Api 和 Spi
目录
背景返回目录
Java 中区分 Api 和 Spi,通俗的讲:Api 和 Spi 都是相对的概念,他们的差别只在语义上,Api 直接被应用开发人员使用,Spi 被框架扩张人员使用,详细内容可以看:http://www.cnblogs.com/happyframework/p/3325560.html。
Java类库中的实例返回目录
代码

1 Class.forName("com.mysql.jdbc.Driver");
2 Connection conn = DriverManager.getConnection(
3 "jdbc:mysql://localhost:3306/test", "root", "123456");
4 Statement stmt = conn.createStatement();
5
6 ResultSet rs = stmt.executeQuery("select * from Users");
说明
java.sql.Driver 是 Spi,com.mysql.jdbc.Driver 是 Spi 实现,其它的都是 Api。
如何实现这种结构?返回目录
代码
1 public class Program {
2
3 public static void main(String[] args) throws InstantiationException,
4 IllegalAccessException, ClassNotFoundException {
5 Class.forName("SpiA");
6
7 Api api = new Api("a");
8 api.Send("段光伟");
9 }
10 }
1 import java.util.*;
2
3 public class Api {
4 private static HashMap<String, Class<? extends Spi>> spis = new HashMap<String, Class<? extends Spi>>();
5 private String protocol;
6
7 public Api(String protocol) {
8 this.protocol = protocol;
9 }
10
11 public void Send(String msg) throws InstantiationException,
12 IllegalAccessException {
13 Spi spi = spis.get(protocol).newInstance();
14
15 spi.send("消息发送开始");
16 spi.send(msg);
17 spi.send("消息发送结束");
18 }
19
20 public static void Register(String protocol, Class<? extends Spi> cls) {
21 spis.put(protocol, cls);
22 }
23 }
1 public interface Spi {
2 void send(String msg);
3 }
1 public class SpiA implements Spi {
2 static {
3 Api.Register("a", SpiA.class);
4 }
5
6 @Override
7 public void send(String msg) {
8 System.out.println("SpiA:" + msg);
9 }
10
11 }
说明
Spi 实现的加载可以使用很多种方式,文中是最基本的方式。
备注返回目录
还记得大学期间学习 Java,当时看到 Spi 的开发方式就感觉一个词:不明觉厉。
时间流逝,经验增加,财富增加,幸福也会增加。
你真的懂printf么?
自从你进入程序员的世界,就开始照着书本编写着各种helloworld,大笔一挥:
printf("Hello World!\n");
于是控制台神奇地出现了一行字符串,计算机一句温馨的问候将多少年轻的骚年们引入了这个比58同城还神奇的世界......
今天的旅行从这里开始:
#include <stdio.h>
int main()
{
float a = 0.5;
printf("float a is %f\n",a);
return 0;
}
第一步:进入调试,我们首先进入了printf.c中的代码:
于是,我们知道了printf中关键的问题就是传入多个参数,以及如何将信息解析并输出。而参数的传递主要就是由几个宏完成的:va_list、va_start、va_end,这三个宏的定义在stdarg.h中又被替换了,而真正的定义则是在vadefs.h中:

我的机器是x86架构,32位win7系统,所以走的是上面这个宏定义块。打开了这个文件,你就知道了printf是多么的体系架构相关,所以导致printf的移植工作相当困难,至少我见过的每一本讲到printf和stdarg.h的书都会来上类似下面的一句:
This is a complex process. -_-b
va_list其实就是char *,唬人用的;va_start(ap, fmt)定位第一个参数的地址,va_end(ap)将ap指针指向空,防止野指针问题。接下来我们可以看到printf函数的实质就是try块中的三个函数,接着我们跟进去看看到底怎么回事。
第二步:接着程序指针又跳到了_stfbuf.c文件里,去执行_stbuf(stdout)函数了。
这个函数主要就是初始化缓冲区,为后面转化和打印做准备,缓冲区大小是4096个字节,若成功执行返回值为1。
第三步:接下来到文件output.c中的_output_l函数中:
这个函数算是核心吧,首先会设置一大堆的标志值,比如浮点精度,前后缀添0的位数什么的,具体每个是干什么的我也说不全。还是来看下面这个过程吧,1068行的while循环就开始解析字符串了,此时format的值就是“float a is %f\n”,一个字符一个字符地取放入ch中,然后下面去检查类型,比如此时ch的值就是f,是一个普通的字符,所以状态state的值就设置为ST_NORMAL,去执行下面的switch语句。

