SQLServer中间接实现函数索引或者Hash索引
本文出处:http://www.cnblogs.com/wy123/p/6617700.html
SQLServer中没有函数索引,在某些场景下查询的时候要根据字段的某一部分做查询或者经过某种计算之后做查询,
如果使用函数或者其他方式作用在字段上之后,就会限制到索引的使用,不过我们可以间接地实现类似于函数索引的功能。
另外一个就是如果查询字段较大或者字段较多的时候,所建立的索引就显得有点笨重,效率也不高,
就需要考虑使用一个较小的"替代性"字段做等价替换,类似于Hash索引,
本文粗浅地介绍两种上述两种问题的解决方式,仅供参考。
1,在计算列上建索引,实现“函数索引”的功能
SQLServer在建表的时候允许使用计算列,可以借助这个计算列来实现函数索引的功能,这里举例说明一下
Create Table TestFunctionIndex
(
id int identity(1,1),
val varchar(50),
subval as LOWER(SUBSTRING(val,10,4)) persisted --增加一个持久化计算列
)
GO --在持久化计算列上建立索引
create index idx_subvar on TestFunctionIndex(subval)
GO --插入10W行测试数据
insert into TestFunctionIndex(val) values (NEWID())
go 100000
在有索引的字段上使用函数之后,是无法使用索引的

如果直接在计算列上查询,就可以正常地使用到索引了
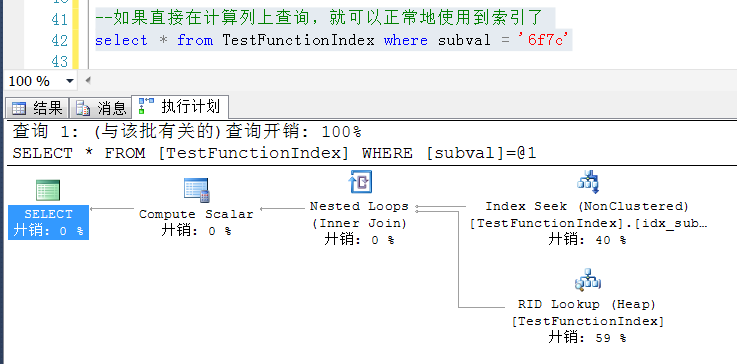
以上通过在计算列上建立一个索引,可以根据计算列上的索引做查找,避免了直接在字段上使用函数或者其他操作,造成即便字段上有索引也用不到的情况
补充:
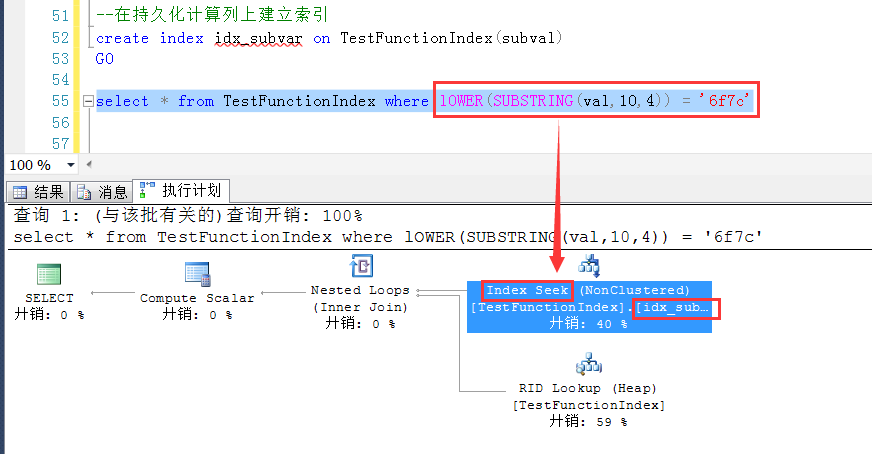
测试中神奇地发现,如果计算列字段上建立了索引,在原始字段上使用函数与计算列的函数一样的时候,可以神奇地使用到计算列上的索引
可见SQLServer在我们没有注意的地方也是下了不少功夫的啊
2,生成较长字段或者多个字段的Hash值替代原始字段做查询或者连接来提升查询效率
开发中遇到另外一种常见的情况是经常使用到的查询条件字段较长,或者是表连接的时候连接条件字段较多,
即便是字段或者查询条件上有索引,但是因为字段较长或者条件较多,此时有可能会影响到查询的效率
这种情况就适当考虑将原始的较长的字段生成一个较小的字段(但是要确保唯一性),或者是讲多个字段生成一个较短的数据类型做替代,以提高查询的效率
举个例子,假如有这么一张表,Name字段是我模拟出来的,Name是一个比较长的字段,又要用来做检索
意思就是查询字段较长,索引代价太大,此时就需要考虑用一种较小的等价字段来替代
下面通过某种方式计算较长字段的Hash值,来做等价替换
模拟生成一下测试数据
Create table testHashColumn
(
