Apache Flume 1.7.0 各个模块简介
Flume简介
Apache Flume是一个分布式、可靠、高可用的日志收集系统,支持各种各样的数据来源,如http,log文件,jms,监听端口数据等等,能将这些数据源的海量日志数据进行高效收集、聚合、移动,最后存储到指定存储系统中,如kafka、分布式文件系统、Solr搜索服务器等;
Apache Flume主要有以下几大模块组成:
- 数据源采集(Source)
- 数据拦截(Interceptor)
- 通道选择器(Channel Selector)
- 数据通道(Channel)
- Sink处理器(Sink Processor)
- Sink(Sink)
- 事件序列化(Serialization)
模块组成图如下所示:
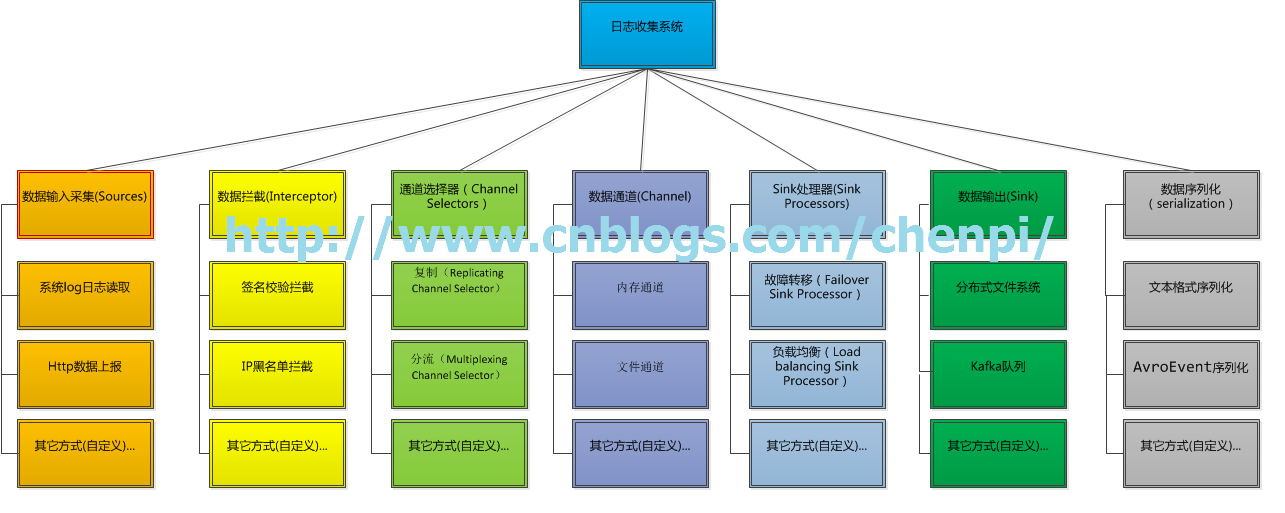
下面将对各个模块做个简单的介绍,在这之前,有必要先了解一下什么是事件?
在Flume中,所谓的事件指的是Flume数据流中的数据单位,包含header和body,用于存储日志数据,其中header是一个map结构,我们可以往header存放一些信息,如时间戳,appid等,以便后续对事件进行处理,body存放的是收集的日志内容字节流,结构如下图所示:

数据源采集(Source)
先看下source模块在流程图中所处的位置,这里以最简单的架构图来作为示例,如下图所示:
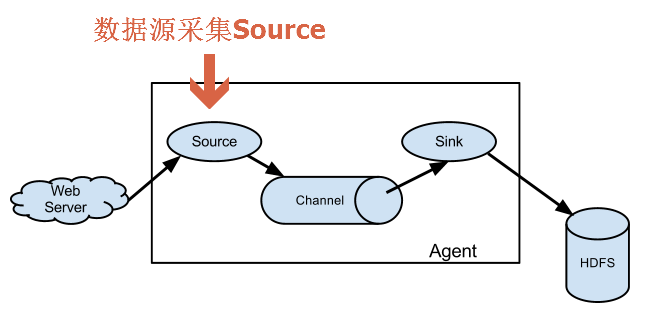
Flume source主要功能是消费传递给它的事件;
Flume内置了各种类型的Source,用于处理各种类型的事件,如下所示,理论上Flume支持所有类型的事件,因为Flume支持自定义Source:
- Avro Source:支持Avro协议(实际上是Avro RPC)
- Thrift Source:支持Thrift协议
- Exec Source:基于Unix的command在标准输出上生产数据
- JMS Source:从JMS系统中读取数据
- Spooling Directory Source:监控指定目录内数据变更
- Twitter 1% firehose Source:通过API持续下载Twitter数据,试验性质
- Netcat Source:监控某个端口,将流经端口的每一个文本行数据作为Event输入
- Sequence Generator Source:序列生成器数据源,生产序列数据
- Syslog Sources:读取syslog数据,产生Event,支持UDP和TCP两种协议
- HTTP Source:基于HTTP POST或GET方式的数据源,支持JSON、BLOB表示形式(实际上支持任何形式,因为handle可以自定义)
- Legacy Sources:兼容老的Flume OG中Source(0.9.x版本)
这里列举几个比较常用的source,
如Exec Source,通过它我们可以监听一个日志文件的变化,如下配置,
a1.sources = r1
a1.channels = c1
a1.sources.r1.type = exec
a1.sources.r1.command = tail -F /var/log/secure
a1.sources.r1.channels = c1
Avro Source,通过它,我们可以将两个Flume Agent关联起来(因为agent的source和sink都支持Avro),正是这个特性,大大提高了flume的灵活性,可用性...
