项目架构开发:数据访问层之Query
上一章我们讲了IRepository接口,这张我们来讲IQuery
根据字面意思就可以知道,这次主要讲数据查询,上一章我们只针对单表做了查询的操作,多表联查并没有实现
其实对于任何一个项目来说,多表联查都是比较麻烦的地方,因为项目的“读”操作,特别是多表的“读”,至少占据所有“读”的一半以上
然而至今,据我所知还没有哪一款ORM工具可以灵活处理多表联查;想要不写sql语句,又想性能高,还想用强类型的ling查询方法;这对于多表查询来说比较难
鉴于此,也别做那些别扭的映射了(像NH),而如果用lingtosql我觉得还不如直接写sql来的好;
是开发人员不可能不懂sql,那对多表查询这一块,干脆独立一个Query类出来,专门处理这种事
好了这只是我的处理方式,我们来看看
IQuery.cs
public interface IQuery
{
T QuerySingle<T>(string sql, object paramPairs) where T : class;
IEnumerable<T> QueryList<T>(string sql, object paramPairs) where T : class; /// <summary>必须带上row_number() over({0}) RowNumber</summary>
Tuple<int, IEnumerable<T>> GetPage<T>(Page page, string sql, dynamic paramPairs = null) where T : class; Tuple<int, IEnumerable<T>> GetPage<T>(string sql, object paramPairs = null) where T : class;
int Execute(string sql, dynamic paramPairs = null);
long Count(string sql, dynamic paramPairs = null);
}
上方法名就可以知道,写sql,然后返回自定义的T或IEnumerable<T>
这里避免了用泛型类,因为某个实体大多数情况下可能也只是需要,上边其中其中的1、2个而已
这里有一个Execute方法,其实不应该放在这的,但是也懒得写另外一个类了,先放着吧
Query的实现
DapperQuery.cs
using Dapper;
using Dapper.Contrib.Extensions;
using LjrFramework.Common;
using LjrFramework.Interface;
using System;
using System.Collections.Generic;
using System.Data;
using System.Linq; namespace LjrFramework.Data.Dapper
{
public class DapperQuery : IQuery
{
protected IDbConnection Conn { get; private set; } public DapperQuery()
{
Conn = DbConnectionFactory.CreateDbConnection();
} public void SetDbConnection(IDbConnection conn)
{
Conn = conn;
} public T QuerySingle<T>(string sql, object paramPairs) where T : class
{
return Conn.Query<T>(sql, paramPairs).SingleOrDefault();
} public IEnumerable<T> QueryList<T>(string sql, object paramPairs) where T : class
{
return Conn.Query<T>(sql, paramPairs);
} /// <summary>自动分页,必须带上row_number() over({0}) RowNumber</summary>
public Tuple<int, IEnumerable<T>> GetPage<T>(Page page, string sql, object paramPairs = null) where T : class
{
var multi = Conn.GetPage<T>(page.PageIndex, page.PageSize, sql, paramPairs);
var count = multi.Read<int>().Single();
var results = multi.Read<T>();
return new Tuple<int, IEnumerable<T>>(count, results);
}
// 需自己实现分页语句
public Tuple<int, IEnumerable<T>> GetPage<T>(string sql, object paramPairs = null) where T : class
{
var multi = Conn.GetGridReader<T>(sql, paramPairs);
var count = multi.Read<int>().Single();
var results = multi.Read<T>();
return new Tuple<int, IEnumerable<T>>(count, results);
} public int Execute(string sql, object paramPairs = null)
{
return Conn.Execute(sql, paramPairs);
} public long Count(string sql, object paramPairs = null)
{
return Conn.Query<long>(sql, paramPairs).SingleOrDefault();
}
}
}
这个实现跟上一章差不多,都是直接调用Conn的扩展方法,
我们进去看看(public Tuple<int, IEnumerable<T>> GetPage<T>(string sql, object paramPairs = null) where T : class)的实现
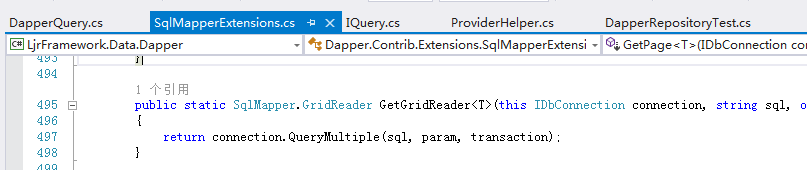