id int identity(1,1),
QueryName nvarchar(100),
HashName AS CAST( HASHBYTES('MD2',QueryName) AS UNIQUEIDENTIFIER) persisted
)
GO create index idx_HashName ON testHashColumn(HashName)
GO --这里模拟生成一个较长的名字字段
DECLARE @i int = 0
while @i<10000
begin
INSERT INTO testHashColumn (QueryName) VALUES (CONCAT('北京新视点科技文化传媒有限公司',@i))
set @i = @i+1
end
我们知道,Name这个名字是nvarchar(100)的,这个字段做索引不是不可以,
如果情况复杂,实际中有可能比这个字段更大,做索引显得太宽了,造成索引空间过大,在效率上有一定程度的影响。
这里就可以考虑在Name这个字段上生成一个“替代”字段(上述HashName AS CAST( HASHBYTES('MD2',QueryName) AS UNIQUEIDENTIFIER) persisted这个计算列),
这个字段首选是要跟实际值一一对应的,另外就是要求“替代”的字段类型要求相对较小,
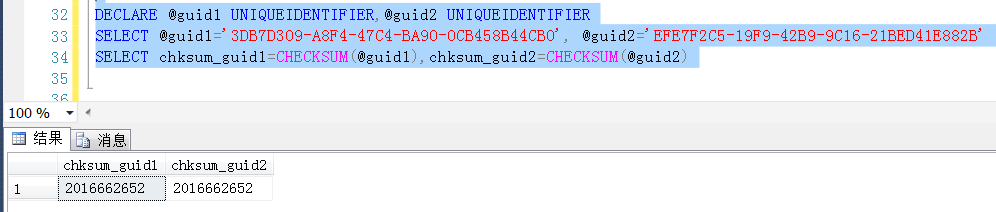
当然方法也有多种,比如生成利用checksum函数生成一个校验值,
但是据实际观察checksum生成的校验值是有可能重复的,也就是说两个不同的字符串,生成同一个校验值
比如这样,很容易验证出来这个问题,可以认为是对于不同的字符串,计算之后得到同一个校验和
因此在生成“替代”字段的时候,需要考虑计算值的唯一性
这里使用的是HASHBYTES加密函数,对字符串加密,然后对加密之后的数据生成一个UNIQUEIDENTIFIER,重复的概率就小的多的多了
演示这里通过CAST( HASHBYTES('MD2','北京新视点科技文化传媒有限公司999') AS UNIQUEIDENTIFIER)的方式,就可以给这个较长的字段生成一个UNIQUEIDENTIFIER类型的字段,
当然也不一定只有这一种方法,甚至可以做的跟复杂,只要能保证一个唯一的长字段生成的较短的字段也是唯一的就可以达到目的了
参考如下查询,就可以使用HashName计算出来的值与计算列做比较,在一定程度上可以减少检索字段索引的大小,又能达到目的的效果
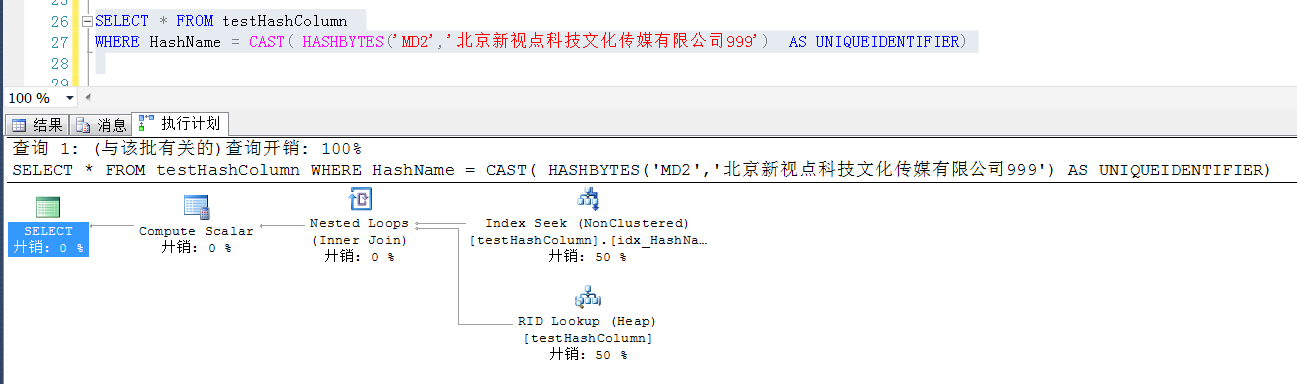
如截图,就可以使用HashName字段上的索引了,同时也避免了在原始的QueryName这个较长的字段上建索引,节约了空间并提高了查询效率
3, 逻辑主键为多个字段的时候,在多了字段上生成一个“替代”性的唯一字段
某些情况下业务需求或者设计也好(比如没有达到第三范式,BC范式,第四范式,甚至是第五范式),在表连接的时候往往会有多个字段
比如这种样子:
SELECT *
FROM TableNameA a
