在Scrapy项目【内外】使用scrapy shell命令抓取 某网站首页的初步情况
Windows 10家庭中文版,Python 3.6.3,Scrapy 1.5.0,
时隔一月,再次玩Scrapy项目,希望这次可以玩的更进一步。
本文展示使用在 Scrapy项目内、项目外scrapy shell命令抓取知乎首页的初步情况,重要的一点是,在项目内抓取时,没有response可用。
在项目【外】执行抓取命令
scrapy shell https://www.zhihu.com
得到结果(部分):因为知乎的反爬虫功能,得到了400错误,访问失败。
INFO: Overridden settings: {'DUPEFILTER_CLASS': 'scrapy.dupefilters.BaseDupeFilter', 'LOGSTATS_INTERVAL': 0}
[]
2018-08-20 09:11:54 [scrapy.extensions.telnet] DEBUG: Telnet console listening on 127.0.0.1:6023
2018-08-20 09:11:54 [scrapy.core.engine] INFO: Spider opened
2018-08-20 09:11:59 [scrapy.core.engine] DEBUG: Crawled (400) <GET https://www.zhihu.com> (referer: None)
可用对象如下图:存在response!

在项目【内】执行抓取命令
scrapy shell https://www.zhihu.com
注意,项目使用scrapy startproject命令创建,已经在其settings.py中添加了USER_AGENT配置项。
得到结果(部分):多了很多内容,还包括USER_AGENT设置。最后服务器返回200,表示页面访问成功。
INFO: Overridden settings: {'BOT_NAME': 'newssci', 'DUPEFILTER_CLASS': 'scrapy.dupefilters.BaseDupeFilter', 'LOGSTATS_INTERVAL': 0, 'NEWSPIDER_MODULE': 'newssci.spiders', 'ROBOTSTXT_OBEY': True, 'SPIDER_MODULES': ['newssci.spiders'], 'USER_AGENT': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.99 Safari/537.36-480'}
[]
2018-08-20 09:12:23 [scrapy.extensions.telnet] DEBUG: Telnet console listening on 127.0.0.1:6023
2018-08-20 09:12:23 [scrapy.core.engine] INFO: Spider opened
2018-08-20 09:12:24 [scrapy.core.engine] DEBUG: Crawled (200) <GET https://www.zhihu.com/robots.txt> (referer: None)
2018-08-20 09:12:24 [scrapy.downloadermiddlewares.robotstxt] DEBUG: Forbidden by robots.txt: <GET https://www.zhihu.com>
可用对象如下图:没有response对象!还少了spider对象!
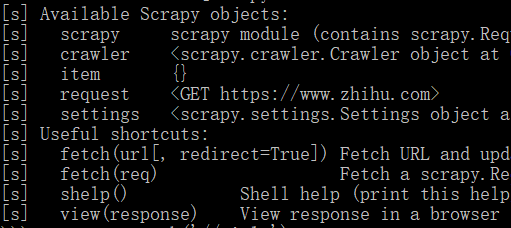
没有response对象,感觉什么也做不了了,网页也无法分析了。
总结
看来,还是需要到 项目外 使用scrapy shell命令来对网页做分析才是。不过,对于这种反爬虫的网站,在命令中添加上USER_AGENT配置项,然后就可以用response来做分析了。
项目外添加USER_AGENT配置项的命令如下:-s
scrapy shell -s USER_AGENT="Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.99 Safari/537.36-480" https://www.zhihu.com
结果如下:发生了一次重定向,所以有302。
INFO: Overridden settings: {'DUPEFILTER_CLASS': 'scrapy.dupefilters.BaseDupeFilter', 'LOGSTATS_INTERVAL': 0, 'USER_AGENT': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.99 Safari/537.36-480'}
[scrapy.downloadermiddlewares.redirect] DEBUG: Redirecting (302) to <GET https://www.zhihu.com/signup?next=%2F> from <GET https://www.zhihu.com>
[scrapy.core.engine] DEBUG: Crawled (200) <GET https://www.zhihu.com/signup?next=%2F> (referer: None)
发现了response对象可用:指明是针对其后的那个200网址的
[s] response <200 https://www.zhihu.com/signup?next=%2F>
使用response对象:获取页面title成功!
>>> response.xpath('//title/text()')
[<Selector xpath='//title/text()' data='知乎 - 发现更大的世界'>]
在Scrapy项目【内外】使用scrapy shell命令抓取 某网站首页的初步情况的更多相关文章
- Shell 命令行统计 apache 网站日志访问IP以及IP归属地
Shell 命令行统计 apache 网站日志访问IP以及IP归属地 我的一个站点用 apache 服务跑着,积攒了很多的日志.我想用 shell 看看有哪些人访问过我的站点,并且他来自哪里. 因为日 ...