可以看到dapper是已经支持sql语句的查询,并且返回多个记录(SqlMapper.GridReader)
每次分页都要去手动刷选 页数 与 记录开始行数的话比较麻烦
所有我做了一点小改动,武学用户写分页语句,直接查询就可以了,后台会自动生成分页语句的格式
不过要带上row_number() over({0}) RowNumber;就是上边那个有注释的方法
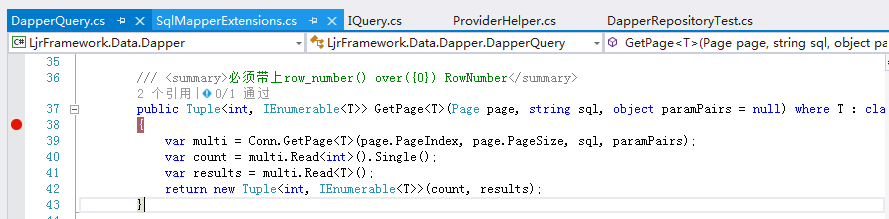
他的实现如下

这样用户只需要准守一点约束,就会方便很多
这些都是在dapper的Extensions里实现的,用户需要自行修改,自己想要的自定义的功能
好了,Query有效代码写完了,我们看看运行效果
Query测试
using Autofac;
using Company.Project.PO;
using LjrFramework.Data.Dapper;
using LjrFramework.Common;
using LjrFramework.Infrastructure;
using LjrFramework.Interface;
using Microsoft.VisualStudio.TestTools.UnitTesting;
using System;
using LjrFramework.Data.UnitOfWork; namespace LjrFramework.UnitTest
{
[TestClass]
public class QueryTest
{
private IQuery query; public QueryTest()
{
var builder = new ContainerBuilder();
builder.RegisterType<DapperQuery>().As<IQuery>(); var container = builder.Build();
query = container.Resolve<IQuery>(); } [TestMethod]
public void QuerySingle()
{
var model = query.QuerySingle<LoginUser>("select * from LoginUser where Id = @Id", new { Id = "854B1FCA-F8D7-4B4B-AA5D-9075F1922721" }); Assert.AreEqual(model.LoginName, "lanxiaoke-d318fd40-1b9d-42f8-a002-388b1228012d");
} [TestMethod]
public void QueryList()
{
var list = query.QueryList<LoginUser>("select * from LoginUser where LoginName like '%'+ @LoginName + '%'", new { LoginName = "lanxiaoke" }); int index = ;
foreach (var user in list)
{
index++;
} Assert.AreEqual(index > , true);
} [TestMethod]
public void GetPage()
{
var page = new Page()
{
PageIndex = ,
PageSize =
}; var results = query.GetPage<LoginUser>(page,
@"select row_number() over(order by CreateTime) RowNumber,* from LoginUser where LoginName like '%'+ @LoginName + '%'", new { LoginName = "lanxiaoke" }); var total = results.Item1;
var list = results.Item2; int index = ;
foreach (var user in list)
{
index++;
} Assert.AreEqual(index > , true);
} [TestMethod]
public void GetPage2()
{
var page = new Page()
{
PageIndex = ,
PageSize =
}; var results = query.GetPage<LoginUser>(
@"select count(*) as TotalCount from LoginUser c where LoginName like '%'+ @LoginName + '%'
select row_number() over(order by CreateTime) RowNumber,* from LoginUser where LoginName like '%'+ @LoginName + '%'",
new { LoginName = "lanxiaoke" }); var total = results.Item1;
var list = results.Item2; int index = ;
foreach (var user in list)
{
index++;
} Assert.AreEqual(index > , true);
} [TestMethod]
public void Count()
{
var row = query.Count("select count(*) from LoginUser"); Assert.AreEqual(row > , true);
} }
}
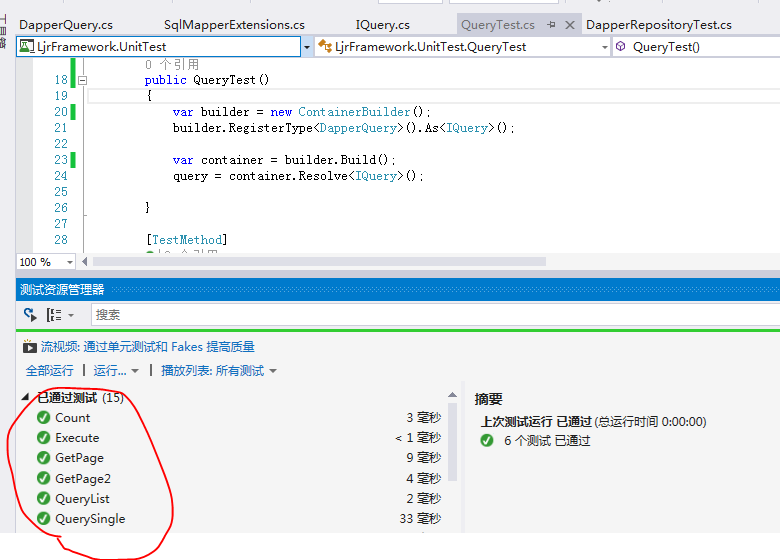
自此,多表查询就讲完了
项目架构开发系列
- 项目架构开发:数据访问层之Cache
- 项目架构开发:数据访问层之Logger
- 项目架构开发:数据访问层之Repository
- 项目架构开发:数据访问层之Query
- 项目架构开发:数据访问层之UnitOfWork
项目架构开发:数据访问层之Query的更多相关文章
- 企业级应用架构(三)三层架构之数据访问层的改进以及测试DOM的发布
在上一篇我们在宏观概要上对DAL层进行了封装与抽象.我们的目的主要有两个:第一,解除BLL层对DAL层的依赖,这一点我们通过定义接口做到了:第二,使我们的DAL层能够支持一切数据访问技术,如Ado.n ...
