谱聚类(Spectral clustering)分析(1)
作者:桂。
时间:2017-04-13 19:14:48
链接:http://www.cnblogs.com/xingshansi/p/6702174.html
声明:本文大部分内容来自:刘建平Pinard博客的内容。

前言
之前对非负矩阵分解(NMF)简单梳理了一下,总觉得NMF与聚类非常相似,像是谱聚类的思想。在此将谱聚类的知识梳理一下,内容无法转载,不然直接转载刘建平Pinard的博文了,常用的谱聚类有RatioCut和Ncut算法,全文主要梳理RatioCut算法:
1)背景知识;
2)理论推导;
3)应用实例
内容为自己的学习记录,其中参考他人的部分,最后一并给出链接。
一、背景知识
关于图的基本概念,以及常用到的拉普拉斯矩阵,之前已经有博文介绍过。直接从图的分割说起:
A-邻接矩阵
邻接矩阵的构造方法,常用的有KNN、全连接等方法,这里仅以全连接中的高斯核为例:
$W_{ij}=S_{ij}=exp(-\frac{||x_i-x_j||_2^2}{2\sigma^2})$
B-无向图切图
对于无向图$G$的切图,我们的目标是将图$G(V,E)$切成相互没有连接的k个子图,每个子图点的集合为:$A_1,A_2,..A_k$它们满足$A_i \cap A_j = \emptyset$,且$A_1 \cup A_2 \cup ... \cup A_k = V$。
对于任意两个子图点的集合$A, B \subset V$,$A \cap B = \emptyset$,我们定义A和B之间的切图权重为:
$W(A, B) = \sum\limits_{i \in A, j \in B}w_{ij}$
那么对于我们k个子图点的集合:$A_1,A_2,..A_k$,我们定义切图cut为:
$cut(A_1,A_2,...A_k) = \frac{1}{2}\sum\limits_{i=1}^{k}W(A_i, \overline{A}_i )$
其中$\overline{A}_i$为${A}_i$的补集。
那么如何切图可以让子图内的点权重和高,子图间的点权重和低呢?一个自然的想法就是最小化$cut(A_1,A_2,...A_k)$,但是可以发现,这种极小化的切图存在问题,如下图:
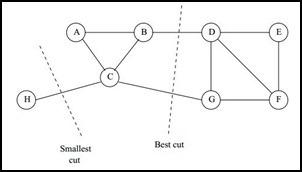
找到类似图中"Best Cut"这样的最优切图呢?一个自然的想法就是,类似为了防止过拟合而添加正则项一样,可以添加新的限定,这就是谱聚类的思想。
二、理论推导(RatioCut)
定义$|A_i|$: = 子集$A_i$中点的个数。现在对每个切图,不光考虑最小化$cut(A_1,A_2,...A_k)$,它还同时考虑最大化每个子图点的个数,即:
$RatioCut(A_1,A_2,...A_k) = \frac{1}{2}\sum\limits_{i=1}^{k}\frac{W(A_i, \overline{A}_i )}{|A_i|}$
那么怎么最小化这个RatioCut函数呢?牛人们发现,RatioCut函数可以通过如下方式表示。
我们引入指示向量$h_j =\{h_1, h_2,..h_k\}\; j =1,2,...k$,对于任意一个向量$h_j$它是一个n维向量(n为样本数),我们定义$h_{ji}$为:
$h_{ji}= \begin{cases} 0& { v_i \notin A_j}\\ \frac{1}{\sqrt{|A_j|}}& { v_i \in A_j} \end{cases}$
借助拉普拉斯矩阵特性,我们对于$h_i^TLh_i$有:
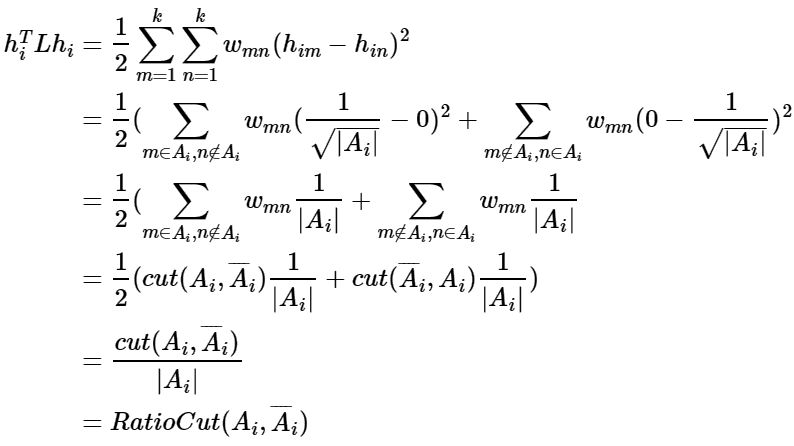
