利用Sharding-Jdbc实现分表
你们团队使用SpringMVC+Spring+JPA框架,快速开发了一个NB的系统,上线后客户订单跟雪花一样纷沓而来。
慢慢地,你的心情开始变差,因为客户和产品的抱怨越来越频繁,抱怨的最多的一个问题就是:系统越来越慢了。
1 常规优化
你组织团队,进行了一系列的优化。
1.1 数据表索引优化
经过初步分析,发现瓶颈在数据库。WEB服务器的CPU闲来无事,但数据库服务器的CPU使用率高居不下。
于是,请来架构组的DBA同事,监控数据库的访问,整理出那些耗时的SQL,并且进行SQL查询分析。根据分析结果,对数据表索引进行重新整理。同时也对数据库本身的参数设置进行了优化。
优化后,页面速度明显提升,客户抱怨减少,又过了一段时间的安逸日子。
1.2 多点部署+负载均衡
慢慢的,访问速度又不行了,这次是WEB服务器压力很大,数据库服务器相对空闲。经过分析,发现是系统并发用户数太多,单WEB服务器不能够支持如此众多的并发请求。
于是,请架构协助进行WEB多点部署,前端使用nginx做负载分发。这时候必须要解决的一个问题就是用户会话保持的问题。这可以有几种不同解决方案:
1、nginx实现sticky分发
因为nginx缺省没有sticky机制,可以使用ip_hash方式来代替。
2、配置Tomcat实现Session复制
3、代码使用SpringSession,利用redis实现session复制。
具体做法就不一一介绍了。其中使用SpringSession的方法,可以参考我的文章《集群环境CAS的问题及解决方案》。
2 试用当当的Sharding JDBC框架
多点部署之后,系统又运行了一段时间,期间增加了更多的WEB节点,基本能应对客户需求。慢慢的,增加WEB服务器也不能解决问题了,因为系统瓶颈又回到了数据库服务器。SQL执行时间越来越长,而且无法优化。原因也很简单,数据量太大。
单表数据已经超过几千万行,通过数据库的优化已经不能满足速度的要求。分库分表提到了日程上,必须解决。
因为使用了JPA,如果分库分表需要对数据访问层做较大的改动,工作量太大,修改的风险也太高。恰好看到当当开源了其Sharding-JDBC组件,摘抄一段介绍:
https://github.com/dangdangdotcom/sharding-jdbc
Sharding-JDBC直接封装JDBC API,可以理解为增强版的JDBC驱动,旧代码迁移成本几乎为零:
可适用于任何基于java的ORM框架,如:JPA, Hibernate, Mybatis, Spring JDBC Template或直接使用JDBC。
可基于任何第三方的数据库连接池,如:DBCP, C3P0, BoneCP, Druid等。
理论上可支持任意实现JDBC规范的数据库。虽然目前仅支持MySQL,但已有支持Oracle,SQLServer,DB2等数据库的计划。
它支持JPA,可以在几乎不修改代码的情况下完成分库分表的实现。因此,选择这个框架做一次分库分表的尝试。
先做一个最简单的试用,不做分库,仅做分表。选择数据表operate_history,这个数据表记录所有的操作历史,是整个系统中数据量最大的一个数据表。
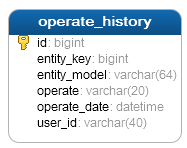
希望将这个表拆分为四个数据表,分别是 operate_history_0operate_history_1 operate_history_2 operate_history_3。数据能够分配保存到四个数据表中,降低单表的数据量。同时,为了尽量减少跨表的查询操作,决定使用字段 entity_key为分表依据,这样同一个entity对象的所有操作,将会记录在同一个数据表中。拆分后的数据表结构为:

3 实现过程
以下是针对JPA项目的修改过程。其他项目请参考官方网站的文档。
3.1 修改pom.xml增加dependency
需要添加两个jar,sharding-jdbc-core和sharding-jdbc-config-spring。
<dependency>
<groupId>com.dangdang</groupId>
<artifactId>sharding-jdbc-core</artifactId>
<version>1.3.0</version>
</dependency>
<dependency>
<groupId>com.dangdang</groupId>
<artifactId>sharding-jdbc-config-spring</artifactId>
<version>1.3.0</version>
</dependency>
3.2 修改Spring中Database部分的配置
原Database配置
<bean id="dataSource"class="org.apache.tomcat.jdbc.pool.DataSource"destroy-method="close">
<propertyname="driverClassName"value="com.mysql.jdbc.Driver"></property>
<propertyname="url" value="jdbc:mysql://localhost:3306/sharding"></property>
<propertyname="username" value="root"></property>
<propertyname="password" value="sharding"></property>
</bean>
修改后的配置
<beanid="db-node-0"class="org.apache.tomcat.jdbc.pool.DataSource"destroy-method="close">