a1.sources = r1
a1.channels = c1
a1.sources.r1.type = avro
a1.sources.r1.channels = c1
a1.sources.r1.bind = 0.0.0.0
a1.sources.r1.port =
HTTP Source,通过它,可以接收http请求上报的数据,如下是配置示例,监听5140端口的http请求,这里的handle是可以自定义的,也就是说我们可以接收任何类型的上报数据,如json格式、xml等等。
a1.sources = r1
a1.channels = c1
a1.sources.r1.type = http
a1.sources.r1.port =
a1.sources.r1.channels = c1
a1.sources.r1.handler = org.example.rest.RestHandler
a1.sources.r1.handler.nickname = random props
数据拦截(Interceptor)
先看下interceptor模块在流程图中所处的位置,如下图所示:
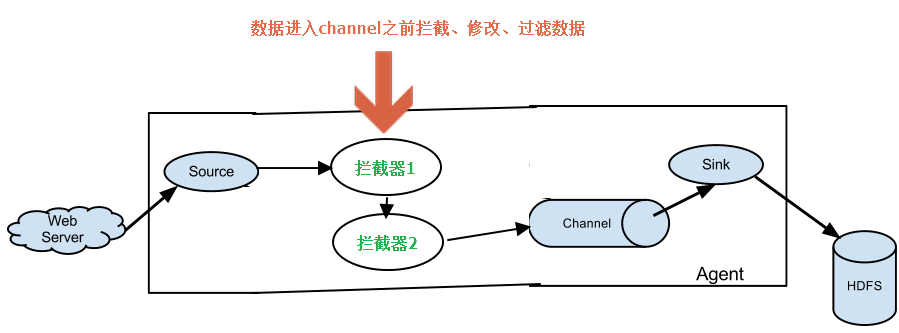
拦截器主要的功能是对事件进行过滤,修改;
Flume内置支持的拦截器如下(主要两类:过滤和修改):
- Timestamp Interceptor:在事件头中插入以毫秒为单位的时间戳,如果在之前已经有这个时间戳,则保留原有的时间戳。
- Host Interceptor:
- Static Interceptor
- UUID Interceptor
- Morphline Interceptor
- Search and Replace Interceptor
- Regex Filtering Interceptor
- Regex Extractor Interceptor
当然,flume是支持自定义拦截器的,如下是一个简单的配置示例:
#拦截器
a1.sources.r1.interceptors = i1
#a1.sources.r1.interceptors.i1.type = org.apache.flume.sw.interceptor.SignCheckInterceptor$Builder
a1.sources.r1.interceptors.i1.type = org.apache.flume.interceptor.RegexFilteringInterceptor$Builder
a1.sources.r1.interceptors.i1.regex = (\\d):(\\d):(\\d)
a1.sources.r1.interceptors.i1.serializers = s1 s2 s3
a1.sources.r1.interceptors.i1.serializers.s1.name = one
a1.sources.r1.interceptors.i1.serializers.s2.name = two
a1.sources.r1.interceptors.i1.serializers.s3.name = three
通道选择器(Channel Selector)
先看下interceptor模块在流程图中所处的位置,如下图所示:
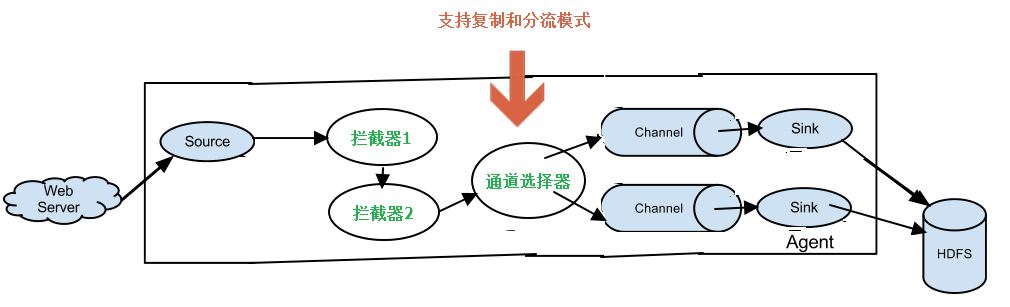
通道选择器的主要功能是对事件流进行复制和分流;
Flume内置了两种类型的通道选择器:
