mysql如何执行关联查询与优化
mysql如何执行关联查询与优化
一、前言
在数据库中执行查询(select)在我们工作中是非常常见的,工作中离不开CRUD,在执行查询(select)时,多表关联也非常常见,我们用的也比较多,那么mysql内部是如何执行关联查询的呢?它又做了哪些优化呢?今天我们就来揭开mysql关联查询的神秘面纱。
二、mysql如何执行关联查询
mysql关联执行的策略很简单:mysql对任何关联都执行嵌套循环关联操作。即:mysql先在一个表中循环取出单条数据,然后再嵌套循环到下一个表中寻找匹配的行,依次下去,直到找到所有表中匹配的行为止。然后根据各个表匹配的行,返回查询中需要的各个列。如果mysql在最后一个关联表无法找到更多的行,它将返回上一层关联表,看看能否找到更多的匹配记录,以此类推迭代执行。
按照这种方式,mysql查找第一个表的记录,再嵌套查询下一个关联表,然后回溯到上一个表,这正如其名——“嵌套循环关联”。看一下下面的例子:
SELECT
t1.column1,
t2.column2
FROM
tb1 t1
INNER JOIN tb2 t2 ON t1.column3 = t2.column3
WHERE
t1.column1 IN (4, 6)
假设mysql按照查询中的表顺序进行关联操作,我们可以用伪代码表示其过程:
outer_iter = iterator over t1 WHERE column3 IN (4, 6)
outer_row = outer_iter.next
WHILE outer_row
inner_iter = iterator over t2 WHERE column3 = outer_row.column3
inner_row = inner_iter.next
WHILE inner_row
output [ outer_row.column1,inner_row.column2 ]
inner_row = inner_iter.next
END
outer_row = outer_iter.next
END
上面的执行过程对于单表查询和多表关联查询都适用,如果只是单表查询,那么只需要完成最外层的循环操作即可。如果关联中存在外连接,上面的过程仍然适用,我们只需略作修改。查询sql如下:
SELECT
t1.column1,
t2.column2
FROM
tb1 t1
LEFT OUTER JOIN tb2 t2 ON t1.column3 = t2.column3
WHERE
t1.column1 IN (4, 6)
对应的伪代码修改如下:
outer_iter = iterator over t1 WHERE column3 IN (4, 6)
outer_row = outer_iter.next
WHILE outer_row
inner_iter = iterator over t2 WHERE column3 = outer_row.column3
inner_row = inner_iter.next
IF inner_row
WHILE inner_row
output [ outer_row.column1,inner_row.column2 ]
inner_row = inner_iter.next
END
ELSE
output [ outer_row.column1,NULL ]
END
outer_row = outer_iter.next
END
如果用图表示关联查询的过程,图示如下,请从左至右,从上至下看这幅图:
| t1 | t2 | 结果行 |
| column1=4,column3=1 | column3=1,column2=1 | column1=4,column3=1 |
| column3=1,column2=2 | column1=4,column3=2 | |
| column3=1,column2=3 | column1=4,column3=3 | |
| column1=6,column3=2 | column3=2,column2=1 | column1=6,column3=1 |
| column3=2,column2=2 | column1=6,column3=2 | |
| column3=2,column2=3 | column1=6,column3=3 |
mysql的关联方式也可以由一棵树表示,它是一个左侧深度优先树:
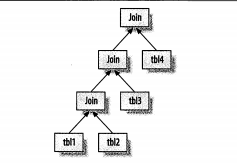
三、关联查询优化器
mysql优化器最重要的一部分就是关联查询优化,它决定了多个表关联时的顺序。通常多表关联的时候,可以有多种不同的关联顺序来获得相同的结果。关联查询优化器则通过评估不同顺序时的成本来选择一个代价最小的关联顺序。
大家看一下下面的查询,它可以通过不同的关联顺序得到相同的结果:
SELECT
u.realname,
u.mobile,
c.`name`
FROM
USER u
INNER JOIN user_company uc ON u.id = uc.user_id
INNER JOIN company c ON uc.company_id = c.id
按照上面的关联执行规则,我们可以给出执行计划,mysql可以从user表开始,通过user_company表的user_id列找到对应的company_id,然后再通过company表的主键找到对应的记录。我们执行了mysql的explain,得出的结果如下:

这和我们给出的执行顺序不一致,这样的效率是否更高呢?我们使用STRAIGHT_JOIN关键字得出的分析结果如下:

我们分析一下mysql为什么会改变关联的顺序,我们可以看到改变顺序后,第一个关联表只需要扫描很少的行数,第二个、第三个关联表的扫描项也是不同的。uc表只有480条记录,而u表有2300条记录。如果先扫描uc表,只返回480条记录,然后进行嵌套循环查询,如果先扫描u表,则返回2300条记录。换句话说,更改顺序后,查询可以进行更少的嵌套循环和回溯操作。
通过这个例子,我们可以看到mysql是如何选择合适的顺序让查询执行的成本更低的。重新定义关联顺序是优化器的一个重要的功能,它尝试在所有关联顺序中选择一个成本最小的来生成执行计划树。
至此,mysql是如何进行关联查询的,以及优化,已经介绍完了,欢迎大家多多交流。
mysql如何执行关联查询与优化的更多相关文章
- MySQL如何执行关联查询
MySQL中‘关联(join)’ 一词包含的意义比一般意义上理解的要更广泛.总的来说,MySQL认为任何一个查询都是一次‘关联’ --并不仅仅是一个查询需要到两个表的匹配才叫关联,索引在MySQL中, ...