switch语句里,有很多状态分支,普通字符ST_NORMAL、百分号ST_PERCENT(这个对于printf来说就是比较特殊的)、ST_FLAG(符号)等等。对于普通字符,直接就写到缓冲区里去了,每写一个字符,format指针就向后移一位。当解析到%号时,就执行ST_PERCENT的分支。
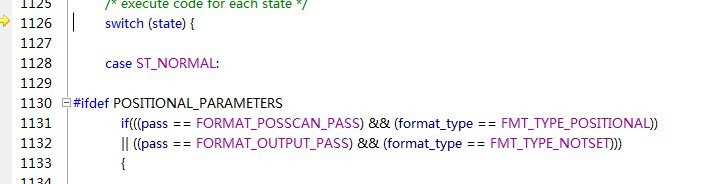
之后读取后一个字符,发现是f则再找到ST_TYPE的分支,执行数据的提取工作。argptr就是指向浮点数a地址的指针。按double类型提取数据并保存到tmp里。


第四步:当数据提取出来后,执行转换函数:
当数据保存到tmp中,就可以执行下列这个函数去将数字转换为字符串并存放到buf里了printf的关键就是如何解析(或者说提取)参数,最终将参数全部转换为字符串放到一个buffer里输出到屏幕上。浮点数转换后存放在char * 型的text.sz里,有兴趣可以深入这个convert函数里看看怎么转换的~(对于浮点好像有个名叫DTOA函数,记不太清了)

在这些工作完成后output_l函数就返回了,返回的是打印的字符数:20。(你可以数一下下面控制台的输出字符数,最后包括了换行符)
第五步:将字符串写到标准输出流:
返回到printf.c中,执行_ftbuf函数,其中再进入flush函数,在执行到下面指针指向的位置时,控制台才真正将所要打印的字符串打印出来,我们的任务这时才算完成了。


好了,再来说说我为什么要写这篇关于printf的文章,是因为在最近的项目里,碰到了跨平台printf的实现问题,浮点数打印不出来,查了很多资料都没有什么相关的,网上众说纷纭。于是我就到stackoverflow上发了个问,但是却是一件很不愉快的事情。看看截图吧,首先是我提的原问题:

接下来就好玩了~:
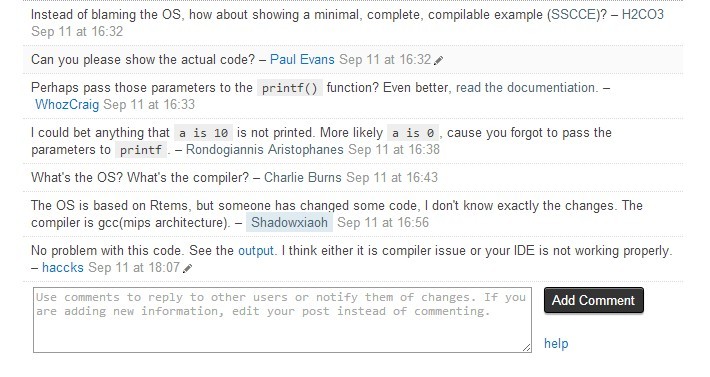
原帖地址:http://stackoverflow.com/questions/18746570/printf-cannot-print-float-double-correctly-on-the-screen
我确实一开始忘记打参数a,b,c了,但是这不影响问题本身,很明显最初回答的人根本没有经过思考,说我连printf的参数怎么写都不知道就来问,更有甚者把发问规则给我贴了出来,叫我不要发垃圾问题,还说我乱归结原因,我只能无奈呵呵了~。那么我想问的是:首先别人提的问题有你想象的那么二么?其次,如果别人真的二,按没写参数的代码区编译执行会出现所描述的现象么?在没有认真看别人问题和现象描述的情况下,秀下限的来了~ 而在我将问题修改过后(仅仅是加上了printf中的a、b、c而已),并且一一回复了留言后(我无一例外的以sorry开头),前面赶着来秀下限的几却个没有一个能回答上来,甚至连自己的看法都提不出(我能说什么呢?呵呵!)。
那么他们为什么回答不出来呢?因为只有真正做过嵌入式交叉开发的人才会知道这个问题的可能原因,在移植的工作中经常会碰到printf的相关问题,不光是浮点数打印不出来。好吧,看看真正懂的人是怎么说的吧,有两个回答都是可能的原因(本来还有人提的一个答案,被我屏蔽掉了,是来秀下限的~),群众的眼睛是雪亮的,从我在项目中调试的结果看,应该是下面第一个原因,任务栈的字节对齐问题,导致浮点传参错误;第二个回答也是一种可能,但我们在编译时确实没有加下面的宏。果断vote之~:

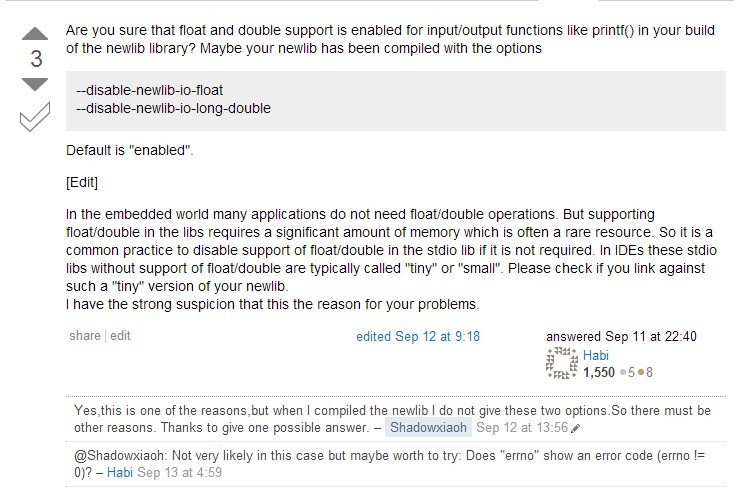
在C Interfaces and Implementations里也讲解了一种printf的实现,对标准C库的printf有一定的改进,代码是要讲可重用性和健壮性的,有兴趣可以看看。
好了,扪心自问一下,你真的懂printf么?
Sparse AutoEncoder简介
1. AutoEncoder
AutoEncoder是一种特殊的三层神经网络, 其输出等于输入:y(i)=x(i), 如下图所示:
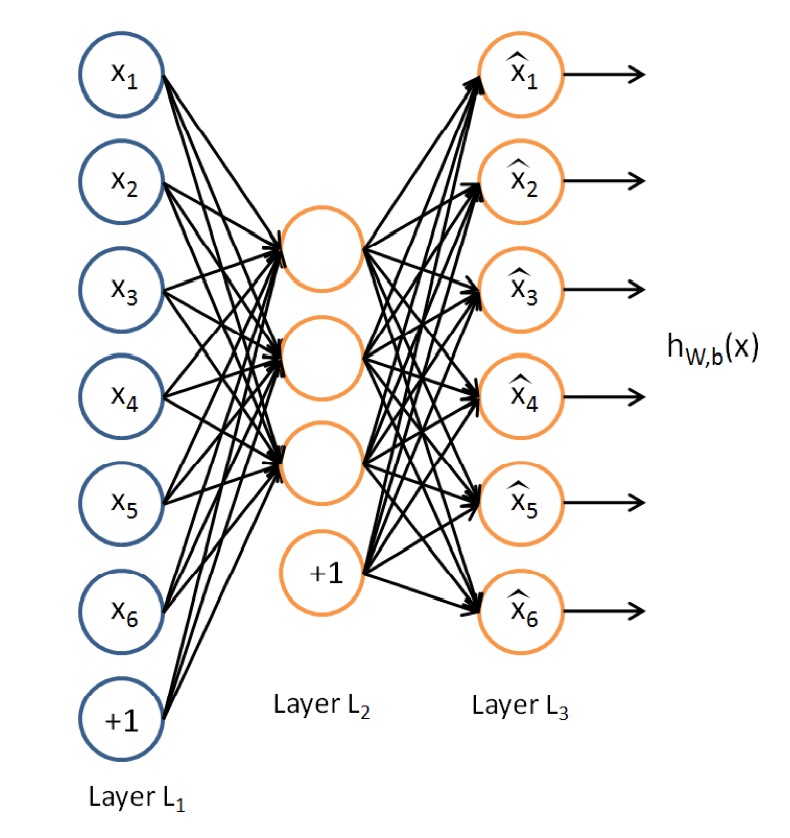
亦即AutoEncoder想学到的函数为fW,b≈x, 来使得输出x^比较接近x. 乍看上去学到的这种函数很平凡, 没啥用处, 实际上, 如果我们限制一下AutoEncoder的隐藏单元的个数小于输入特征的个数, 便可以学到数据的很多有趣的结构. 如果特征之间存在一定的相关性, 则AutoEncoder会发现这些相关性.
2. Sparse AutoEncoder
我们可以限制隐藏单元的个数来学到有用的特征, 或者可以对网络施加其他的限制条件, 而不限制隐藏单元的个数. 特别的, 我们可以对隐藏单元施加稀疏性限制. 具体的, 一个神经元是激活的当且仅当其输出值比较接近1, 一个神经元是不激活的当且仅当其输出值比较接近0. 我们可以限制神经元在大多数时间下都是不激活的(亦即Sparse Filtering中的Lifetime Sparsity概念).
定义a(2)j为AutoEncoder中隐藏单元的激活值, 我们形式化的定义如下的限制:
其中ρ是稀疏性参数, 一般取值为一个比较接近0的数, 比如0.05.
为了使得学到的AutoEncoder达到上述的稀疏性要求, 我们在优化目标里添加了新的一项, 用于惩罚那些偏离ρ太多的ρ^j. 可以使用KL Divergence:
上式可也以写作:
下图展示了KL Divergence的特性: ρ^j越接近ρ(此处为0.2), 则KL Divergence越小.
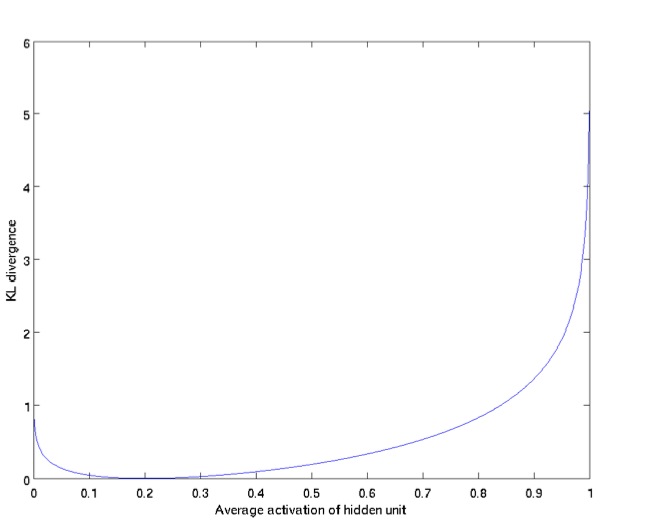
所以, Sparse AutoEncoder的损失函数为:
其中
添加KL Divergence后的cost function后的偏导数为:


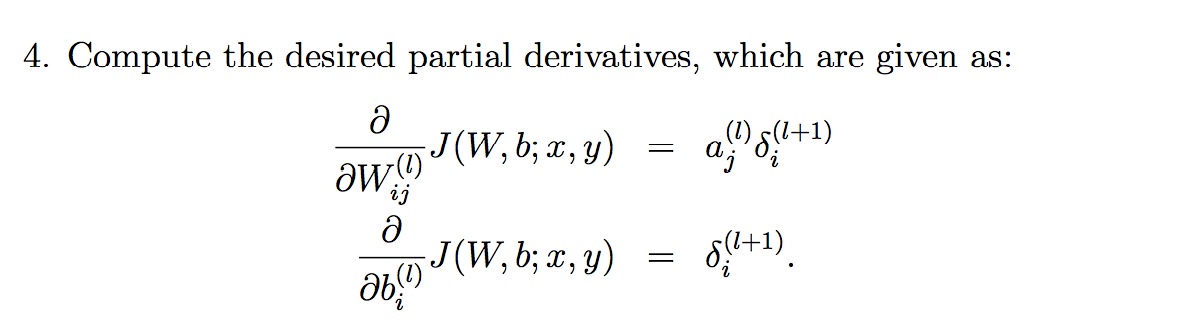
有个新的偏导数之后, 使用Back Propagation来优化整个神经网络:

参考文献:
[1]. Sparse AutoEncoder. Andrew Ng.
Api 和 Spi的更多相关文章
- JAVA—API和SPI概念
JAVA—API和SPI概念 目录 概念 JDBC实例 自己实现一个SPI 总结 概念英文: What is the difference between Service Provider Inter ...
- Java API 之 SPI机制
SPI SPI全称是service provider interface,是Java定义的一套服务发现机制,如图: 调用方只需要面向接口,接口的实现由第三方自己去实现,服务启动的时候会自动去发现该服务 ...
- IDEA+API && SPI
JAVA中API和SPI的区别:https://blog.csdn.net/quanaianzj/article/details/82500019
- API/SPI可扩展设计原则(转)
API/SPI可扩展设计原则 博客分类: [设计体系]架构模式 API/SPISPISPI原则JAVA SPISPI机制 写本篇主要是用来后面写一篇可扩展性软件设计打好基础(苦于找不到一篇关于API ...
- (转)Java API设计清单
转自: 伯乐在线 Java API设计清单 英文原文 TheAmiableAPI 在设计Java API的时候总是有很多不同的规范和考量.与任何复杂的事物一样,这项工作往往就是在考验我们思考的缜密程度 ...
- Magento2 API 服务合同设计模式 依赖注入 介绍
公共接口和API 什么是公共界面? 一个公共接口是一组代码,第三方开发者可以调用,实现或构建一个 插件 .Magento保证在没有重大版本更改的情况下,此代码在后续版本中不会更改. 模块的公共接口 标 ...
- Java扩展方法之SPI
API:API(Application Programming Interface)表示应用程序编程接口 SPI:SPI(Service Provider Interface)表示服务提供商接口 A ...
- Java:Spi 小实战
背景 Java 中区分 Api 和 Spi,通俗的讲:Api 和 Spi 都是相对的概念,他们的差别只在语义上,Api 直接被应用开发人员使用,Spi 被框架扩张人员使用,详细内容可以看:http:/ ...
- SPI子系统分析之四:驱动模块
内核版本:3.9.5 SPI控制器层(平台相关) 上一节讲了SPI核心层的注册和匹配函数,它是平台无关的.正是在核心层抽象了SPI控制器层的相同部分然后提供了统一的API给SPI设备层来使用.我们这一 ...
随机推荐
- oracle_constraint的用处
ql中constraint主要是增加约束 这个主要就是增加约束的 以下几种约束 .并 一一列举: 1.主键约束: 主键约束:就是对一个列进行了约束,约束为(非空.不重复)要对一个列加主键约束的话,这列 ...
- 无废话WCF入门教程三[WCF的宿主]
一.WCF服务应用程序与WCF服务库 我们在平时开发的过程中常用的项目类型有“WCF 服务应用程序”和“WCF服务库”. WCF服务应用程序,是一个可以执行的程序,它有独立的进程,WCF服务类契约的定 ...
- java_Eclipse主题颜色配置+全屏
http://www.eclipsecolorthemes.org/ 这个是主题的网站. 在Eclipse里, File->Import->General->Preferences- ...
- HDU 2612 -Find a way (注重细节BFS)
主题链接:Find a Way 题目不难,前几天做,当时准备写双向BFS的,后来处理细节上出了点问题,赶上点事搁置了.今天晚上重写的,没用双向,用了两次BFS搜索,和双向BFS 道理差点儿相同.仅仅是 ...
- Flex在使用无线电的button切换直方图横坐标和叙述性说明
1.问题叙述性说明 一组单选button,有周和月之分,选择"周",柱状图横坐标显示的是周,纵坐标显示的是人数:选择"月",柱状图横坐标显示的月,纵坐标显示的是 ...
- 初创互联网公司简明创业指南 - YC新掌门Sam Altman
本文只是一个创业指南的简明版 - 更详细的版本请查看:http://startupclass.samaltman.com 创业之前,你更应该去拥有一个好的创意,而不是一个公司.如果开始前你拥有一个好的 ...
- SQL常规查询详解
一.交叉连接(cross join) 交叉连接(cross join):有两种,显式的和隐式的,不带on子句,返回的是两表的乘积,也叫笛卡尔积. 例如:下面的语句1和语句2的结果是相同的. 语句1:隐 ...
- 机器学习学习-Types of learning
Types of learning 基于个人理解.于我们在面对一个详细的问题时.可以依据要达到的目标选择合适的机器学习算法来得到想要的结果.比方,推断一封电子邮件是否是垃圾邮件,就要使用分类(clas ...
- Java开发工具IntelliJ IDEA使用教程:创建新的Andriod项目
IntelliJ IDEA社区版作为一个轻量级的Java开发IDE,本身是一个开箱即用的Android开发工具. 注意:在本次的教程中我们将以Android平台2.2为例进行IntelliJ IDEA ...
- Vs2010中水晶报表引用及打包
原文:Vs2010中水晶报表引用及打包 转自:http://yunhaifeiwu.iteye.com/blog/1172283 Vs2010中水晶报表引用 在sap官网中下载支持vs 2010中的水 ...