INNER JOIN TableNameB b
ON a.key=b.key
AND a.Type = b.Type
AND a.Status = b.Staus
AND a.CreationTime = b.CreationTime
AND a.***=b.***
where ***
在表关联的时候,连接条件很多,
如果是这样子,最好的情况就是建立一个较宽的复合索引,
但是这样的话,索引的宽度和体积就变得很大,使用的时候效率也有一定的影响
这种情况就可以考虑在TableNameA 和 TableNameB 上,
利用多个连接的字段(Key+Type +Status +CreationTime+***)做了类似于示例2中的一个计算列,在计算列上建立一个索引
然后再表连接的时候就可以用如下的方式替代
SELECT *
FROM TableNameA a
INNER JOIN TableNameB b
ON a.HashValue=b.HashValue
WHERE ***
总是,这是一种以空间换时间的思路(冗余存储一个类似于标识符的字段,提高查询效率),
在生成“替代”字段的思想有两点,第一要足够的小,第二要原始值生成替代字段的唯一性
总结:SQLServer 中没有函数索引和Hash索引,而某些业务需求或者说是为了性能考虑,又需要类似的功能,
通过类似于空间换时间的方法来实现,可以变通地来实现类似于函数索引或者Hash索引的功能,已达到其他数据库中函数索引和Hash索引的效果(虽然原理可能不一样)。
需要注意的就是在生成计算列或者说Hash值替代的时候要注意计算方式,确保生成之后的Key值的唯一性
当然实现方式就可以根据需要自行选择了,条条大路通罗马。
SQLServer中间接实现函数索引或者Hash索引的更多相关文章
- (转)笔记320 SQLSERVER中的加密函数 2013-7-11
1 --SQLSERVER中的加密函数 2013-7-11 2 ENCRYPTBYASYMKEY() --非对称密钥 3 ENCRYPTBYCERT() --证书加密 4 ENCRYPTBYKEY() ...
- SQLSERVER中的 CEILING函数和 FLOOR函数
SQLSERVER中的 CEILING函数和 FLOOR函数 --SQLSERVER中的 CEILING函数和 FLOOR函数 --ceiling函数返回大于或等于所给数字表达式的最小整数. --fl ...
- 【转载】Sqlserver中使用Round函数对计算结果四舍五入
在实际应用的计算中,很多时候我们需要对最后计算结果四舍五入,其实在Sqlserver中也有对应的四舍五入函数,就是Round函数,Round函数的格式为Round(column_name,decima ...
- mysql索引(btree索引和hash索引的区别)
所有MySQL列类型可以被索引.根据存储引擎定义每个表的最大索引数和最大索引长度.所有存储引擎支持每个表至少16个索引,总索引长度至少为256字节.大多数存储引擎有更高的限制. 索引的存储类型目前只有 ...