- 复制(Replicating Channel Selector),使用该选择器,我们可以同时让同一事件传递到多个channel中,最后流入多个sink;
- 分流(Multiplexing Channel Selector),使用该选择器,我们可以让特定的事件流入到特定的channel中,如不同项目产生的日志事件,交由不同的sink处理;
如下是一个分流的配置示例:
a1.sources = r1
a1.channels = c1 c2 c3 c4
a1.sources.r1.selector.type = multiplexing
a1.sources.r1.selector.header = state
a1.sources.r1.selector.mapping.CZ = c1
a1.sources.r1.selector.mapping.US = c2 c3
a1.sources.r1.selector.default = c4
当然,通道选择器是支持自定义的,我们可以自己实现通道选择器,并做如下配置:
a1.sources = r1
a1.channels = c1
a1.sources.r1.selector.type = org.example.MyChannelSelector
数据通道(Channel)
先看下channel模块在流程图中所处的位置,如下图所示:
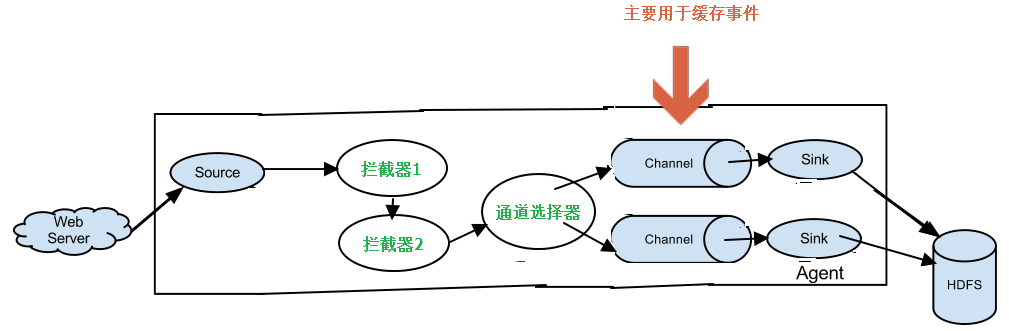
通道Channel的主要功能是缓存日志事件;
Flume内置的Channel如下:
- Memory Channel:内存通道
- JDBC Channel:存储在持久化存储中,当前Flume Channel内置支持Derby
- File Channel:存储在磁盘文件中
- Spillable Memory Channel:存储在内存中和磁盘上,当内存队列满了,会持久化到磁盘文件(当前试验性的,不建议生产环境使用)
- Pseudo Transaction Channel:测试用途
同样,Flume支持自定义通道;
如下是一个内存通道的配置示例:
a1.channels = c1
a1.channels.c1.type = memory
a1.channels.c1.capacity =
a1.channels.c1.transactionCapacity =
a1.channels.c1.byteCapacityBufferPercentage =
a1.channels.c1.byteCapacity =
Sink处理器
先看下Sink处理器在流程图中所处的位置,如下图所示:
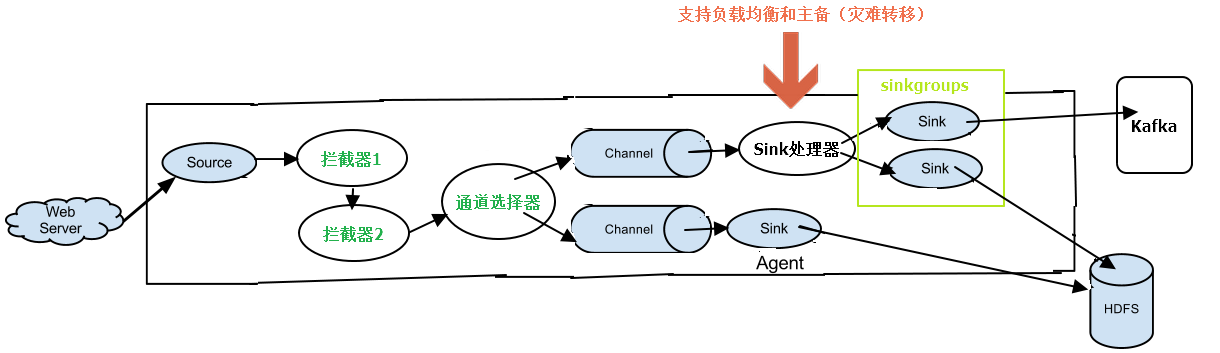
Sink处理器的主要功能是让一组sink groups支持负载均衡和灾难转移功能,我觉得跟通道选择器有点类似通过自定义的方式,我觉得是可以实现通道选择器的功能的;
Flume内置的sink处理器如下:
- load_balance:负载均衡
- failover:主备(灾难转移)
同样的,也支持自定义sink处理器;
如下是一个负载均衡的例子,使用随机选择算法:
a1.sinkgroups = g1
a1.sinkgroups.g1.sinks = k1 k2
a1.sinkgroups.g1.processor.type = load_balance
a1.sinkgroups.g1.processor.backoff = true
a1.sinkgroups.g1.processor.selector = random
Sink(Sink)
