Bagging(R语言实现)—包外错误率,多样性测度
1. Bagging
Bagging即套袋法,其算法过程如下:
从原始样本集中抽取训练集。每轮从原始样本集中使用Bootstraping的方法抽取n个训练样本(在训练集中,有些样本可能被多次抽取到,而有些样本可能一次都没有被抽中)。共进行k轮抽取,得到k个训练集。(k个训练集之间是相互独立的)
每次使用一个训练集得到一个模型,k个训练集共得到k个模型。(注:这里并没有具体的分类算法或回归方法,我们可以根据具体问题采用不同的分类或回归方法,如决策树、感知器等)
对分类问题:将上步得到的k个模型采用投票的方式得到分类结果;对回归问题,计算上述模型的均值作为最后的结果。(所有模型的重要性相同)
2. 算法设计过程
1.
2.
2.1. 随机采样方法
样本总数150条(Iris数据集)
抽样方法是有放回随机抽样。对150个样本的数据集,进行150次又放回随机采样,这样得到具有和原样本空间同等大小的样本集。
这样操作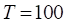 次,得到训练样本。33个用决策树C50,34个朴素贝叶斯,33个用KNN。
次,得到训练样本。33个用决策树C50,34个朴素贝叶斯,33个用KNN。
2.2. 模型评价方法
2.2.1. 包外错误率
由抽样方法可知,每次抽样大约有36.8%的数据未被抽到,这36.8%将作为包外数据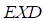 ,包外错误率:
,包外错误率:
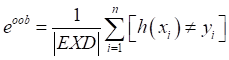
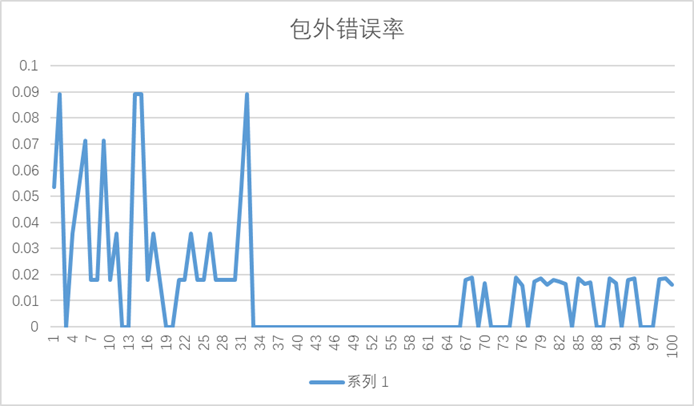
图 1 包外错误率
2.2.2. 成对多样性度量
a->两个个体学习器对同一条数据(h1=h2=Class),分类都与原数据集分类相同的总和
b->两个个体学习器对同一条数据(h1=class,h2!=Class)
c->两个个体学习器对同一条数据(h1!=class,h2=Class)
d->两个个体学习器对同一条数据(h1!=class,h2!=Class),分类都与原数据集分类都不相同的总和
K统计量
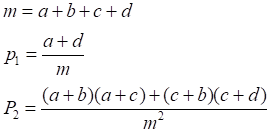
Q统计量
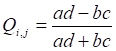
相关系数
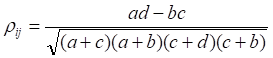
不一致度量
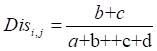
表1两个分类器的分类结果组合情况
|
|
|
|
|
|
|
|
|
|
|
|
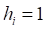

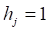
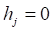
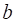
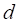
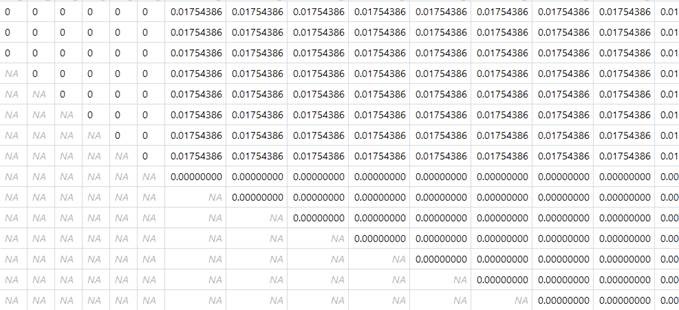
图2 多样性度量矩阵
2.3. 伪代码
|
输入: 输出: |
|
过程: for i to T
end for i to T for j=i+1 to T 统计a,b,c,d 计算
end end |
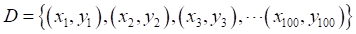 ,弱分类器迭代次数T=100,弱分类器B
,弱分类器迭代次数T=100,弱分类器B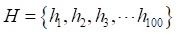 %集成学习器
%集成学习器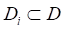 %Bagging采样,总共T次
%Bagging采样,总共T次 %获得包外测试集
%获得包外测试集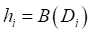 %学习器训练得到个体学习器
%学习器训练得到个体学习器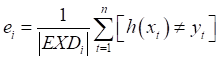 %包外错误率
%包外错误率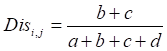
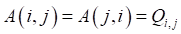 %多样性测度矩阵
%多样性测度矩阵3. 附录
数据集简介:
表2 iris
|
sepal length |
萼片长度 |
sepal width |
萼片宽度 |
petal length |
花瓣长度 |
petal width |
花瓣宽度 |
|
Class |
Iris-setosa -> 1 Iris-versicolor -> 2 Iris-virginica-> 3 |
R语言中的坑
第一次用R语言
例如
testData<-read.csv("G:\\testData.csv", header = FALSE)
将数据集导入之后 调用相关KNN NavieBayes等函数无法成功 原因是在导入的时候 数据集的class列 被自动转换成了整型(int)
tempTrain[,nc]<-as.factor(tempTrain[,nc])
调用as.factor()将class转换为因子 就可解决
还有 代码重复利用率低的问题 在下一次更新代码之中 可以解决
感谢大家批评指正
源代码(R):https://github.com/arlenlee/dataMining
Bagging(R语言实现)—包外错误率,多样性测度的更多相关文章
- R语言 ggplot2包
R语言 ggplot2包的学习 分析数据要做的第一件事情,就是观察它.对于每个变量,哪些值是最常见的?值域是大是小?是否有异常观测? ggplot2图形之基本语法: ggplot2的核心理念是将 ...