可以看出,对于某一个子图i,它的RatioCut对应于$h_i^TLh_i$,那么我们的k个子图呢?对应的RatioCut函数表达式为:
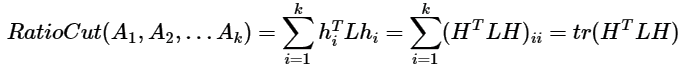
注意到$H^TH=I$,优化函数转化为:
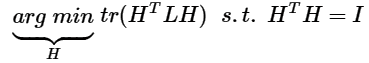
因为每一个h的取值有两种可能,因此该准则函数需要k*2n种H,这是一个NP难问题。
如果对条件适当放松呢?比如这样:
h不再看作只有两种取值的离散变量,而是具有连续取值的变量。
这样一来,上面的优化函数就可以对h利用拉格朗日乘子法进行求解。这种求解方法是瑞利熵求解的一类,关于瑞利熵前文有介绍。因为这里放宽了h的限定,使得h从离散量变为连续量,如何与之前的对应呢?最简单的办法就是看求解的h离h原始的两个取值,哪个更近,对应的就算做哪一类。离哪个更近?没错,这正是Kmeans的思想,故后处理也可以用调Kmeans来完成。Kmeans之前,通常将求解的h每一列分别归一化。
至此完成了RatioCut的步骤。
三、代码实现
首先根据上文的理论分析,给出RatioCut的算法步骤:
步骤一:求解拉普拉斯矩阵L
步骤二:对L进行特征值分解,并取K个最小特征值对应的特征向量(K为类别数目)
步骤三:将求解的K个特征向量(并分别归一化),构成新的矩阵,对该矩阵进行Kmeans处理
Kmeans得到的类别标签,就是原数据的类别标签,至此完成RatioCut聚类。
给出对应代码:
sigma2 = 0.002;
%%Step1: Calculate Laplace matrix
for i = 1:N
for j =1:N
W(i,j) = exp(-sqrt(sum((X(i,:)-X(j,:)).^2))/2/sigma2);
end
end
W = W-diag(diag(W));% adjacency matrix
D = diag(sum(W)); %degree matrix
L = D-W;%laplace matrix
%%Step2:Eigenvalues decomposition
K = 3;
[Qini,V] = eig(L);
%%Step3:New matrix Q
[~,pos] = sort(diag(V),'ascend');
Q = Qini(:,pos(1:K));
Q = Q./repmat(sqrt(diag(Q'*Q)'),N,1);
[idx,ctrs] = kmeans(Q,K);

测试一下,按数据为3类进行谱聚类,可以看出来还是有效的,谱聚类中高斯权重涉及到$\sigma$如何取值,不过这里就不做进一步讨论了。
参考:
谱聚类(Spectral clustering)分析(1)的更多相关文章
- 【聚类算法】谱聚类(Spectral Clustering)
目录: 1.问题描述 2.问题转化 3.划分准则 4.总结 1.问题描述 谱聚类(Spectral Clustering, SC)是一种基于图论的聚类方法——将带权无向图划分为两个或两个以上的最优子图 ...
- 谱聚类(Spectral Clustering)详解
谱聚类(Spectral Clustering)详解 谱聚类(Spectral Clustering, SC)是一种基于图论的聚类方法——将带权无向图划分为两个或两个以上的最优子图,使子图内部尽量相似 ...
- 谱聚类 Spectral Clustering
转自:http://www.cnblogs.com/wentingtu/archive/2011/12/22/2297426.html 如果说 K-means 和 GMM 这些聚类的方法是古代流行的算 ...