- 项目架构开发:数据访问层之Cache
数据访问层简单介绍 数据访问层,提供整个项目的数据访问与持久化功能.在分层系统中所有有关数据访问.检索.持久化的任务,最终都将在这一层完成. 来看一个比较经典的数据访问层结构图 大概可以看出如下信息 ...
- 项目架构开发:数据访问层之Logger
接上文 项目架构开发:数据访问层之Cache 本章我们继续ILogger的开发 ILogger.cs public interface ILogger { void Info(object messa ...
- 项目架构开发:数据访问层之Repository
接上文 项目架构开发:数据访问层之Logger 本章我们继续IRepository开发,这个仓储与领域模式里边的仓储有区别,更像一个工具类,也就是有些园友说的“伪仓储”, 这个仓储只实现单表的CURD ...
- 项目架构开发:数据访问层之UnitOfWork
接上文 项目架构开发:数据访问层之IQuery 本章我们继续IUnitOfWork的开发,从之前的IRepository接口中就可以看出,我们并没有处理单元事务, 数据CUD每次都是立即执行的,这样有 ...
- 随机获得MySQL数据库中100条数据方法 驾照题库项目 MVC架构 biz业务层的实现类 根据考试类型rand或order通过dao数据访问层接口得到数据库中100或全部数据
package com.swift.jztk.biz; import java.util.Collections; import java.util.Comparator; import java.u ...
- 数据访问层之Repository
数据访问层之Repository 接上文 项目架构开发:数据访问层之Logger 本章我们继续IRepository开发,这个仓储与领域模式里边的仓储有区别,更像一个工具类,也就是有些园友说的“伪 ...
- asp.net/wingtip/创建数据访问层
一. 什么是数据访问层 在wingtip项目中,数据访问层是对以下三者的总称:1. product类等数据相关的实体类(class)2. 数据库(database),对实体类成员的存储3. 上述二者的 ...
- servlet层调用biz业务层出现浏览器 500错误,解决方法 dao数据访问层 数据库Util工具类都可能出错 通过新建一个测试类复制代码逐步测试查找出最终出错原因
package com.swift.jztk.servlet; import java.io.IOException; import javax.servlet.ServletException; i ...
随机推荐
- linux环境下Vim的配置
原文链接:http://blog.chinaunix.net/uid-26826958-id-3272375.html (本文转自此链接中的部分内容,但做了适当修改) 安装vim命令:sudo ap ...
- 定制jackson的自定义序列化(null值的处理)
http://www.cnblogs.com/lic309/p/5048631.html
- main函数执行前、后再执行的代码
一.main结束 不代表整个进程结束 (1)全局对象的构造函数会在main 函数之前执行, 全局对象的析构函数会在main函数之后执行: 用atexit注册的函数 ...
- Intent对象详解——使用Intent启动系统组件
Android的应用程序包含三种重要组件:Activity.Service.BroadcastReceiver,应用程序采用一致的方式来启动它们——都是依靠Intent来启动的,Intent就封装了程 ...
- axure8.0注册码
激活码:(亲测可用) 用户名:aaa 注册码:2GQrt5XHYY7SBK/4b22Gm4Dh8alaR0/0k3gEN5h7FkVPIn8oG3uphlOeytIajxGU 用户名:axureuse ...
- Unity 容器教程
文章摘自: http://www.cnblogs.com/qqlin/archive/2012/10/18/2720830.html
- DailyTick 开发实录 —— UI 设计
上次的文章中描述了 DailyTick 的设计理念.经过两周左右的设计和开发,现在 DailyTick 的主要 UI 已经完成了原型的设计和初步的实现.既然是原型,当然看起来就有点粗糙. 主 UI 主 ...
- POJ2479(dp)
Maximum sum Time Limit: 1000MS Memory Limit: 65536K Total Submissions: 39089 Accepted: 12221 Des ...
- HDU4496(并查集)
D-City Time Limit: 2000/1000 MS (Java/Others) Memory Limit: 65535/65535 K (Java/Others)Total Subm ...
- HTML5 JavaScript API
W3C官方指定的HTML5规范已经修订了很多次,HTML5这个概念是与javascript API相捆绑的语义标记.在过去这些年中,HTML5这个词所指代的范围正以惊人的的速度膨胀,某种程度上已经成为 ...