ES几种常见的聚合操作
ES几种常见的聚合操作 普通聚合 POST /product/_search { "size": 0, "aggs": { "agg_city&quo ...
- ElasticSearch 学习记录之ES短语匹配基本用法
短语匹配 短语匹配故名思意就是对分词后的短语就是匹配,而不是仅仅对单独的单词进行匹配 下面就是根据下面的脚本例子来看整个短语匹配的有哪些作用和优点 GET /my_index/my_type/_sea ...
- ElasticSearch 学习记录之 分布式文档存储往ES中存数据和取数据的原理
分布式文档存储 ES分布式特性 屏蔽了分布式系统的复杂性 集群内的原理 垂直扩容和水平扩容 真正的扩容能力是来自于水平扩容–为集群添加更多的节点,并且将负载压力和稳定性分散到这些节点中 ES集群特点 ...
- ElasticSearch 学习记录之ES高亮搜索
高亮搜索 ES 通过在查询的时候可以在查询之后的字段数据加上html 标签字段,使文档在在web 界面上显示的时候是由颜色或者字体格式的 GET /product/_search { "si ...
- ElasticSearch 学习记录之ES查询添加排序字段和使用missing或existing字段查询
ES添加排序 在默认的情况下,ES 是根据文档的得分score来进行文档额排序的.但是自己可以根据自己的针对一些字段进行排序.就像下面的查询脚本一样.下面的这个查询是根据productid这个值进行排 ...
- ElasticSearch 学习记录之父子结构的查询
父子结构 父亲type属性查询子type 的类型 父子结构的查询,可以通过父亲类型的字段,查询出子类型的索引信息 POST /product/_search { "query": ...
- ElasticSearch 学习记录之Text keyword 两种基本类型区别
ElasticSearch 系列文章 1 ES 入门之一 安装ElasticSearcha 2 ES 记录之如何创建一个索引映射 3 ElasticSearch 学习记录之Text keyword 两 ...
- Elasticsearch学习记录(分布式的特性)
Elasticsearch学习记录(分布式的特性) 分布式的特性 我们提到Elasticsearch可以扩展到上百(甚至上千)的服务器来处理PB级的数据.然而我们的例子只给出了一些使用Elastics ...
- Elasticsearch学习记录(入门篇)
Elasticsearch学习记录(入门篇) 1. Elasticsearch的请求与结果 请求结构 curl -X<VERB> '<PROTOCOL>://<HOST& ...
随机推荐
- Net Core下多种ORM框架特性及性能对比
在.NET Framework下有许多ORM框架,最著名的无外乎是Entity Framework,它拥有悠久的历史以及便捷的语法,在占有率上一路领先.但随着Dapper的出现,它的地位受到了威胁,本 ...
- 简单背包问题(0032)-swust oj
简单背包问题(0032) Time limit(ms): 1000 Memory limit(kb): 65535 Submission: 5657 Accepted: 1714 Accepted 搜 ...
- 理论篇:关注点分离(Separation of concerns, SoC)
概念 关注点分离(Separation of concerns,SOC)是对只与"特定概念.目标"(关注点)相关联的软件组成部分进行"标识.封装和操纵"的能力, ...
- PHP大文件分割上传(分片上传)
服务端为什么不能直接传大文件?跟php.ini里面的几个配置有关 upload_max_filesize = 2M //PHP最大能接受的文件大小 post_max_size = 8M //PHP能收 ...
- mysql复习秘籍
mysql复习 一:复习前的准备 1:确认你已安装wamp 2:确认你已安装ecshop,并且ecshop的数据库名为shop 二 基础知识: 1.数据库的连接 mysql -u -p -h -u 用 ...
- navigator.userAgent浏览器检测(前端基础系列)
对于前端来说,浏览器检测已经不陌生了,在做一些页面是,需要针对不同的浏览器进行处理不同的逻辑,最简单的就是区分pc和移动端的浏览器,或是android 和ios下的浏览器. 一.浏览器检测的由来? ...
- 数据结构之【栈】+十进制转d进制(堆栈数组模拟)
其实这篇文章开出来主要是水文章%% %% 栈--后进先出的婊 特点:只能在某一端插入和删除的特殊的线性表 操作:进栈--PUSH->向栈顶插入元素 出栈--POP-->将栈顶元素删除 实现 ...
- 初学sheel脚本练习过程
以下是初学sheel脚本练习过程,涉及到内容的输出.基本的计算.条件判断(if.case).循环控制.数组的定义和使用.函数定义和使用 sheel脚本内容: #! /bin/bashecho &quo ...
- JavaScript实现AOP(面向切面编程)
什么是AOP? AOP(面向切面编程)的主要作用是把一些跟核心业务逻辑模块无关的功能抽离出来,这些跟业务逻辑无关的功能通常包括日志统计.安全控制.异常处理等.把这些功能抽离出来之后, 再通过" ...
- EF(EntityFramework)与mysql使用,乱码问题
1.中文乱码问题 利用ef更新数据到mysql数据库中,中文就会变成乱码"???",就算把mysql的数据库的编码设置为"utf8"也会变成乱码,从网上查询了下 ...