- 谱聚类算法(Spectral Clustering)优化与扩展
谱聚类(Spectral Clustering, SC)在前面的博文中已经详述,是一种基于图论的聚类方法,简单形象且理论基础充分,在社交网络中广泛应用.本文将讲述进一步扩展其应用场景:首先是User- ...
- 谱聚类算法(Spectral Clustering)
谱聚类(Spectral Clustering, SC)是一种基于图论的聚类方法--将带权无向图划分为两个或两个以上的最优子图,使子图内部尽量相似,而子图间距离尽量距离较远,以达到常见的聚类的 ...
- Spectral Clustering
谱聚类算法(Spectral Clustering)优化与扩展 谱聚类(Spectral Clustering, SC)在前面的博文中已经详述,是一种基于图论的聚类方法,简单形象且理论基础充分,在 ...
- 谱聚类(spectral clustering)原理总结
谱聚类(spectral clustering)是广泛使用的聚类算法,比起传统的K-Means算法,谱聚类对数据分布的适应性更强,聚类效果也很优秀,同时聚类的计算量也小很多,更加难能可贵的是实现起来也 ...
- 基于谱聚类的三维网格分割算法(Spectral Clustering)
谱聚类(Spectral Clustering)是一种广泛使用的数据聚类算法,[Liu et al. 2004]基于谱聚类算法首次提出了一种三维网格分割方法.该方法首先构建一个相似矩阵用于记录网格上相 ...
- 转:浅谈Spectral Clustering 谱聚类
浅谈Spectral Clustering Spectral Clustering,中文通常称为“谱聚类”.由于使用的矩阵的细微差别,谱聚类实际上可以说是一“类”算法. Spectral Cluste ...
随机推荐
- CSS1,CSS2选择器详解
第一.CSS1选择器: 1.元素选择器(也叫标签选择器,是最基本的选择器) <style> html{background-color: red;} div{background-colo ...
- PHP工厂模式
class yunsuan { public $a; public $b; function suan() { echo "对两个数进行运算"; } } class jia ext ...
- Memcached·Redis缓存的基本操作
Memcached Memcached 是一个高性能的分布式内存对象缓存系统,用于动态Web应用以减轻数据库负载.它通过在内存中缓存数据和对象来减少读取数据库的次数,从而提高动态.数据库驱动网站的速度 ...
- .NET基础笔记(C#)
闲着没事就把以前学习时的笔记拿出来整理了一下,个人感觉有点用,就想拿出来跟园友共享一下.有些基础性的内容比如基本概念.语法什么的就不发了. 内容:1.构造方法(函数) 2.继承 3.访问修饰符 ...
- 不需要密码的windows计划任务设置
使用windows计划任务定时做些事情,确实非常方便,但创建任务时老是需要设置密码,否则在执行任务时会报80070005的系统错误导致任务无法执行. 有时windows没设密码或当账户修改密码就必须修 ...
- [LeetCode] Dp
Best Time to Buy and Sell Stock 题目: Say you have an array for which the ith element is the price of ...
- .NET入行之工作前
时间就像轻风一样,刻意感受的时候几乎把你吹倒,不留意的时候又从你身边轻轻飘走了:长此以后,我怕自己会变得麻木,忘记了原来的样子.所以还是决定给自己留点什么,万一哪天忘记了,还可以再翻起来. 工作两年的 ...
- 某电商网站线上drbd+heartbeat+nfs配置
1.环境 nfs1.test.com 10.1.1.1 nfs2.test.com 10.1.1.2 2.drbd配置 安装drbd yum -y install gcc gcc-c++ make g ...
- Javascript基础知识小测试(一)
这里罗列了<你不知道的js>上卷的一些知识点以及小问题,如果你想巩固一下js那么就和我一起来看看吧. 如果你能不看书就回答上80%的问题说明你js的这一部分学得还不错,再接再厉. 作用域和 ...
- python调用SOA服务
python调用SOA服务,运用suds模块 #! /usr/bin/python # coding:gbk import suds,time,sys reload(sys) sys.setdefau ...