先看下Sink模块在流程图中所处的位置,如下图所示:
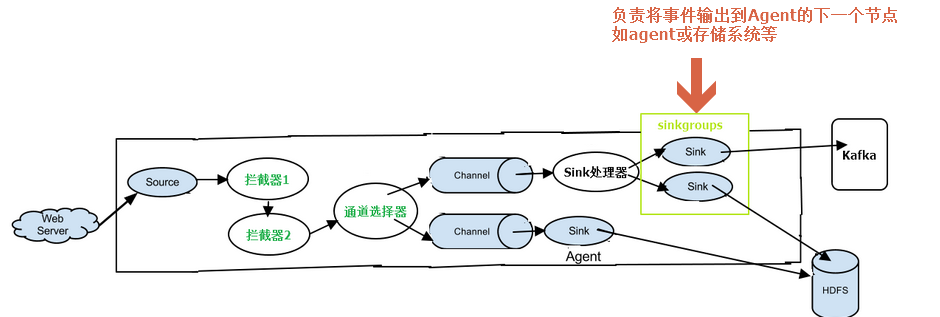
Sink的主要功能是将事件输出到下一个agent的source或其它存储系统如,分布式文件系统、kafka、本地文件系统、日志等;
Flume内置的sink如下:
- HDFS Sink:数据写入HDFS
- Logger Sink:数据写入日志文件
- Avro Sink:数据被转换成Avro Event,然后发送到配置的RPC端口上
- Thrift Sink:数据被转换成Thrift Event,然后发送到配置的RPC端口上
- IRC Sink:数据在IRC上进行回放
- File Roll Sink:存储数据到本地文件系统
- Null Sink:丢弃到所有数据
- HBase Sink:数据写入HBase数据库
- Morphline Solr Sink:数据发送到Solr搜索服务器(集群)
- ElasticSearch Sink:数据发送到Elastic Search搜索服务器(集群)
- Kite Dataset Sink:写数据到Kite Dataset,试验性质的
当然,flume也是支持自定义的;
我们举个本地文件系统的例子,配置如下即可:
a1.channels = c1
a1.sinks = k1
a1.sinks.k1.type = file_roll
a1.sinks.k1.channel = c1
a1.sinks.k1.sink.directory = /var/log/flume
事件序列化(Serialization)
序列化在流程图中所处的位置与Sink一样,这里就不画了,简单地说,Sink负责将事件输出到外部,那么以何种形式输出(直接文本形式还是其它形式),需要包含哪些东西(body还是header还是其它内容...),就是由事件序列化来完成的;
Flume内置的事件序列化如下:
- Body Text Serializer:看名字就知道,直接将事件的body作为文本形式输出,事件header将被忽略
- Avro Event Serializer:Avro序列化,包含事件全部信息
Flume同样支持自定义事件序列化,需要实现EventSerializer接口;
下面举个Body Text Serializer的配置示例:
a1.sinks = k1
a1.sinks.k1.type = file_roll
a1.sinks.k1.channel = c1
a1.sinks.k1.sink.directory = /var/log/flume
a1.sinks.k1.sink.serializer = text
a1.sinks.k1.sink.serializer.appendNewline = false
结语
上面对flume各个模块,或者说组件,做了一个简短的介绍,基本知道了Flume是个怎么回事,接下来将对各个组件做个介绍,并开发各个组件的自定义实现。
参考资料
http://flume.apache.org/FlumeUserGuide.html
http://shiyanjun.cn/archives/915.html
Apache Flume 1.7.0 各个模块简介的更多相关文章
- Apache Flume 1.7.0 发布,日志服务器
Apache Flume 1.7.0 发布了,Flume 是一个分布式.可靠和高可用的服务,用于收集.聚合以及移动大量日志数据,使用一个简单灵活的架构,就流数据模型.这是一个可靠.容错的服务. 本次更 ...