<property name="driverClassName"value="com.mysql.jdbc.Driver"></property>
<property name="url"value="jdbc:mysql://localhost:3306/sharding"></property>
<property name="username"value="root"></property>
<property name="password"value="sharding"></property>
</bean>
<rdb:strategyid="historyTableStrategy"
sharding-columns="entity_key"
algorithm-class="cn.codestory.sharding.SingleKeyTableShardingAlgorithm"/>
<rdb:data-sourceid="dataSource">
<rdb:sharding-ruledata-sources="db-node-0"default-data-source="db-node-0">
<rdb:table-rules>
<rdb:table-rulelogic-table="operate_history"
actual-tables="operate_history_0,operate_history_1,operate_history_2,operate_history_3"
table-strategy="historyTableStrategy" />
</rdb:table-rules>
</rdb:sharding-rule>
</rdb:data-source>
3.3 编写类SingleKeyTableShardingAlgorithm
这个类用来根据entity_key值确定使用的分表名。参考sharding提供的示例代码进行修改。核心代码如下
publicCollection<String> doInSharding(
Collection<String>availableTargetNames,
ShardingValue<Long>shardingValue) {
int targetCount = availableTargetNames.size();
Collection<String> result = newLinkedHashSet<>(targetCount);
Collection<Long> values =shardingValue.getValues();
for (Long value : values) {
for (String tableNames :availableTargetNames) {
if (tableNames.endsWith(value % targetCount+ "")) {
result.add(tableNames);
}
}
}
return result;
}
这是一个简单的实现,对entity_key进行求模,用余数确定数据表名。
3.4 修改主键生成方法
因为数据分表保存,不能使用identify方式生成数据表主键。如果主键是String类型,可以考虑使用uuid生成方法,但它查询效率会相对比较低。
如果使用long型主键,可以使用其他方式,一定要确保各个子表中的主键不重复。
3.5 历史数据的处理
根据数据分表的规则,需要对原有数据包的数据进行迁移,分别移动到四个数据表中。如果不做这一步,或者数据迁移到了错误的数据表,后续将会查询不到这些数据。
至此,对项目的修改基本完成,重新启动项目并增加operate_history数据,就会看到新添加的数据,已经根据我们的分表规则,插入到了某一个数据表中。查询的时候,能够同时查询到多个实际数据表中的数据。
4 数据分表规则的一些考虑
前面的例子,演示的是根据entity_key进行分表,也可以使用其他字段如主键进行分表。以下是我想到的一些分表规则:
根据主键进行分配
这种方式能够实现最平均的分配方法,每生成一条新数据,会依次保存到下一个数据表中。
根据用户ID进行分配
这种方式能够确保同一个用户的所有数据保存在同一个数据表中。如果经常按用户id查询数据,这是比较经济的一种做法。
根据某一个外键的值进行分配
前面的例子采用的就是这种方法,因为这个数据可能会经常根据这个外键进行查询。
根据时间进行分配
适用于一些经常按时间段进行查询的数据,将一个时间段内的数据保存在同一个数据表中。比如订单系统,缺省查询一个月之内的数据。
利用Sharding-Jdbc实现分表的更多相关文章
- 利用ShardingSphere-JDBC实现分库分表
利用ShardingSphere-JDBC实现分库分表 1. ShardingSphere概述 1.1 概述 业务发展到一定程度,分库分表是一种必然的要求,分库可以实现资源隔离,分表则可以降低单表数据 ...
- 利用ShardingSphere-JDBC实现分库分表--配置中心的实现
在之前的文章中我详细描述了如何利用ShardingSphere-JDBC进行分库分表,同时也实现了简单的精确分库算法接口,详情见下面的链接: 利用ShardingSphere-JDBC实现分库分表 但 ...
- EFCore.Sharding(EFCore开源分表框架)
EFCore.Sharding(EFCore开源分表框架) 简介 引言 开始 准备 配置 使用 按时间自动分表 性能测试 其它简单操作(非Sharing) 总结 简介 本框架旨在为EF Core提供S ...
- 分布式事务-Sharding 数据库分库分表
Sharding (转)大型互联网站解决海量数据的常见策略 - - ITeye技术网站 阿里巴巴Cobar架构设计与实践 - 机械机电 - 道客巴巴 阿里分布式数据库服务原理与实践:沈询_文档下载 ...