- B-Tree索引和Hash索引的区别
Hash 索引结构的特殊性,其检索效率非常高,索引的检索可以一次定位,不像B-Tree 索引需要从根节点到枝节点,最后才能访问到页节点这样多次的IO访问,所以 Hash 索引的查询效率要远高于 B-T ...
- mysql优化3:BTree索引和Hash索引
一.BTree索引 注:名叫btree索引,大的方面看,都用的平衡树,但具体的实现上,各引擎稍有不同,比如,严格地说,NDB引擎使用的是T-tree,Myisam和innodb中默认用B-tree索引 ...
- MySQL的btree索引和hash索引的区别
Hash 索引结构的特殊性,其检索效率非常高,索引的检索可以一次定位,不像B-Tree 索引需要从根节点到枝节点,最后才能访问到页节点这样多次的IO访问,所以 Hash 索引的查询效率要远高于 B-T ...
- MySQL索引类型 btree索引和hash索引的区别
来源一 Hash 索引结构的特殊性,其检索效率非常高,索引的检索可以一次定位,不像B-Tree 索引需要从根节点到枝节点,最后才能访问到页节点这样多次的IO访问,所以 Hash 索引的查询效率要远高于 ...
- 14的路 MySQL的btree索引和hash索引的区别
http://www.cnblogs.com/vicenteforever/articles/1789613.html ash 索引结构的特殊性,其检索效率非常高,索引的检索可以一次定位,不像B-Tr ...
随机推荐
- Docker实战--部署简单nodejs应用
如何在Docker的container里运行Node.js程序 主体思路:一个简单的Node.js web app,来构建一个镜像,然后基于这个镜像,运行一个容器,从而实现快速部署. 操作环境: 虚拟 ...
- python实现多变量线性回归(Linear Regression with Multiple Variables)
本文介绍如何使用python实现多变量线性回归,文章参考NG的视频和黄海广博士的笔记 现在对房价模型增加更多的特征,例如房间数楼层等,构成一个含有多个变量的模型,模型中的特征为( x1,x2,..., ...
- 深度神经网络(DNN)反向传播算法(BP)
在深度神经网络(DNN)模型与前向传播算法中,我们对DNN的模型和前向传播算法做了总结,这里我们更进一步,对DNN的反向传播算法(Back Propagation,BP)做一个总结. 1. DNN反向 ...
- Javascript面对对象. 第四篇
原型模式创建对象也有自己的缺点,它省略看构造函数传参初始化这一过程,带来的缺点就是初始化的值都是一致的. 而原型最大的缺点就是它优点,那就是共享. 原型中所有属性是被很多实例共享的,共享对于函数非常合 ...
- 配置opencv环境
包含目录:解决代码报错问题 F:\ndk\opencv-windows\opencv\build\include;F:\ndk\opencv-windows\opencv\sources\includ ...
- Angela Merkel poised for record poll win and historic third term
Her success remains a mystery for many, but victory could see the German chancellor beat Thatcher's ...
- .net是最牛逼的开发平台没有之一
.net是最牛逼的开发平台没有之一 .net是最牛逼的开发平台没有之一 .net是最牛逼的开发平台没有之一 .net是最牛逼的开发平台没有之一 .net是最牛逼的开发平台没有之一 .net是最牛逼的开 ...
- [翻译]现代java开发指南 第一部分
现代java开发指南 第一部分 第一部分:Java已不是你父亲那一代的样子 第一部分,第二部分 =================== 与历史上任何其他的语言相比,这里要排除c语言和cobol语言,现 ...
- JS高级程序设计学习笔记——继承
我们知道,在OO语言中,继承可分为接口继承和实现继承.而ECMAScript的函数没有签名,不能实现“接口继承”,只能通过原型链实现“实现继承”. 在学习了各种继承模式之后,简单总结一下各种继承模式的 ...
- HTTP各状态消息说明
200:请求已成功,请求所希望的响应头或数据体将随此响应返回. 302:请求的资源临时从不同的 URI 响应请求.由于这样的重定向是临时的,客户端应当继续向原有地址发送以后的请求.只有在 Cache- ...