- Apache Flume 1.7.0 源码编译 导入Eclipse
前言 最近看了看Apache Flume,在虚拟机里跑了一下flume + kafka + storm + mysql架构的demo,功能很简单,主要是用flume收集数据源(http上报信息),放入 ...
- Apache Flume 1.6.0 发布,日志服务器
Apache Flume 1.6.0 发布,此版本现已提供下载: http://flume.apache.org/download.html 更新日志和文档: http://flume.apache. ...
- Apache Flume 1.7.0 自定义输入输出
自定义http source config a1.sources.r1.type=http a1.sources.r1.bind=localhost a1.sources.r1.port= a1.so ...
- Flume 1.5.0简单部署试用
================================================================================ 一.Flume简介 ========= ...
- Apache Flume日志收集系统简介
Apache Flume是一个分布式.可靠.可用的系统,用于从大量不同的源有效地收集.聚合.移动大量日志数据进行集中式数据存储. Flume简介 Flume的核心是Agent,Agent中包含Sour ...
- 各开源协议BSD,GPL,LGPL,Apache 2.0,mit等简介*
快速阅读 分类 子分类 开源约定 BSD original BSD license.FreeBSD license.Original BSD license 为所欲为 Apache Licence 2 ...
- Flume官方文档翻译——Flume 1.7.0 User Guide (unreleased version)(一)
Flume 1.7.0 User Guide Introduction(简介) Overview(综述) System Requirements(系统需求) Architecture(架构) Data ...
- Apache Flume 安装文档、日志收集
简介: 官网 http://flume.apache.org 文档 https://flume.apache.org/FlumeUserGuide.html hadoop 生态系统中,flume 的职 ...
随机推荐
- RedHat6.2 x86手动配置LNMP环境
因为公司要求用RedHat配,顺便让我练习一下Linux里面的操作什么的. 折腾来折腾去终于搞好了,其实也没那么难嘛.但是也要记录一下. 首先,是在服务器里面用VMware搭建的RedHat6.2 x ...
- iOS bug调试技巧学习----breakpoint&condition
给断点添加条件 - (void)testCondition2 { NSArray *array = @[@"我们", @"一起", @"来" ...
- JSON 转换异常 multipartRequestHandler servletWrapper
下面出现红色的字还有警告,解决方法:本人项目是struts1 from类继承了“extends ActionForm” .把它去掉就行了.如果你是其它的框架一定是继承引起的作个参考吧. ....... ...
- ASP.NET MVC5+EF6+EasyUI 后台管理系统(84)-Quartz 作业调度用法详解一
前言 我从Quartz2.0开始使用,并对其进行了封装了界面,可以参考 http://www.cnblogs.com/ymnets/p/5065154.html 最近拿出来进行了优化,并升级到最新版, ...
- 编写高质量代码:改善Java程序的151个建议(第二章:基本类型)
编写高质量代码:改善Java程序的151个建议(第二章:基本类型) 目录 建议21:用偶判断,不用奇判断 建议22:用整数类型处理货币 建议23:不要让类型默默转换 建议24:边界还是边界 建议25: ...
- JAVA上传与下载
java下载指定地址的文件 package com.test; import java.io.FileNotFoundException; import java.io.FileOutputStrea ...
- JAVA程序员成长历程(一)
程序员的20个常见瓶颈 在扩展性的艺术一书中,Russell给出了20个有意思的估计:大约有20个经典瓶颈. Russell说,如果在他年轻时他就知道这些瓶颈该有多好!这些论断包括: * Databa ...
- [leetcode-521-Longest Uncommon Subsequence I]
Given a group of two strings, you need to find the longest uncommon subsequence of this group of two ...
- Linux系统目录结构介绍
参考博客: http://www.cnblogs.com/chensiqiqi/p/6243549.html 感谢原博主为我学习Linux指明方向!! linux目录:一切从“根”开始,“/”是所有目 ...
- java-bootstrap
先来看一段每一个项目都要写的BASH脚本. #!/usr/bin/env bash in start ) ;; stop ) ;; restart ) shift "$0" sto ...