- MySQL 如何执行关联查询
本文同时发表在https://github.com/zhangyachen/zhangyachen.github.io/issues/51 当前mysql执行的策略很简单:mysql对任何关联都执行嵌 ...
- MySQL/MariaDB数据库的查询缓存优化
MySQL/MariaDB数据库的查询缓存优化 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.MySQL架构 Connectors(MySQL对外提供的交互接口,API): ...
- Mysql多表表关联查询 inner Join left join right join
Mysql多表表关联查询 inner Join left join right join
- 高性能mysql 第六章查询性能优化 总结(上)查询的执行过程
6 查询性能优化 6.1为什么查询会变慢 这里说明了的查询执行周期,从客户端到服务器端,服务器端解析,优化器生成执行计划,执行(可以细分,大体过程可以通过show profile查看),从服务器端返 ...
- 【MySQL】MySQL的执行计划及索引优化
我们知道一般图书馆都会建书目索引,可以提高数据检索的效率,降低数据库的IO成本.MySQL在300万条记录左右性能开始逐渐下降,虽然官方文档说500~800w记录,所以大数据量建立索引是非常有必要的. ...
- 高性能mysql 第6章 查询性能优化
查询缓存: 在解析一个sql之前,如果查询缓存是打开的,mysql会去检查这个查询(根据sql的hash作为key)是否存在缓存中,如果命中的话,那么这个sql将会在解析,生成执行计划之前返回结果. ...
- JDBC MySQL 多表关联查询查询
public static void main(String[] args) throws Exception{ Class.forName("com.mysql.jdbc.Driver&q ...
- mysql索引原理及查询速度优化
一 介绍 为何要有索引? 一般的应用系统,读写比例在10:1左右,而且插入操作和一般的更新操作很少出现性能问题,在生产环境中,我们遇到最多的,也是最容易出问题的,还是一些复杂的查询操作,因此对查询语句 ...
随机推荐
- WINDOWS java 不能正常卸载 问题, (其他系统问题 也可以试试)
1.JAVA 原安装包无法卸载 不知道 有没有通知 碰到过这种情况的 自己碰到过3次这种情况了, 卸载不掉, 在网上 找了N多中 方法, 注册表什么的都被翻烂了, 单还是没用,其中有一次还把 ...
- Android官方命令深入分析之AVD Manager
作者:宋志辉 AVD Manager提供了一个图形用户接口,通过它你能够创建和管理AVDs. 你能够通过下面方式执行AVD Manager: Eclipse:选择 Window > Androi ...
- 数据结构--二叉查找树的java实现
上代码: package com.itany.erchachazhaoshu; public class BinarySearchTree<T extends Comparable<? s ...
- 【 全干货 】5 分钟带你看懂 Docker !
欢迎大家前往腾讯云社区,获取更多腾讯海量技术实践干货哦~ 作者丨唐文广:腾讯工程师,负责无线研发部地图测试. 导语:Docker,近两年才流行起来的超轻量级虚拟机,它可以让你轻松完成持续集成.自动交付 ...
- 深入理解计算机系统_3e 第八章家庭作业 CS:APP3e chapter 8 homework
8.9 关于并行的定义我之前写过一篇文章,参考: 并发与并行的区别 The differences between Concurrency and Parallel +---------------- ...
- FastDFS并发会有bug,其实我也不太信?- 一次并发问题的排查经历
前一段时间,业务部门同事反馈在一次生产服务器升级之后,POS消费上传小票业务偶现异常,上传小票业务有重试机制,有些重试三次也不会成功,他们排查了一下没有找到原因,希望架构部帮忙解决. 公司使用的是Fa ...
- angular过滤器基本用法
1.过滤器主要用于数据的筛选,可以直接在模板使用 语法: {{expression | filter}} {{expression | filter | filter2}} {{expression ...
- java-生成任意格式的json数据
最近研究java的东西.之前靠着自己的摸索,实现了把java对象转成json格式的数据的功能,返回给前端.当时使用的是 JSONObject.fromObject(object) 方法把java对象换 ...
- 6.python内置函数
1. abs() 获取绝对值 >>> abs(-10) 10 >>> a = -10 >>> a.__abs__() 10 2. all() ...
- MongoDB集群搭建-副本集
MongoDB集群搭建-副本集 概念性的知识,可以参考本人博客地址: 一.Master-Slave方案: 主从: 二.Replica Set方案: 副本集: 步骤:(只要按步骤操作,100%成功) 1 ...