- Sharding JDBC整合SpringBoot 2.x 和 MyBatis Plus 进行分库分表
Sharding JDBC整合SpringBoot 2.x 和 MyBatis Plus 进行分库分表 交易所流水表的单表数据量已经过亿,选用Sharding-JDBC进行分库分表.MyBatis-P ...
- sharding-jdbc之——分库分表实例
转载请注明出处:http://blog.csdn.net/l1028386804/article/details/79368021 一.概述 之前,我们介绍了利用Mycat进行分库分表操作,Mycat ...
- 采用Sharding-JDBC解决分库分表
源码:Sharding-JDBC(分库分表) 一.Sharding-JDBC介绍 1,介绍 Sharding-JDBC是当当网研发的开源分布式数据库中间件,从 3.0 开始Sharding-JDBC被 ...
- Sharding-jdbc实现分库分表
首先在pom文件中引入需要的依赖 <dependency> <groupId>io.shardingjdbc</groupId> <artifactId> ...
- sharding-jdbc结合mybatis实现分库分表功能
最近忙于项目已经好久几天没写博客了,前2篇文章我给大家介绍了搭建基础springMvc+mybatis的maven工程,这个简单框架已经可以对付一般的小型项目.但是我们实际项目中会碰到很多复杂的场景, ...
- mysql、oracle分库分表方案之sharding-jdbc使用(非demo示例)
选择开源核心组件的一个非常重要的考虑通常是社区活跃性,一旦项目团队无法进行自己后续维护和扩展的情况下更是如此. 至于为什么选择sharding-jdbc而不是Mycat,可以参考知乎讨论帖子https ...
随机推荐
- 重学hadoop技术
最近因为做了些和hadoop相关的项目(虽然主要是运维),但是这段经历让我对hadoop的实际运用有了更加深入的理解. 相比以前自学hadoop,因为没有实战场景以及良好的大数据学习氛围,现在回顾下的 ...
- 是时候搁置Grunt,耍一耍gulp了
也算是用了半年Grunt,几个月前也写过一篇它的入门文章(点此查看),不得不说它是前端项目的一个得力助手.不过技术工具跟语言一样日新月异,总会有更好用的新的东西把旧的拍死在沙滩上(当然Grunt肯定没 ...
- .NET里简易实现IoC
.NET里简易实现IoC 前言 在前面的篇幅中对依赖倒置原则和IoC框架的使用只是做了个简单的介绍,并没有很详细的去演示,可能有的朋友还是区分不了依赖倒置.依赖注入.控制反转这几个名词,或许知道的也只 ...
- ABP源码分析二十四:Notification
NotificationDefinition: 用于封装Notification Definnition 的信息.注意和Notification 的区别,如果把Notification看成是具体的消息 ...
- Enterprise Solution 企业资源计划管理软件 C/S架构,支持64位系统,企业全面应用集成,制造业信息化
Enterprise Solution是一套完整的企业资源计划系统,功能符合众多制造业客户要求.系统以.NET Framework技术作为开发架构,完善的功能可有效地帮助企业进行运营策划,减低成本,如 ...
- [OAuth]基于DotNetOpenAuth实现Client Credentials Grant
Client Credentials Grant是指直接由Client向Authorization Server请求access token,无需用户(Resource Owner)的授权.比如我们提 ...
- 2、摘要函数——MD2/MD4/MD5数字签名
摘要是用来防止数据被私自改动的方法,其中用到的函数叫做摘要函数.这些函数的输入可以是任意大小的信息,但是输出是大小固定的摘要.摘要有个重要的特性:如果改变了输入信息的任何内容,即使改变一位,输出也将发 ...
- OpenCASCADE Job - Shoe Doctor
鞋博士 鞋博士经过8年沉淀,在鞋类工业4.0全流程平台上积累了相当的技术实力,获投资商亲睐. 新的一年,在投资商协助下,将踏上新的征途,因此诚邀您加盟顶层技术合伙人. 如果您具备以下实力,我们期待您的 ...
- MVC5 网站开发之六 管理员 2、添加、删除、重置密码、修改密码、列表浏览
目录 奔跑吧,代码小哥! MVC5网站开发之一 总体概述 MVC5 网站开发之二 创建项目 MVC5 网站开发之三 数据存储层功能实现 MVC5 网站开发之四 业务逻辑层的架构和基本功能 MVC5 网 ...
- [SQL] SQL 基础知识梳理(四) - 数据更新
SQL 基础知识梳理(四) - 数据更新 [博主]反骨仔 [原文]http://www.cnblogs.com/liqingwen/p/5929786.html 序 这是<SQL 基础知识梳理( ...