- Scrapy爬虫框架教程(四)-- 抓取AJAX异步加载网页
欢迎关注博主主页,学习python视频资源,还有大量免费python经典文章 sklearn实战-乳腺癌细胞数据挖掘 https://study.163.com/course/introduction ...
- android adb命令 抓取系统各种 log
getLog.bat: adb root adb remount adb wait-for-device adb logcat -v time > C:\log.txt 在Android中不同的 ...
- Shell脚本 | 抓取log文件
在安卓应用的测试过程中,遇到 Crash 或者 ANR 后,想必大家都会通过 adb logcat 命令来抓取日志定位问题.如果直接使用 logcat 命令的话,默认抓取出的 log 文件包含安卓运行 ...
- 重构后的程序:通过rsync命令抓取日志文件
push.sh #!/bin/bash function push() { local ip=$ local user=$ local password=$ local path=$ local lo ...
- 重构前的程序:通过rsync命令抓取日志文件
基本概况: 我有一台服务器每天每个小时都会生成一个日志文件,这些日志文件会被保留2天,超过2天会被一个程序压缩放到备份目录,日志文件的文件名是有命名要求的,例如:project_log.2013010 ...
- shell爬虫--抓取某在线文档所有页面
在线教程一般像流水线一样,页面有上一页下一页的按钮,因此,可以利用shell写一个爬虫读取下一页链接地址,配合wget将教程所有内容抓取. 以postgresql中文网为例.下面是实例代码 #!/bi ...
- shell脚本抓取网页信息
利用shell脚本分析网站数据 # define url time=$(date +%F) mtime=$(date +%T) file=/abc/shell/abc/abc_$time.log ht ...
- git 常用命令--抓取分支-为自己记录(二)
二:抓取分支: 多人协作时,大家都会往master分支上推送各自的修改.现在我们可以模拟另外一个同事,可以在另一台电脑上(注意要把SSH key添加到github上)或者同一台电脑上另外一个目录克隆, ...
随机推荐
- MT【178】平移不变性
(2008年北大自招)已知$a_1,a_2,a_3;b_1,b_2,b_3$满足$a_1+a_2+a_3=b_1+b_2+b_3$$a_1a_2+a_2a_3+a_3a_1=b_1b_2+b_2b_3 ...
- mysql8.0+修改用户密码
查看初始安装密码登陆: [root@VM_133_71_centos yum.repos.d]# cat /var/log/mysqld.log|grep 'A temporary password' ...
- 修改docker镜像和容器的存放路径
默认情况下,镜像和容器存放的路径是/var/lib/docker. 要修改这个设置很简单,把指定的目录软链到这个目录,或者将一个单独的分区挂载到这个目录,或者直接修改docker启动参数. 查看使用帮 ...
- list All elements are null引起的异常
ArrayList允许添加null值,就容易造成了list内的对象转换出现java.lang.NullPointerException异常. 场景: 数据库 select min(id) as id ...
- bug找到吐的赶脚
bug找到吐的赶脚,真**刺激 一.单元测试 设计思路 首先是需要写一个无括号四则运算函数 下面的运算先是运算括号内的数 然后将null后置 全部代码测试,覆盖率92.4% 二.结构优化 uml图 流 ...
- 虚拟机中liunx安装教程
目标:在Linux服务器上部署Java开发的网站 工具 VirtualBox-4.3.8:下载后安装. linux系统镜像: Centos国内镜像文件下载地址: http://centos.ustc ...
- python高级特性和高阶函数
python高级特性 1.集合的推导式 列表推导式,使用一句表达式构造一个新列表,可包含过滤.转换等操作. 语法:[exp for item in collection if codition] if ...
- nginx 重写URL尾部斜杠
1. 在URL结尾添加斜杠 在虚拟主机中这么添加一条改写规则: rewrite ^(.*[^/])$ $1/ permanent;或者rewrite ^([/\w-_]*[^/])$ $1/ perm ...
- 网络编程之tcp窗口滑动以及拥塞控制
TCP协议作为一个可靠的面向流的传输协议,其可靠性和流量控制由滑动窗口协议保证,而拥塞控制则由控制窗口结合一系列的控制算法实现.一.滑动窗口协议 关于这部分自己不晓得怎么叙述才好,因为理解的部 ...
- livereload使用方法
搞这个自动刷新的插件搞了好几个小时了还没搞明白,快被气死了,想改用browser-sync结果npm又一直转啊转一直卡死. 刚才终于神奇地搞定了,结果发现还是我自己智商太低...大概的经过是这样的.. ...