- R语言-神经网络包RSNNS
code{white-space: pre;} pre:not([class]) { background-color: white; }if (window.hljs && docu ...
- R语言-Knitr包的详细使用说明
R语言-Knitr包的详细使用说明 by 扬眉剑 来自数盟[总舵] 群:321311420 1.相关资料 1:自动化报告-谢益辉 https://github.com/yihui/r-ninja/bl ...
- R语言dplyr包初探
昨天学了一下R语言dplyr包,处理数据框还是很好用的.记录一下免得我忘记了... 先写一篇入门的,以后有空再写一篇详细的用法. #dplyr learning library(dplyr) #fil ...
- R语言扩展包dplyr——数据清洗和整理
R语言扩展包dplyr——数据清洗和整理 标签: 数据R语言数据清洗数据整理 2015-01-22 18:04 7357人阅读 评论(0) 收藏 举报 分类: R Programming(11) ...
- 安装R语言的包的方法
安装R语言的包的方法: 1. 在线安装 在R的控制台,输入类似install.packages("TSA") # 安装 TSA install.packages("TS ...
- R语言常用包汇总
转载于:https://blog.csdn.net/sinat_26917383/article/details/50651464?locationNum=2&fps=1 一.一些函数包大汇总 ...
- R语言扩展包dplyr笔记
引言 2014年刚到, 就在 Feedly 订阅里看到 RStudio Blog 介绍 dplyr 包已发布 (Introducing dplyr), 此包将原本 plyr 包中的 ddply() 等 ...
- R语言 arules包 apriori()函数中文帮助文档(中英文对照)
apriori(arules) apriori()所属R语言包:arules Mining Associations w ...
随机推荐
- HCTF2018 pwn题复现
相关文件位置 https://gitee.com/hac425/blog_data/tree/master/hctf2018 the_end 程序功能为,首先 打印出 libc 的地址, 然后可以允许 ...
- 2018-10-17 22:20:39 c language
2018-10-17 22:20:39 c language C语言中的空白符 空格.制表符.换行符等统称为空白符,它们只用来占位,并没有实际的内容,也显示不出具体的字符. 制表符分为水平制表符和垂 ...
- PC客户端开发细节记录:保存GUID到VARIANT
有两个 API 可以实现保存 GUID 到 VARIANT InitVariantFromGUIDAsBuffer 以字节数组形式保存,保存类型为 VT_ARRAY | VT_UI1,相当于字节拷贝, ...
- python websocket client 使用
import websocket ws = websocket.WebSocket() ws.connect("xx.xx.xx") ws.send("string&qu ...
- EmEditor的一个好用的正则替换功能
最近在编辑文本的时候用到了EmEditor的一个好用的正则替换功能.即我想用搜索到内容的一部分来生成另一段文本.例如客户提供给我一大堆MYSQL的建立主键的脚本,我想改成MSSQL的建立主键的脚本,这 ...
- MySQL 支持utf8mb4
utf8mb4 utf8mb3 utf8 Refer to The utf8mb4 Character Set The utf8 Character Set (Alias for utf8mb3) M ...
- PowerShell “execution of scripts is disabled on this system.”
Set-ExecutionPolicy RemoteSigned
- 修改TEMPDB所在的路径
USE master go ALTER DATABASE tempdb MODIFY FILE (NAME = tempdev, FILENAME = 'Path\tempdb.mdf') go AL ...
- 给SVN设置代理
XP系统在C:\Documents and Settings\Administrator\Application Data\Subversion目录下 win7及以上系统在C:\Users\admin ...
- C#中单问号(?)和双问号(??)的用法整理
1.单问号(?) 1.1 表示Nullable类型 C#2.0里面实现了Nullable数据类型 //A.比如下面一句,直接定义int为null是错误的,错误提示为无法将null转化成int,因为后者 ...